汇编
汇编
汇编基础
二进制与十六进制
十六进制相当于二进制的简写,可以看成二进制的另一种形式
| 二进制 | 十六进制 |
|---|---|
| 0000 | 0 |
| 0001 | 1 |
| 0010 | 2 |
| 0011 | 3 |
| 0100 | 4 |
| 0101 | 5 |
| 0110 | 6 |
| 0111 | 7 |
| 1000 | 8 |
| 1001 | 9 |
| 1010 | A |
| 1011 | B |
| 1100 | C |
| 1101 | D |
| 1110 | E |
| 1111 | F |
数据宽度
数据宽度
数学上的数字,是没有大小限制的,可以无限的大。但在计算机中,由于受硬件的制约,数据都是有长度限制的(称为数据宽度),超过最多宽度的数据会被丢弃
计算机中常见的数据宽度
(1)位(BIT) 在计算机中存储数据的最小单位 能存一个1或一个0
(2)字节(Byte) 一个字节能存储8个0或1 范围从0000000011111111 即00xFF
(3)字(Word) 能存16个0或1 0~0xFFFF
(4)双字(Doubleword) 存储32个0或1 0~0xFFFFFFFF
如果要存储的数据超过最大宽度,那么多余的数据将被丢弃
无符号数
无符号数的编码规则:数是多少就存多少
1001 1010 => 9A
有符号数的编码规则:最高位是0,则该数为正数;最高位是1,则该数为负数
当该数为正时,编码规则与无符号数相同
原码,反码,补码
正数:
原码:最高位为0,其余位为数值本身
反码:正数的反码与原码相同
补码:正数的补码与原码相同
6: 0000 0110
负数:
原码:最高位是1,其余位为数值本身的绝对值
-7: 1000 0111
反码:除最高位,其他位1变0,0变1(除最高位取反)
-7: 1111 1000
补码:负数的补码为反码+1
-7: 1111 1001
假设数据宽度为1BYTE(8BIT)
无符号数:0 1 2 3 4 ………… FF(10进制255)
有符号数:
正数:0 ……7F
负数:FF……80
假设数据宽度为Doubleword(32BIT)
无符号数:0 1 2 3 4 …… FFFFFFFF
有符号数:
正数:0 …… 7FFFFFFF
负数:FFFFFFFF …… 80000000
计算机如何运算 => 位运算
计算机只认识0和1,计算机只能对0和1做运算(通常称为位运算)
1.与运算
当两个位都为1时,结果才为1 比如:
1011 0001
and(&) 1101 1000
———————————-
1001 0000
2.或运算
只要有一个为1就是1
1011 0001
or(|) 1101 1000
———————————-
1111 1001
3.异或运算
不一样的时候是1
1011 0001
xor(^) 1101 1000
———————————-
0110 1001
4.非运算
0就是1 1就是0
not(~) 1101 1000
———————————-
0010 0111
5.左移
各二进位全部左移若干位,高位丢弃,低位补0
shl(<<) 1101 1000 左移2位为:0110 0000
6.右移
各二进位全部右移若干位,低位丢弃,高位补0或者补符号位
shr
1101 0101 =右移2位> 0011 0101
对应C语言(>>)
1 | unsigned int a = 10; |
sar
1101 0101 => 1111 0101
对应C语言(>>)
1 | int a = 10; |
通过位运算实现四则运算
加
如:4+5的运算过程
1)异或
0000 0100
0000 0101
异或———————
0000 0001
2)判断是否有进位
0000 0100
0000 0101
与————————
0000 0100
3)进位不为零 => 左移
0000 0100
左移———————-
0000 1000
4)异或 => 将第一次异或的值与进位后得到的值再异或
0000 0001
0000 1000
异或———————-
0000 1001
5)判断是否有进位
0000 0001
0000 1000
与————————
0000 0000
没有进位,就是加的结果
减
4-5的运算过程
4-5即4+(-5)
1)异或
0000 0100
1111 1011
异或———————-
1111 1111
2)判断是否有进位
0000 0100
1111 1011
与————————
0000 0000
所以4-5的结果就为1111 1111 = FF = -1
乘
X * Y 即X个Y相加
除
X / Y 本质为减法 X能减去多少个Y
汇编
1.寄存器
存储数据 CPU > 内存 > 硬盘
32位CPU:8 16 32
64位CPU:8 16 32 64
2.通用寄存器
32位寄存器:
EAX
ECX
EDX
EBX
ESP
EBP
ESI
EDI
3.MOV指令
(1)MOV立即数到寄存器
1 | mov eax, 1 |
MOV寄存器到寄存器(将eax存的值赋值到ebx)
1 | mov ebx, eax |
4.16位寄存器,8位寄存器





| 通用寄存器 | ||
|---|---|---|
| 32位 | 16位 | 8位 |
| EAX | AX | AL |
| ECX | CX | CL |
| EDX | DX | DL |
| EBX | BX | BL |
| ESP | SP | AH |
| EBP | BP | CH |
| ESI | SI | DH |
| EDI | DI | BH |
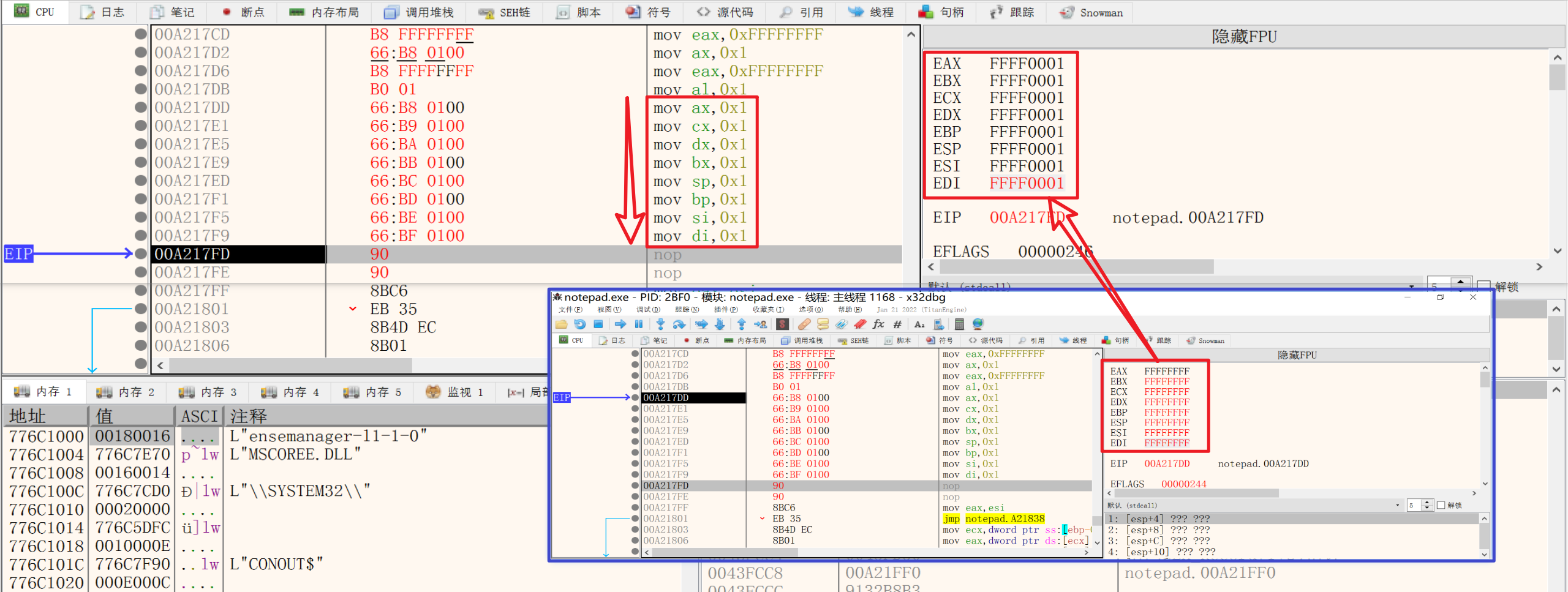
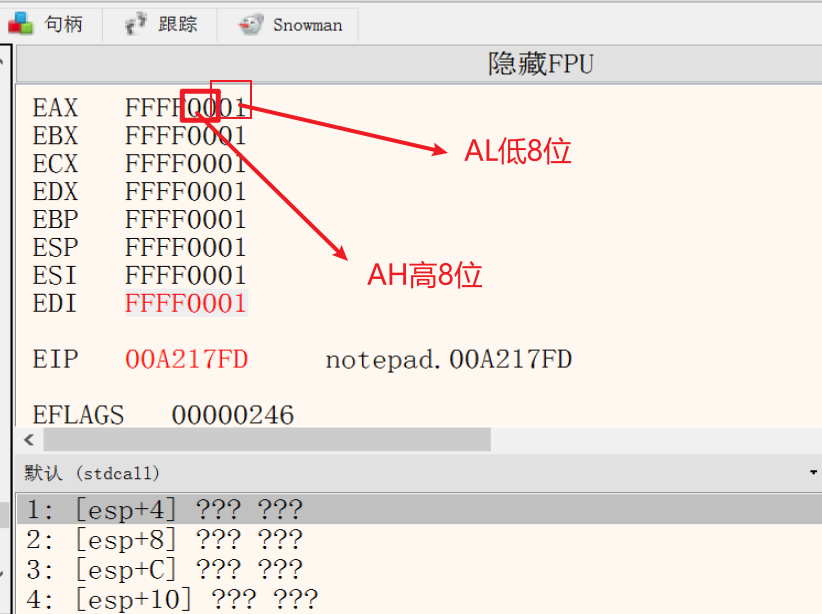
8位寄存器
5.内存
1.每个应用层序都会有自己的独立的4GB内存空间
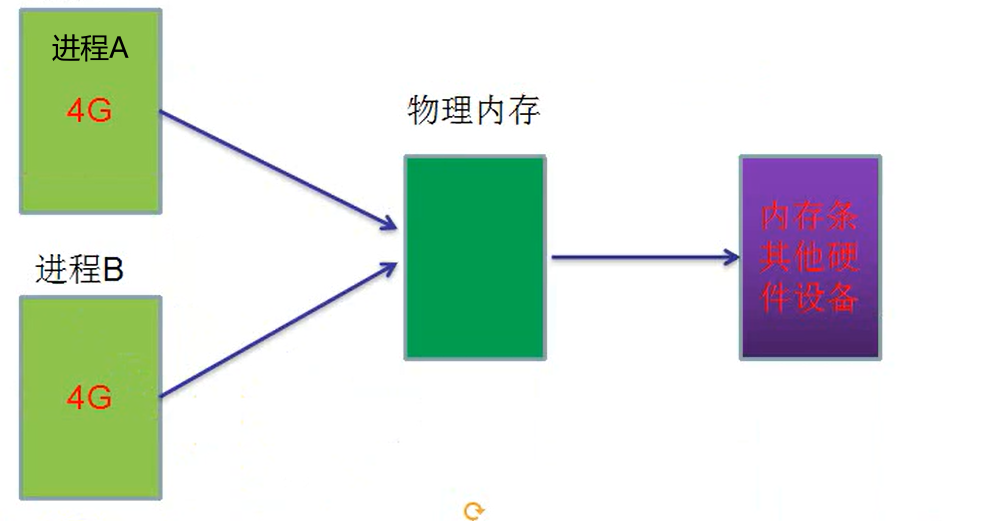
2.内存地址
(1)内存太大没法起名字,所以只能用编号。当我们想要向内存中存储数据,或者从内存读取数据时,必须用到这个编号。
(2)这个编号又称为内存地址(32位,前面0可以省略)[0x00000000]
使用内存
1.存立即数到内存
ptr ds:[ ] 里面写地址编号
地址和通用寄存器不一样,每个应用程序有4GB的内存,但是使用内存之前要先申请,不是可以随便用,
1 | mov byte ptr ds:[0xFFFFFFFF], 1 |
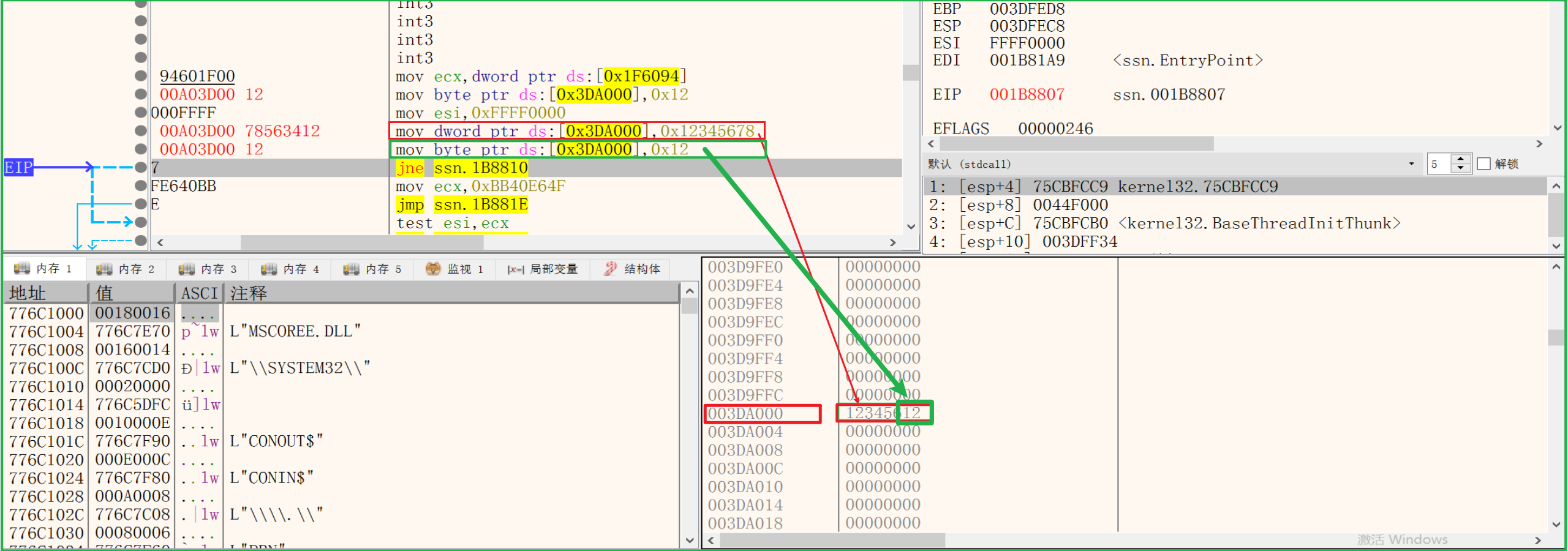
指令中的byte是数据大小,byte只有1字节,如果要写满数据,需要使用双字宽度dword,占4字节
使用word,可以存储2字节
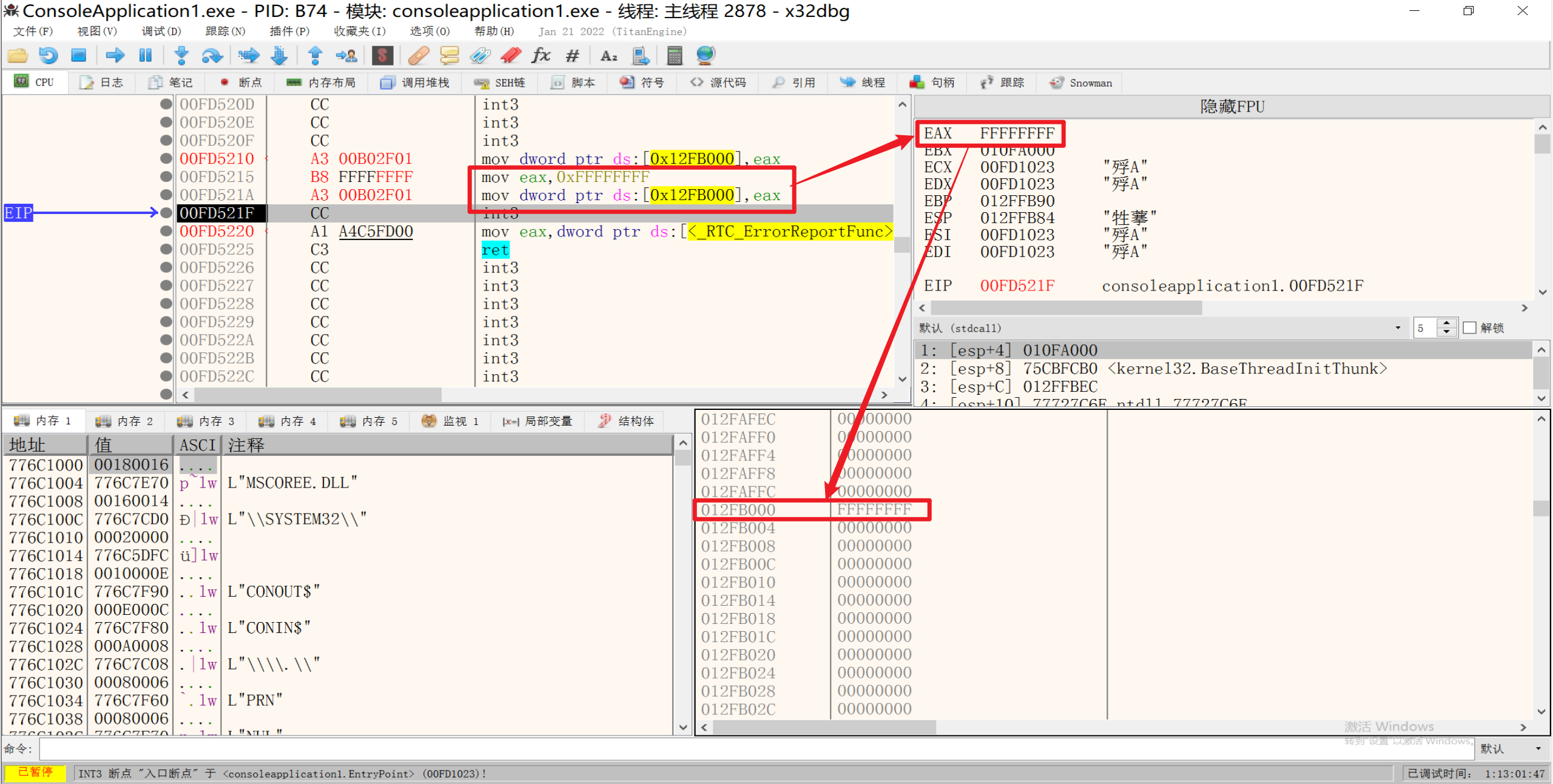
2.将寄存器中的值到内存
1 | mov dword ptr ds:[0x012FB000], eax |
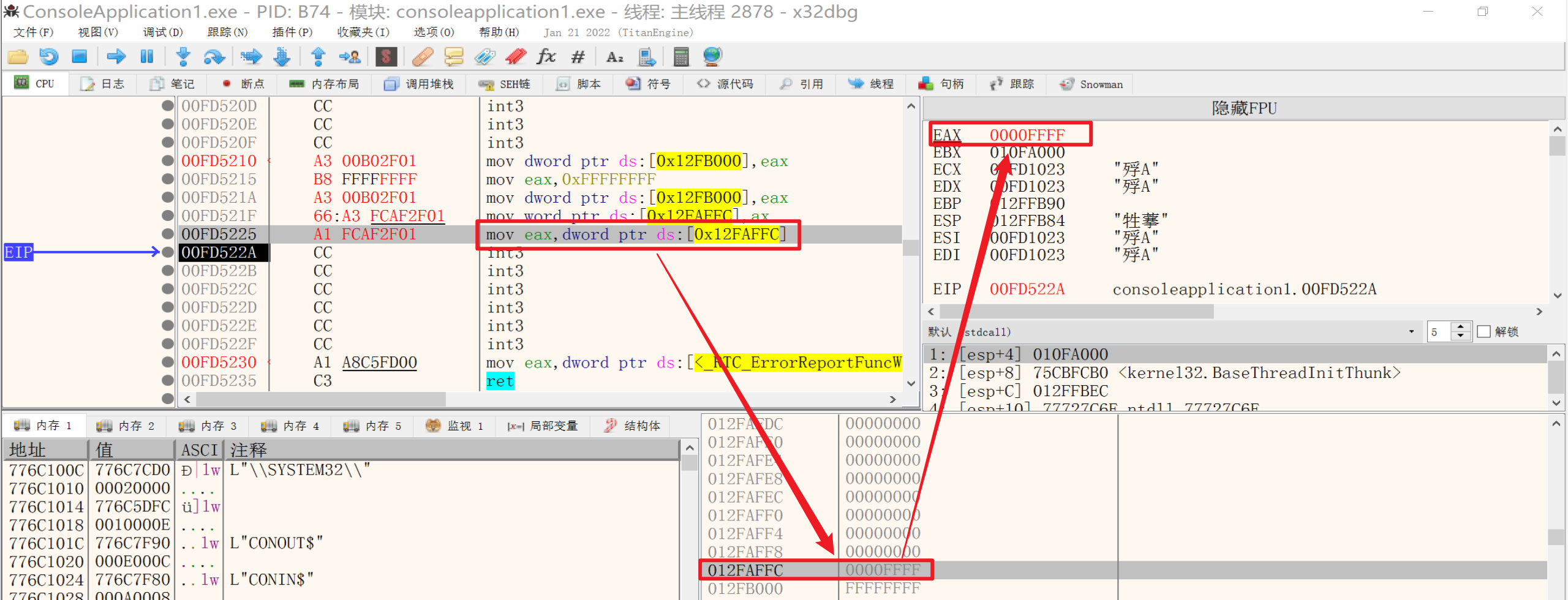
3.将内存中的值存到寄存器
1 | mov eax, dword ptr ds:[0x012FAFFC] |
3.内存地址的五种形式
1.形式一:[立即数]
读取内存的值
1 | mov eax,dword pyr ds:[0x012FAFFC] |
向内存中写入数据
1 | mov dword ptr ds:[0x012FAFFC] |
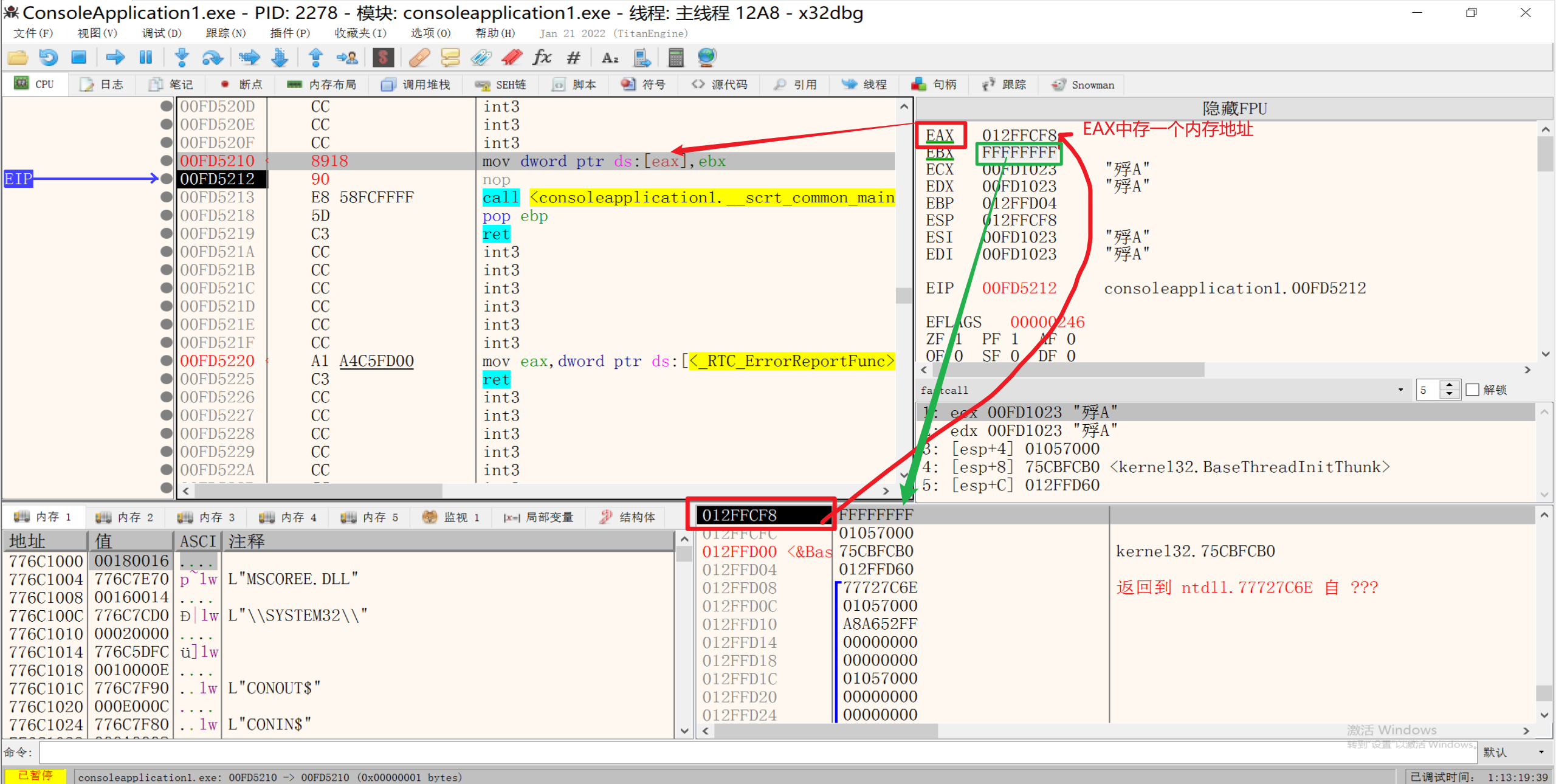
2.形式二:[reg] reg => 寄存器
reg代表寄存器,可以是8个通用寄存器中的任意一个
1 | mov dword ptr ds:[eax],ebx |
此处,EAX指向一个内存地址”0x012FFCF8”,EBX的值为FFFFFFFF
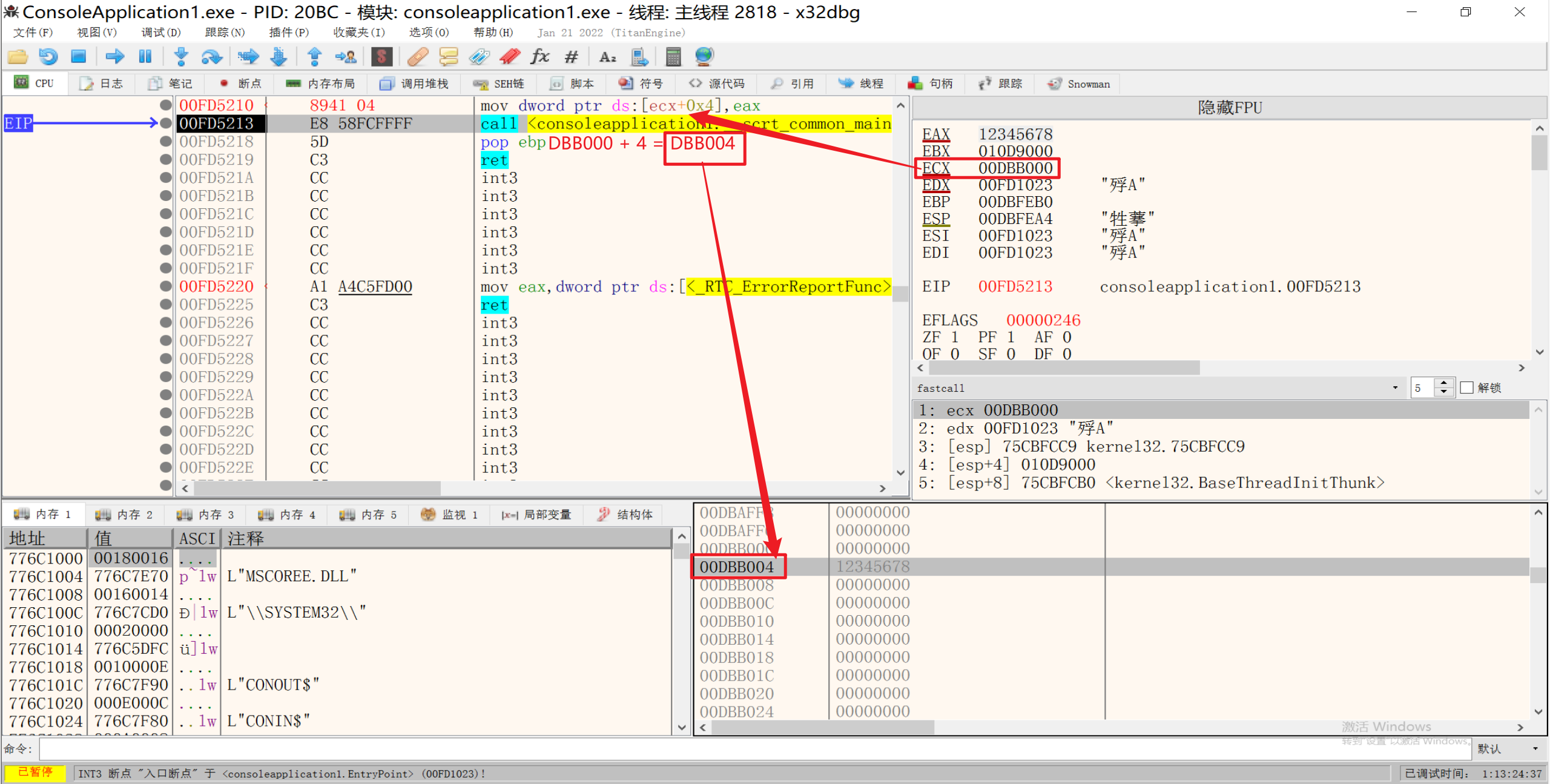
3.形式三:[reg+立即数]
1 | mov dword ptr ds:[ecx+4],eax |
此处ECX指向内存地址DBB000,+4后,[ECX+4]指向DBB004,然后将EAX中的值传到DBB004内存地址
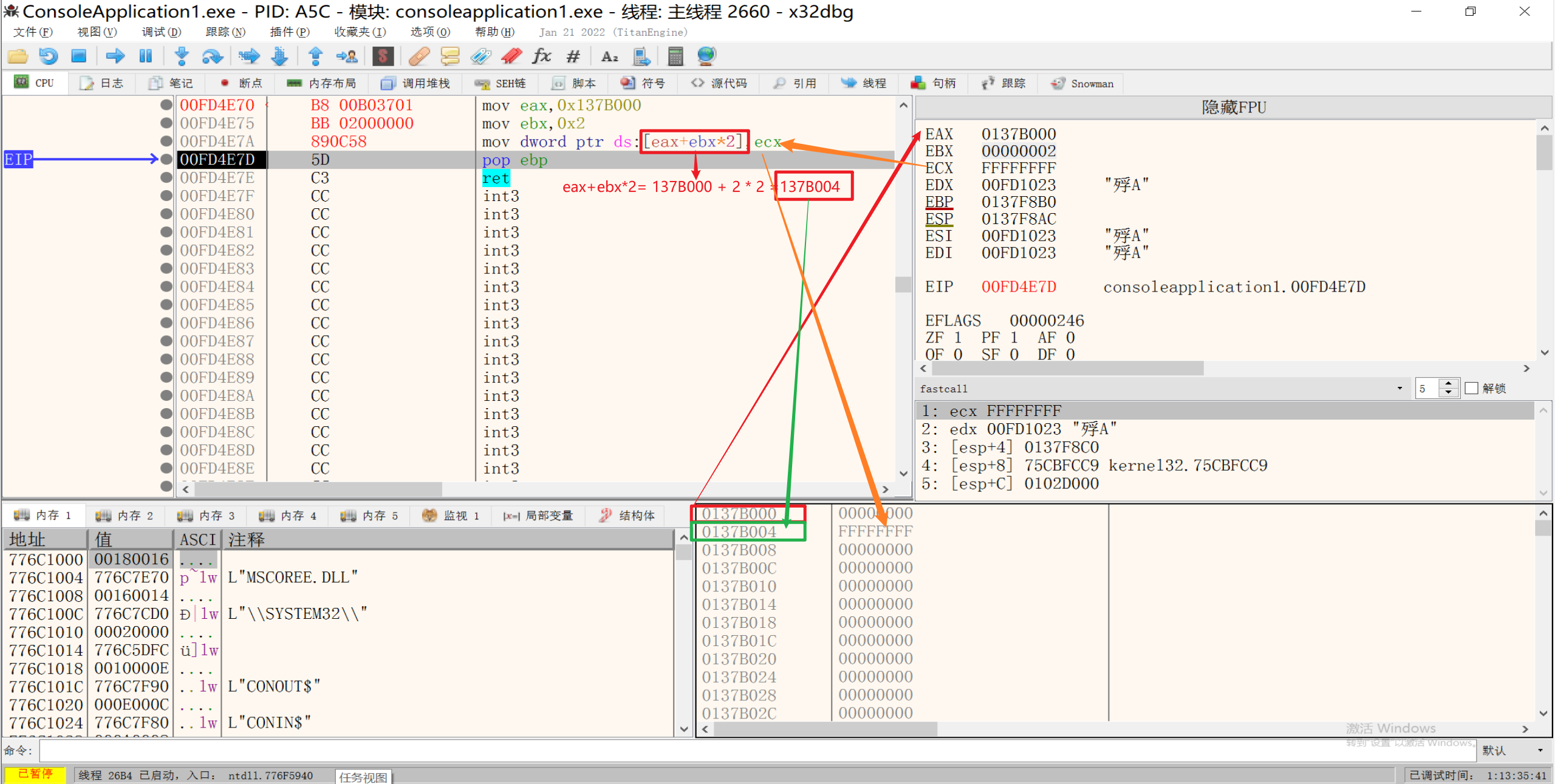
4.形式四:[reg + reg * {1,2,4,8} ]
寄存器加寄存器乘1,2,4,8中的一个数,一般C语言中数组生成的汇编语言是这样的
读取内存的值:
1 | mov eax, 0x13FFc4 |
向内存中写入数据:
1 | mov eax, 0x137B000 |
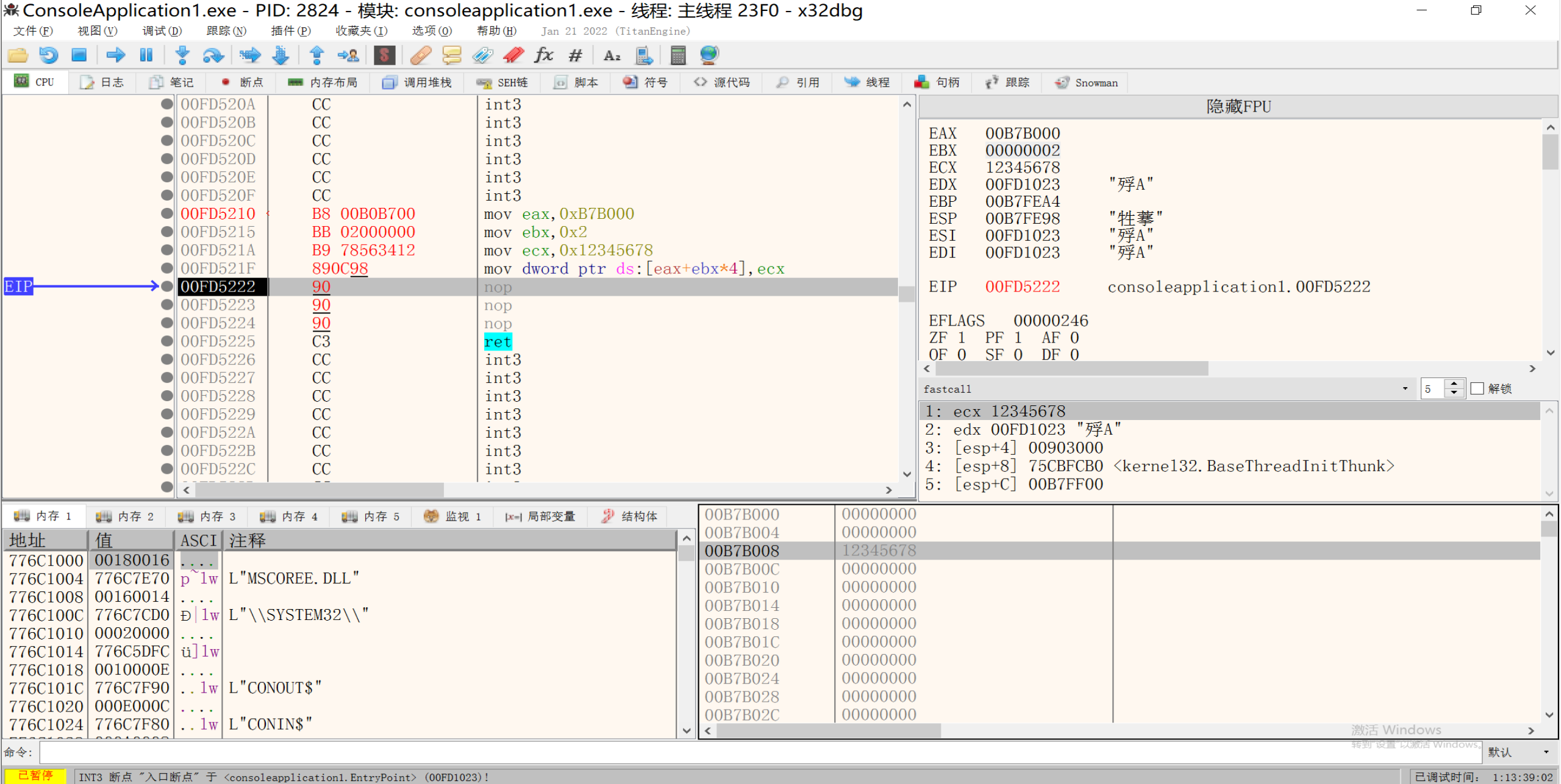
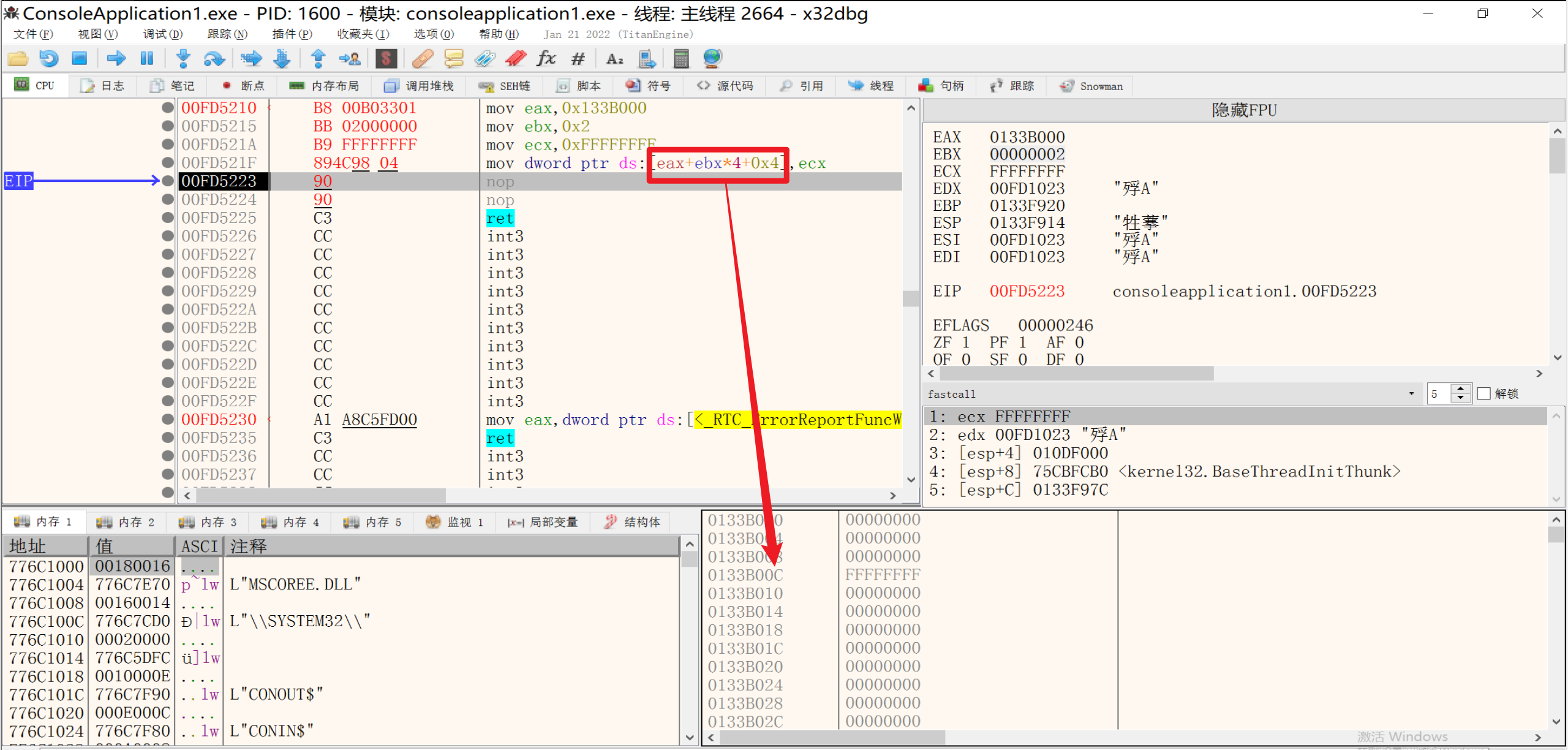
5.形式五:[reg + reg * {1,2,4,8} + 立即数 ]
1 | mov eax, 0x13FFc4 |
1 | mov eax, 0x137B000 |
6.数据的存储模式
1.大端模式:数据高位在低位,数据低位在高位
2.小端模式:数据低位在低位,数据高位在高位

大端模式:1A 0x00000000
2C 0x00000001


大端存储或小端存储受编译器影响,可以改成大端或小端
7.常用的汇编指令
1.MOV指令
指令格式:
1、MOV r/m8,r8
2、MOV r/m16,r16 将寄存器的值存到寄存器或内存
3、MOV r/m32,r32
4、MOV r8,r/m8
5、MOV r16,r/m16
6、MOV r32,r/m32
7、MOV r8,imm8
8、MOV r16,imm16
9、MOV r32,imm32
r代表通用寄存器,r8代表8位寄存器
m代表内存,m8代表8位内存
imm代表立即数,imm8代表8位立即数
2.ADD指令(加法指令)
ADD r/m8,imm8
ADD r/m16,imm16
ADD r/m32,imm32
ADD r/m16,imm8
ADD r/m32,imm8
ADD r/m8,r8
ADD r/m16,r16
ADD r/m32,r32
ADD r8,r/m8
ADD r16,r/m16
ADD r32,r/m32
3.SUB指令(减法指令)
SUB r/m8,imm8
SUB r/m16,imm16
SUB r/m32,imm32
SUB r/m16,imm8
SUB r/m32,imm8
SUB r/m8,r8
SUB r/m16,r16
SUB r/m32,r32
SUB r8,r/m8
SUB r16,r/m16
SUB r32,r/m32
4.AND指令(与运算)
AND r/m8,imm8
AND r/m16,imm16
AND r/m32.imm32
AND r/m16,imm8
AND r/m32.imm8
AND r/m8,r8
AND r/m16,r16
AND r/m32.,r32
AND r8,r/m8
AND r16,r/m16
AND r32,r/m32
5.XOR指令(异或运算)
XOR r/m8,imm8
XOR r/m16,imm16
XOR r/m32.imm32
XOR r/m16,imm8
XOR r/m32,imm8
XOR r/m8,r8
XOR r/m16,r16
XOR r/m32,r32
XOR r8,r/m8
XOR r16.r/m16
XOR r32,r/m32
6.NOT指令(非运算)
NOT r/m8
NOT r/m16
NOT r/m32
7.MOVS指令 移动数据从内存到内存
MOVS BYTE PTR ES:[EDI],BYTE PTR DS:[ESI] 简写为:MOVSB
MOVS WORD PTR ES:[EDI],BYTE PTR DS:[ESI] 简写为:MOVSW
MOVS DWORD PTR ES:[EDI],BYTE PTR DS:[ESI] 简写为:MOVSD
ESI存储的是一个地址,是一个内存编号,就是要复制的数据在哪里
EDI存储的是一个地址,是要把数据复制到哪里去
标志寄存器 EFL
00000204
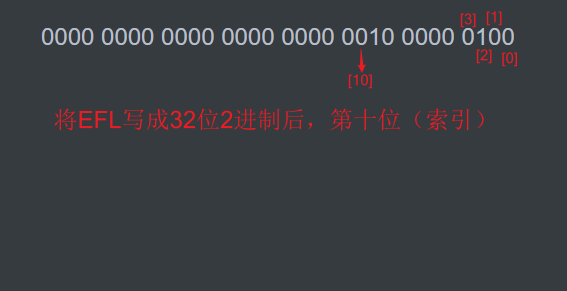
第十位为DF位,当DF位为0时,使用MOVS等指令,MOVS完之后,地址会自动递增(从低地址向高地址处理串)
当DF位为1时,使用MOVS等指令,MOVS完之后,地址会自动递减(从高地址向低地址处理串)

地址自动递增(递减)时,移动的长度取决于移动了一个字节、两个字节还是四个字节。
8.STOS指令
将al/ax/eax的值存储到[EDI]指定的内存单元
1 | STOS BYTE PTR ES:[EDI] 每次存一个字节 |
9.REP指令
按照计数寄存器(ECX)中指定的次数重复执行字符串指令
计数寄存器是ECX,不是别的
1 | MOV ECX,10 |
首先在ECX中存一个数,这个数是十六进制的,如果ECX中存10,则执行16次,每执行一次减一
8.堆栈相关的指令
1.堆栈
1)就是一块内存,操作系统在程序启动时已经分配好的,供程序执行时使用。
2)和数据结构的堆栈无关
3)查看堆栈
2.ESP寄存器(栈指针寄存器)
3.PUSH指令
功能: < 1 > 向堆栈中压入数据
< 2 >修改栈顶指针ESP寄存器
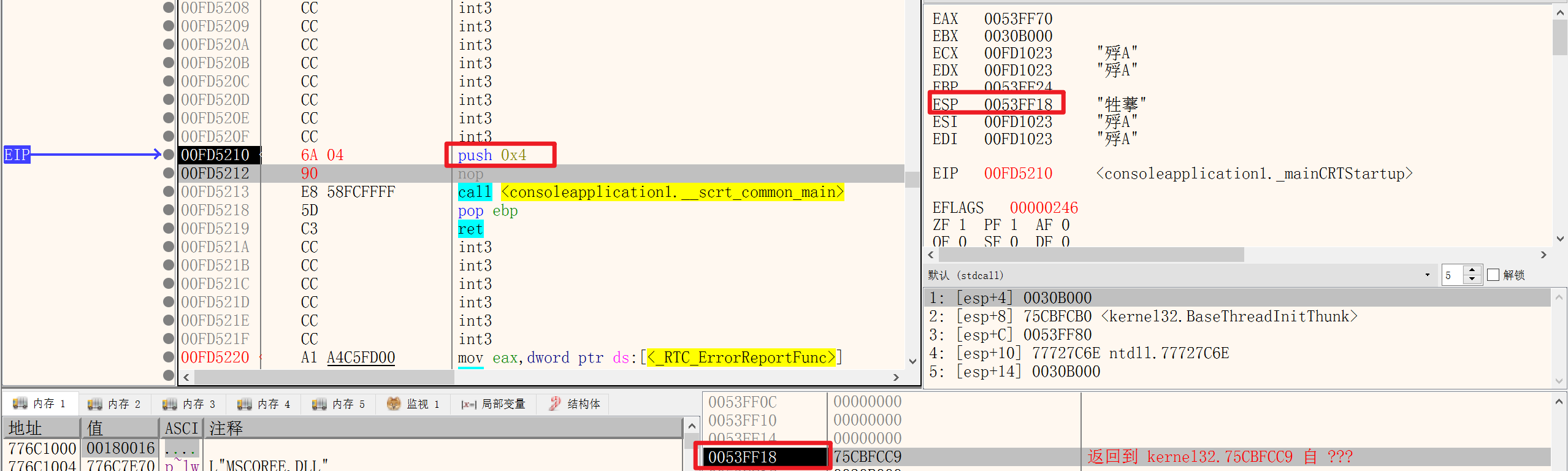
执行PUSH指令后:
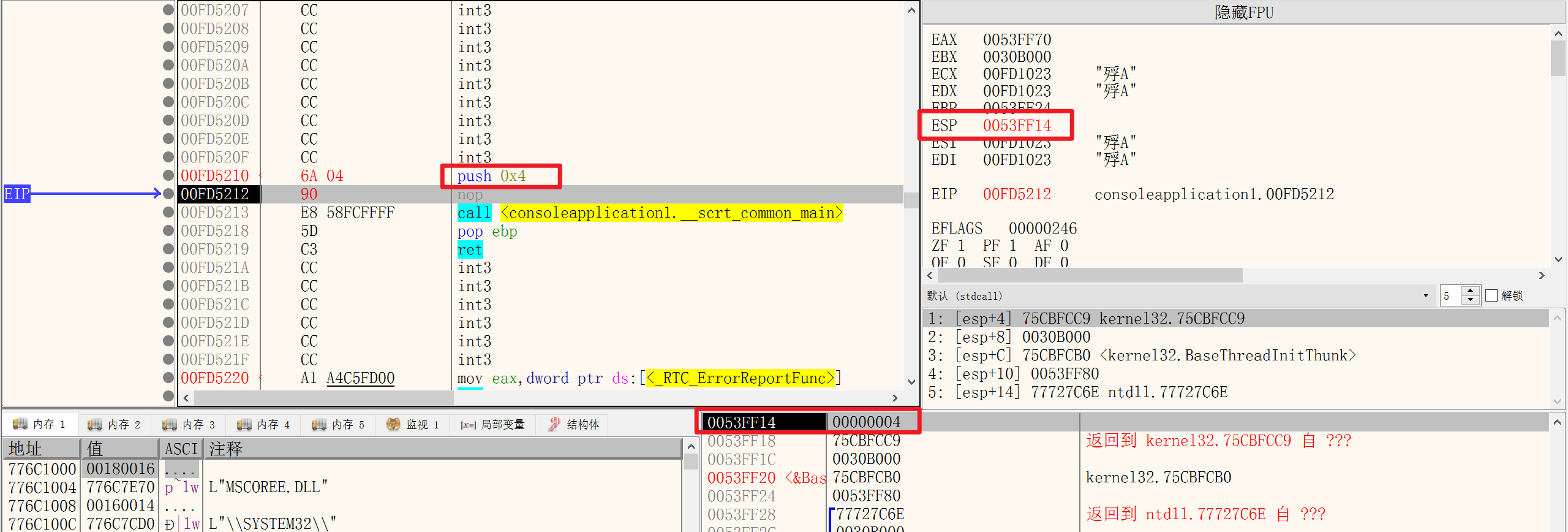
4被存储在了0x0053FF14中,并且ESP指向了当前的地址,因此PUSH指令是将MOV DWORD PTR DS:[]指令和SUB ESP,0x4简化了
除了PUSH立即数,还能PUSH寄存器
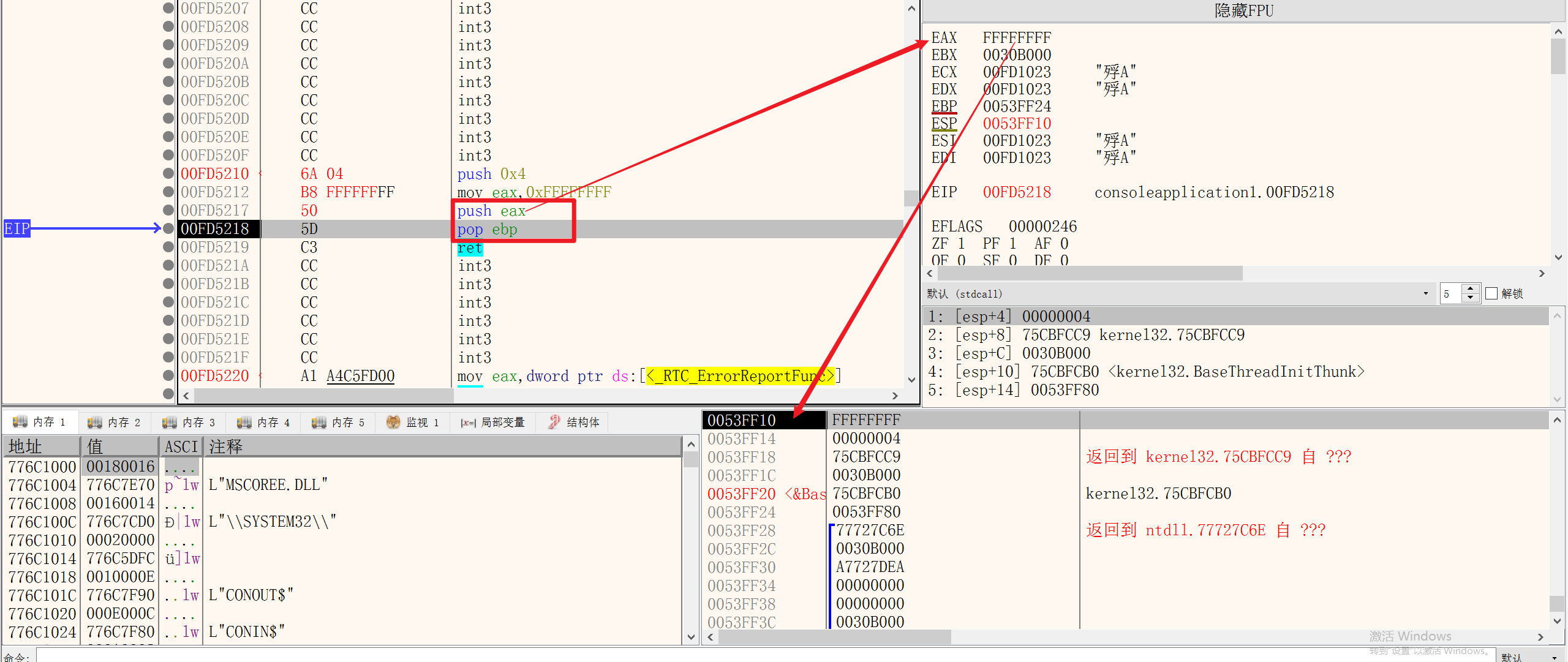
9.EIP寄存器
JMP
EIP寄存器不能使用MOV进行修改
使用JMP指令修改EIP寄存器,EIP寄存器存储的是CPU下一次要执行的地址
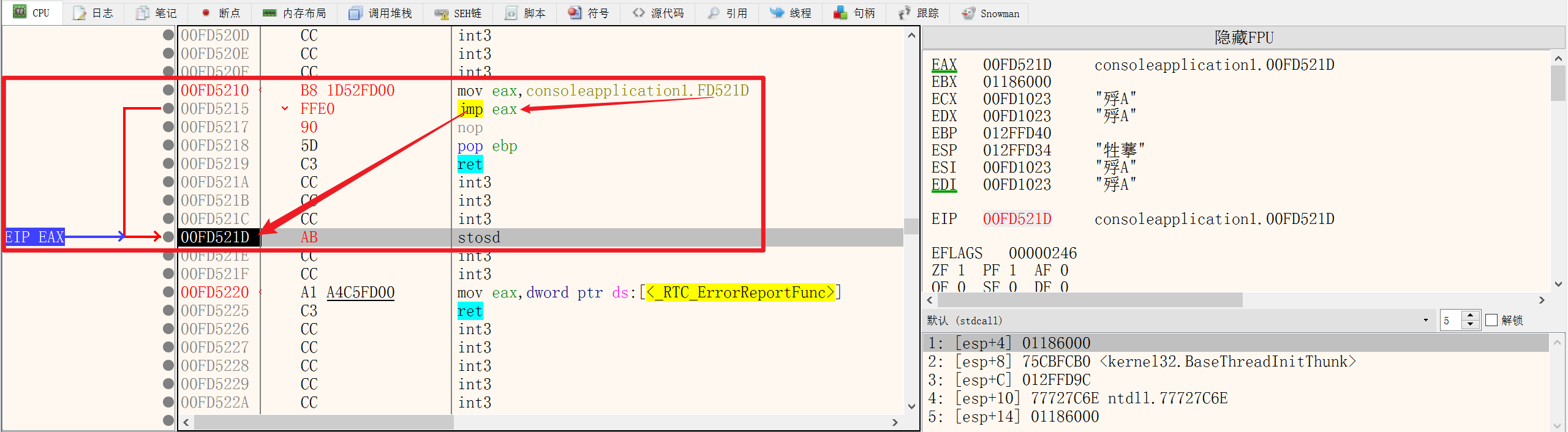
JUM指令可以跟立即数,也可以跟其他寄存器或内存
CALL
1.将CALL后面的值存到EIP里
2.将CALL的下一行地址存到了堆栈中
3.ESP中的地址减0x4
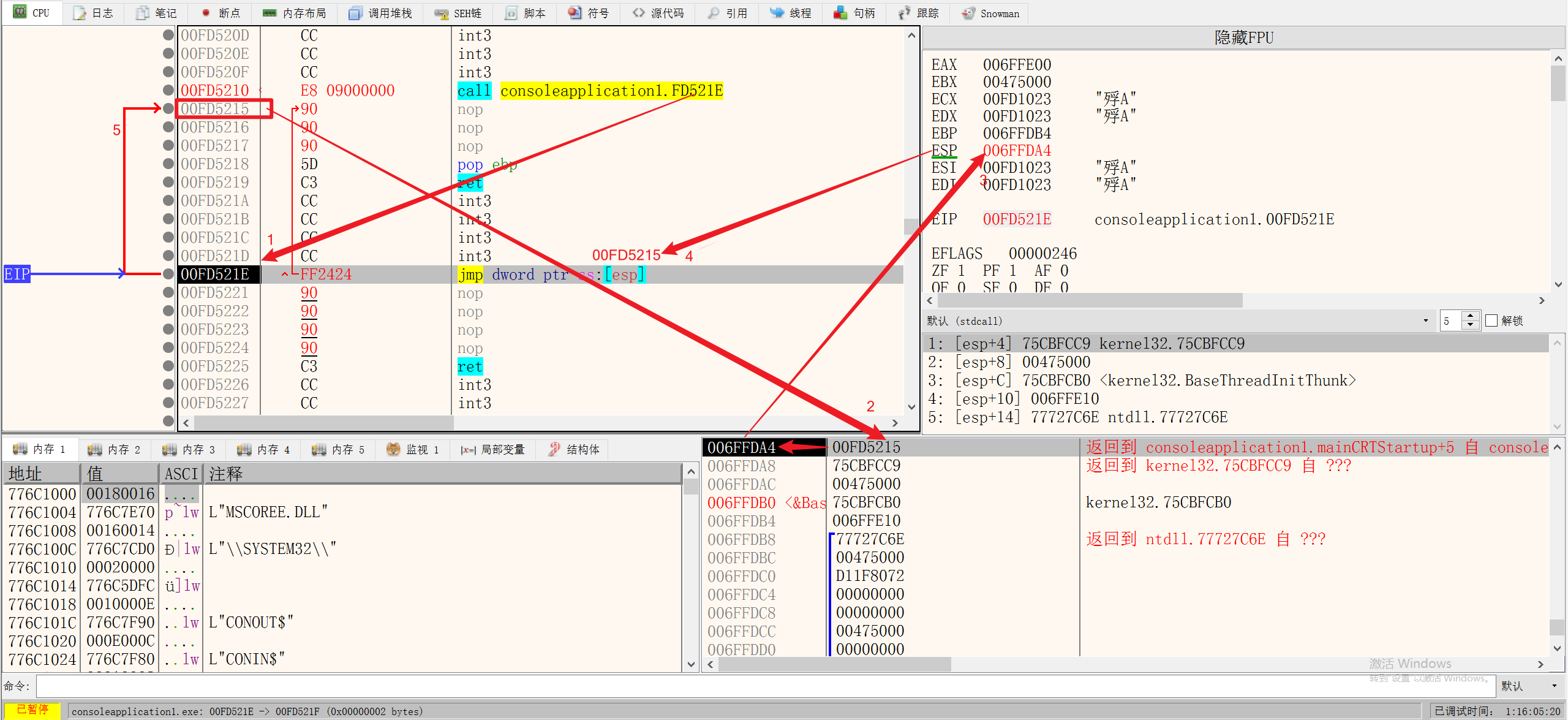
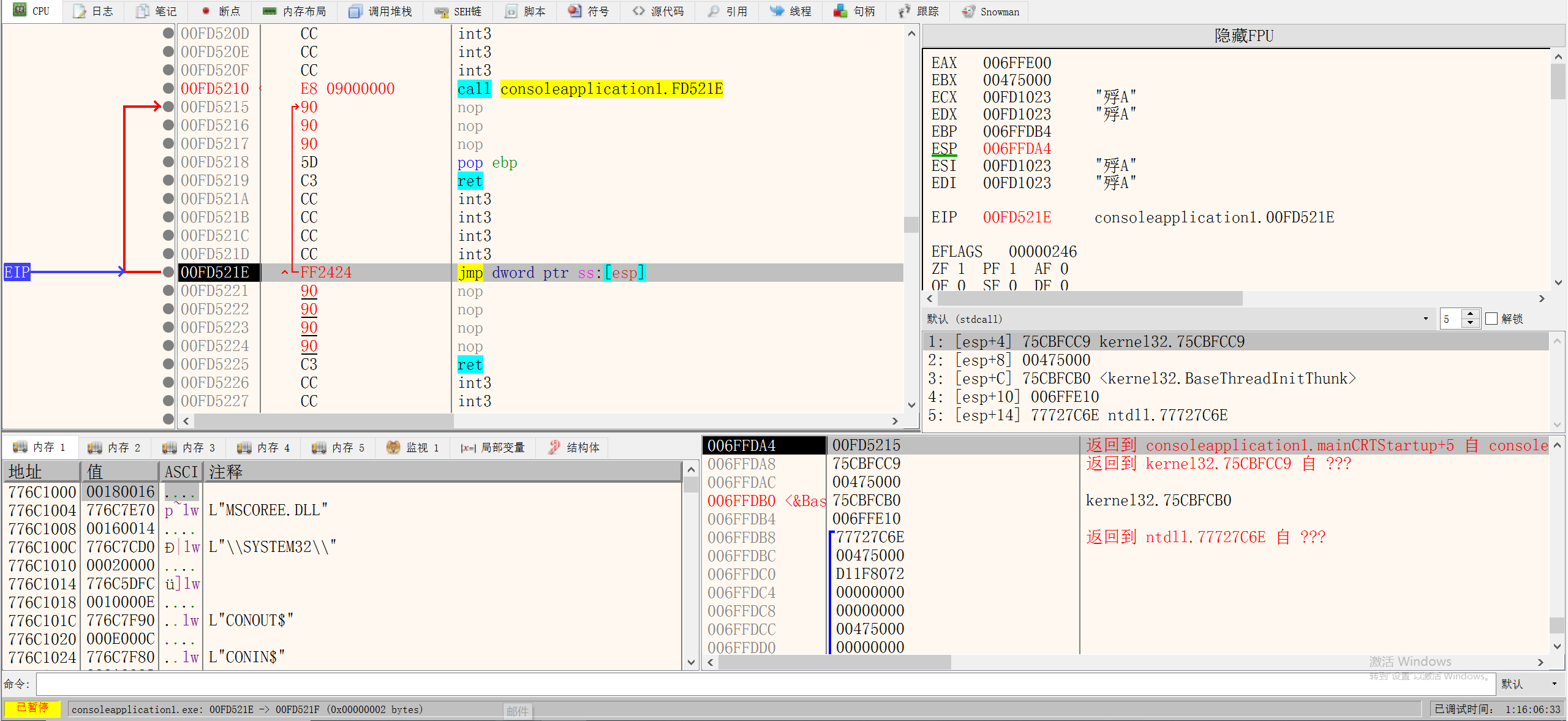
RET(return)
1.将当前栈顶指针ESP的值放到EIP里
2.将ESP加0x4
相当于:
1 | ADD ESP,4 |
10.函数
1.函数的执行与调用
调用函数时一般使用CALL指令:因为通过CALL指令,会把CALL的下一行地址压到堆栈中,此时执行完函数之后只需要使用RET指令,即可返回到CALL指令的下一行
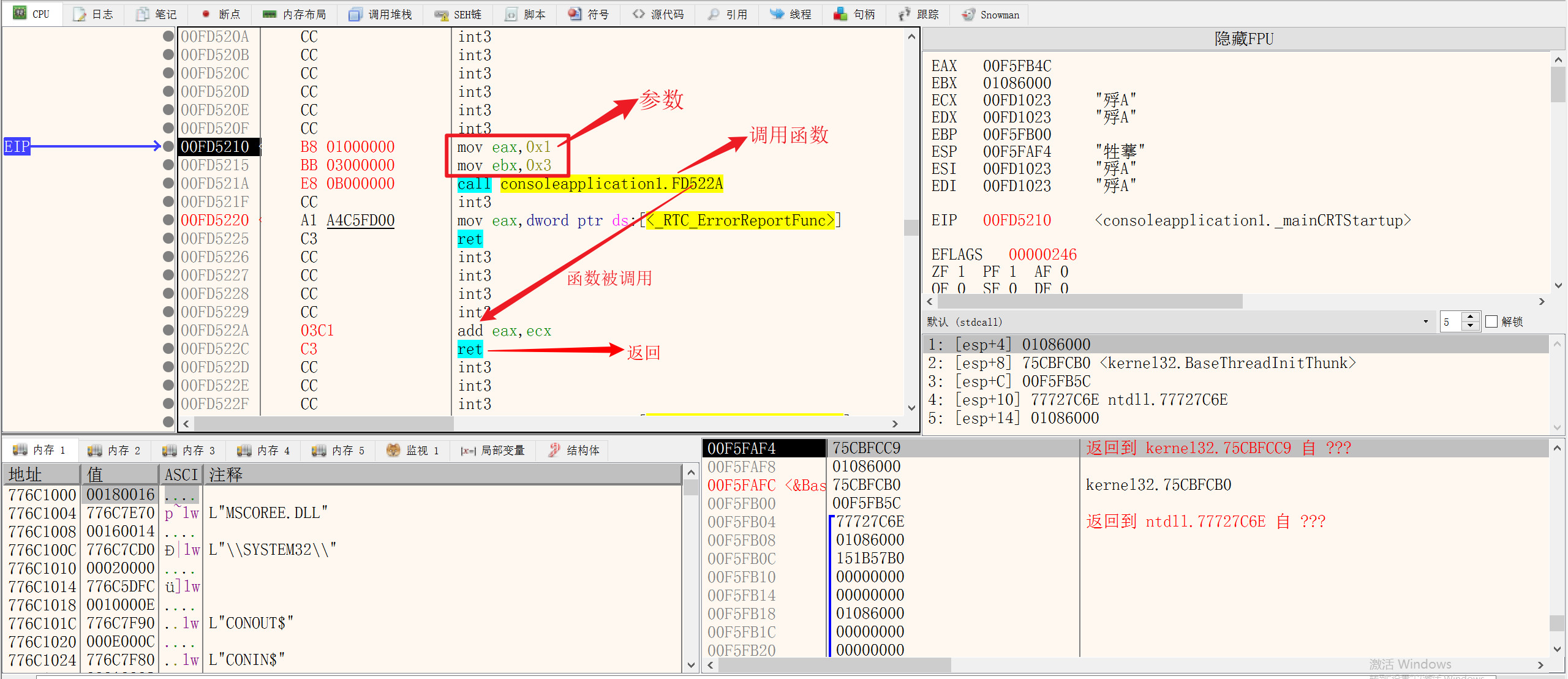
执行函数后:
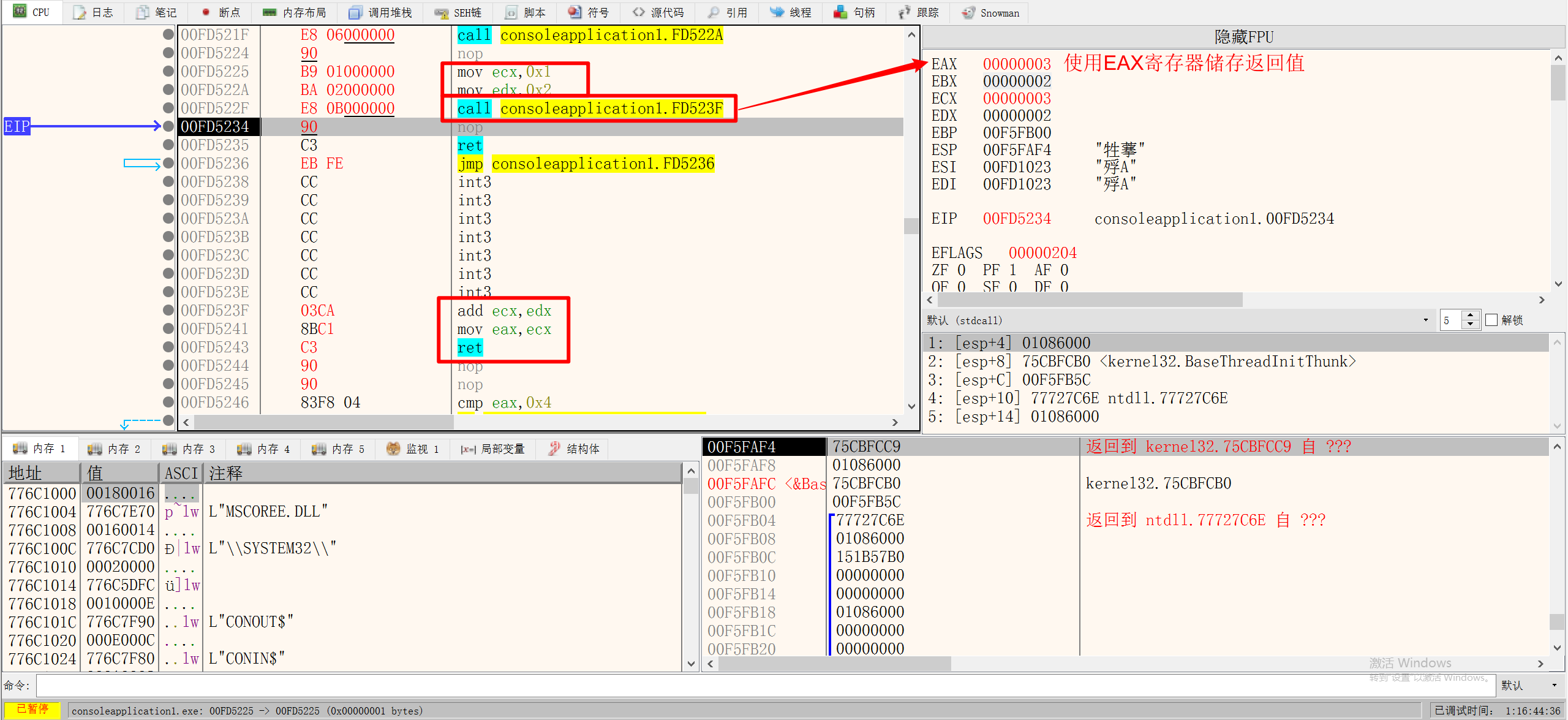
在调用函数传参时,如果有10个参数怎么办,如果使用通用寄存器只有8个,则使用堆栈传参
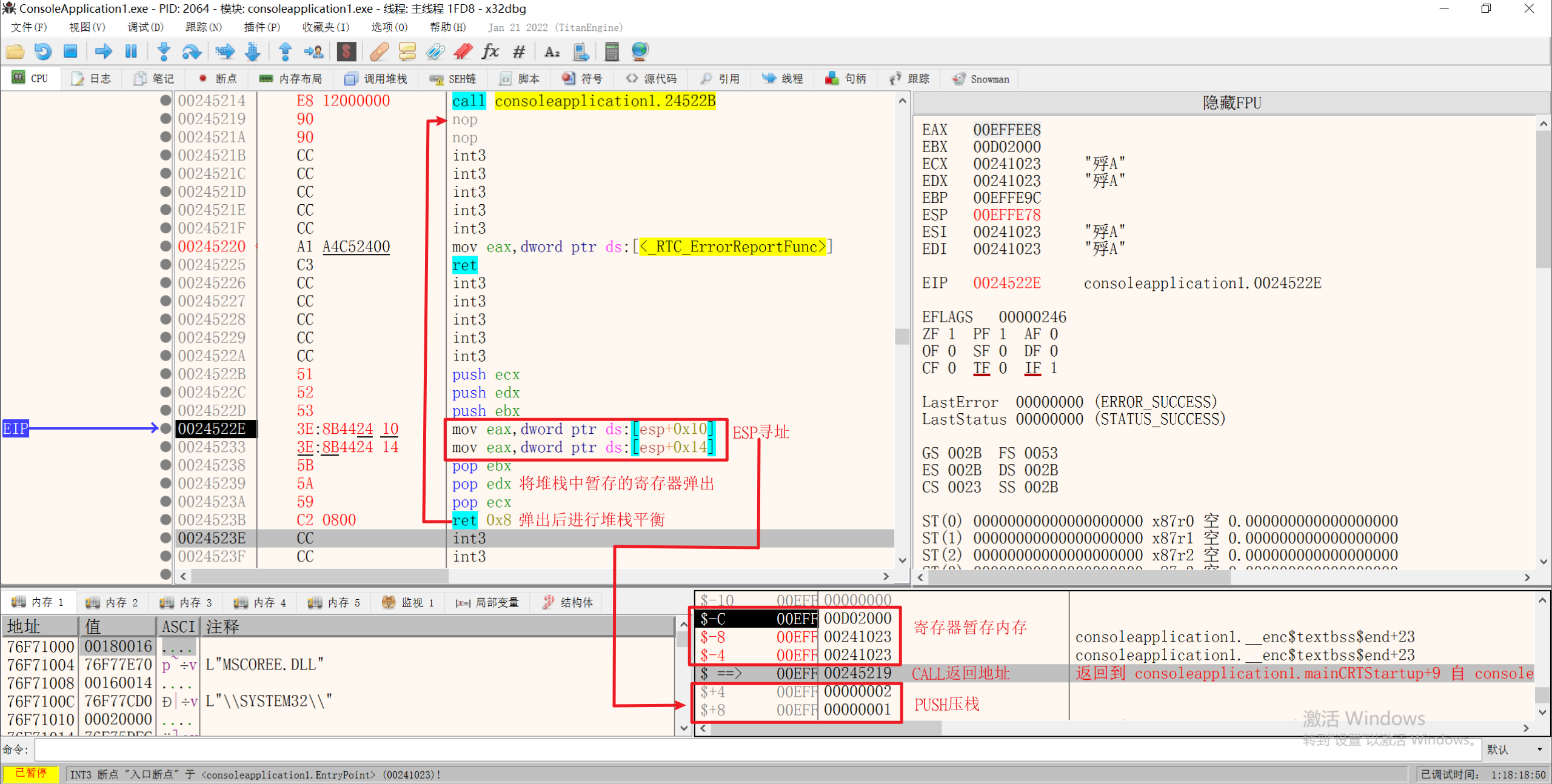
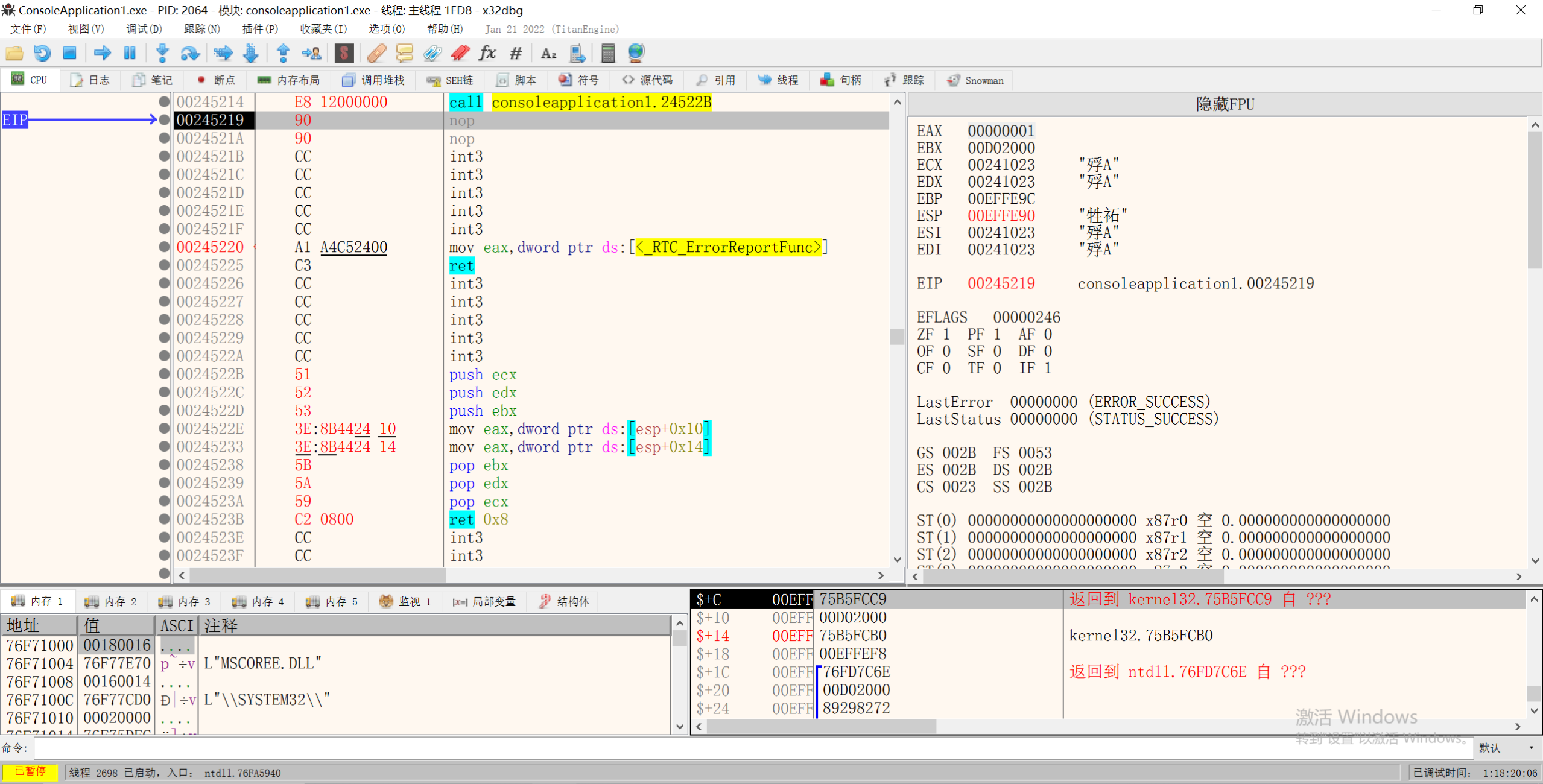
用过PUSH指令,向堆栈中压入参数,需要调用的时候,在函数中使用ESP寻找参数
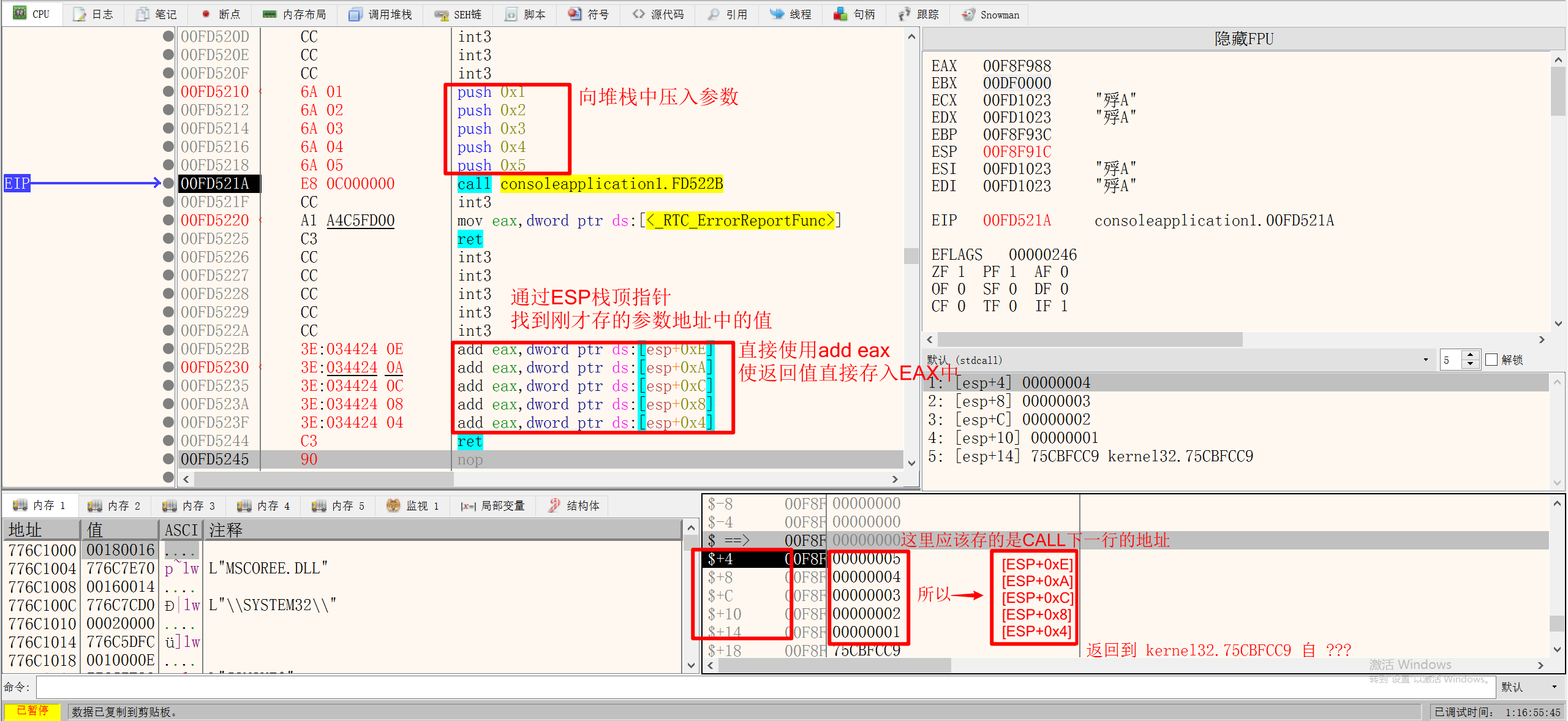
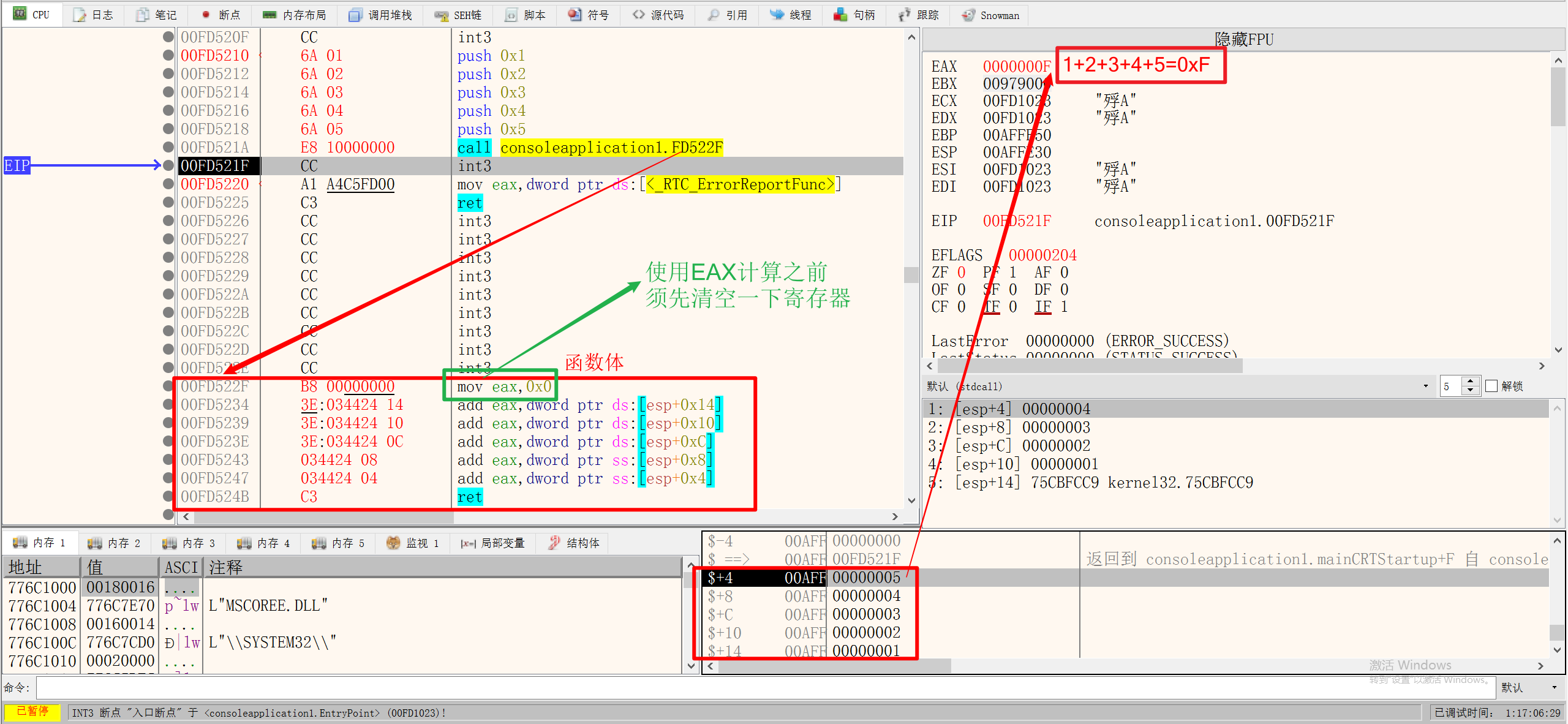
因为CALL函数后,ESP会-4操作并寄存CALL的下一行的地址,所以使用ADD EAX, DWORD PTR DS:[ESP+立即数] 即可找到之前PUSH的参数
2.堆栈平衡
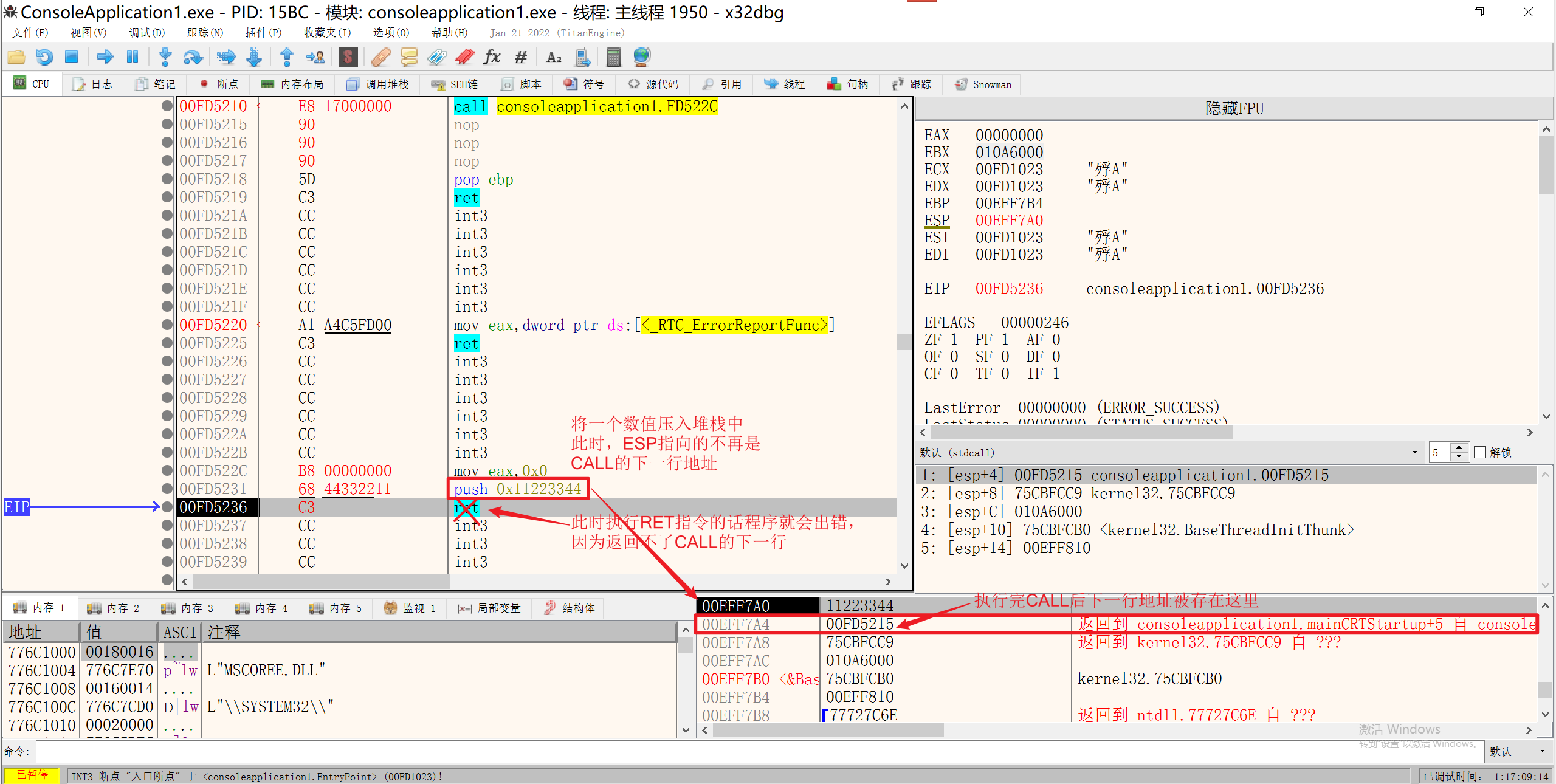
在函数调用的时候,执行完CALL指令,会将下一行地址压入堆栈,此时进入了函数体,当函数在执行时,可能会PUSH一些值到堆栈中,此时ESP指向的地址就不是CALL的下一行地址,如果此时使用了RET指令,那么返回的地址错误,程序就会出错,也就是堆栈不平衡。
所以在函数执行完毕执行RET指令时,要保证ESP指向的地址是之前CALL指令执行后的下一行地址。
11.寻址
1.ESP寻址
当使用ESP寻址之前在函数体中又向堆栈中PUSH了值,就会使ESP寻址更加困难,而且在堆栈中暂存寄存器的值还需要POP,所以使用ESP寻址较繁琐。
2.EBP寻址
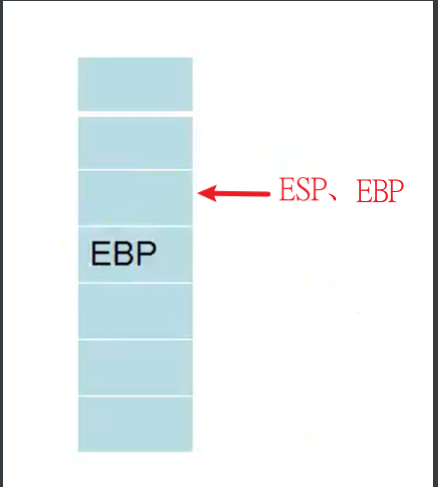
先将EBP保存起来,然后让EBP指向ESP的位置,将现在的ESP提升一块,也就划分出了一块新的堆栈,供当前程序(函数)使用。
当CALL函数时,继续向堆栈中压入数据,ESP会上下浮动,但是不会影响从EBP到ESP提升后的位置。从EBP到ESP提升的这一段空间就可以放置参数,那么参数就可以使用EBP来寻址。
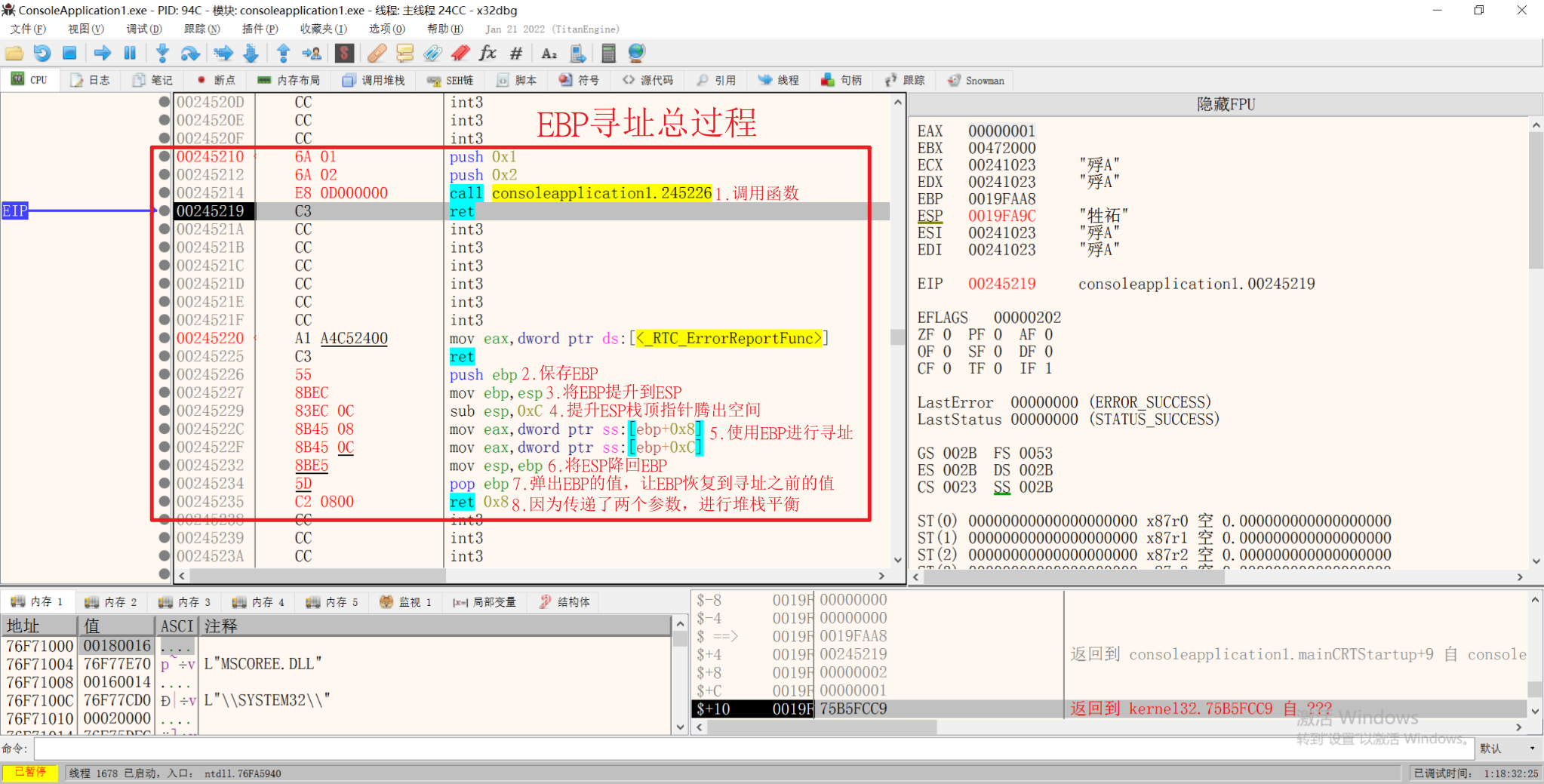
1.保存EBP
1 | call 0x000000AA |
此时,堆栈就会变成这样

2.将EBP提升到ESP
1 | mov ebp, esp |
此时堆栈和栈指针变成这样:
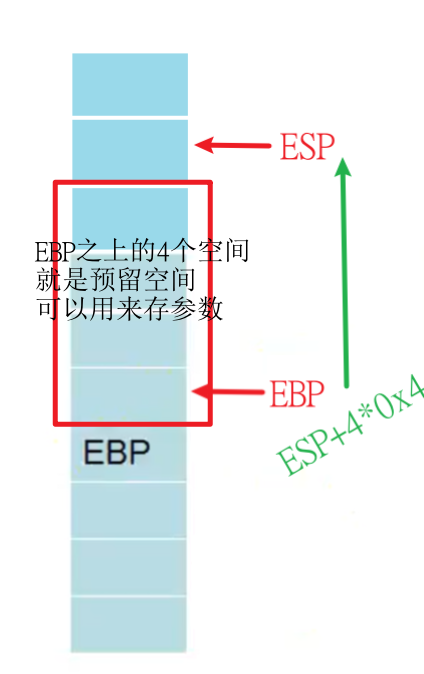
3.提升ESP栈顶指针
1 | sub esp 4*0x4 |
使用sub就是将ESP指针向上移,使EBP向上到ESP腾出了一部分空间
4.使用内存
可以使用EBP栈指针寻找参数:
1 | mov eax dword ptr ss:[ebp+0x8] |
5.恢复内存
将ESP返回到EBP的位置
1 | MOV ESP, EBP |
此时EBP不用了,就把EBP取回
1 | POP EBP |
弹出后EBP后ESP会指向之前存EBP的内存地址
此时堆栈就恢复到了EBP寻址前的样子
6.RET 立即数
因为CALL之前压入了参数,所以用RET 立即数 进行堆栈平衡
EBP寻址总过程:
12.JCC
1.标志寄存器EFLAGS
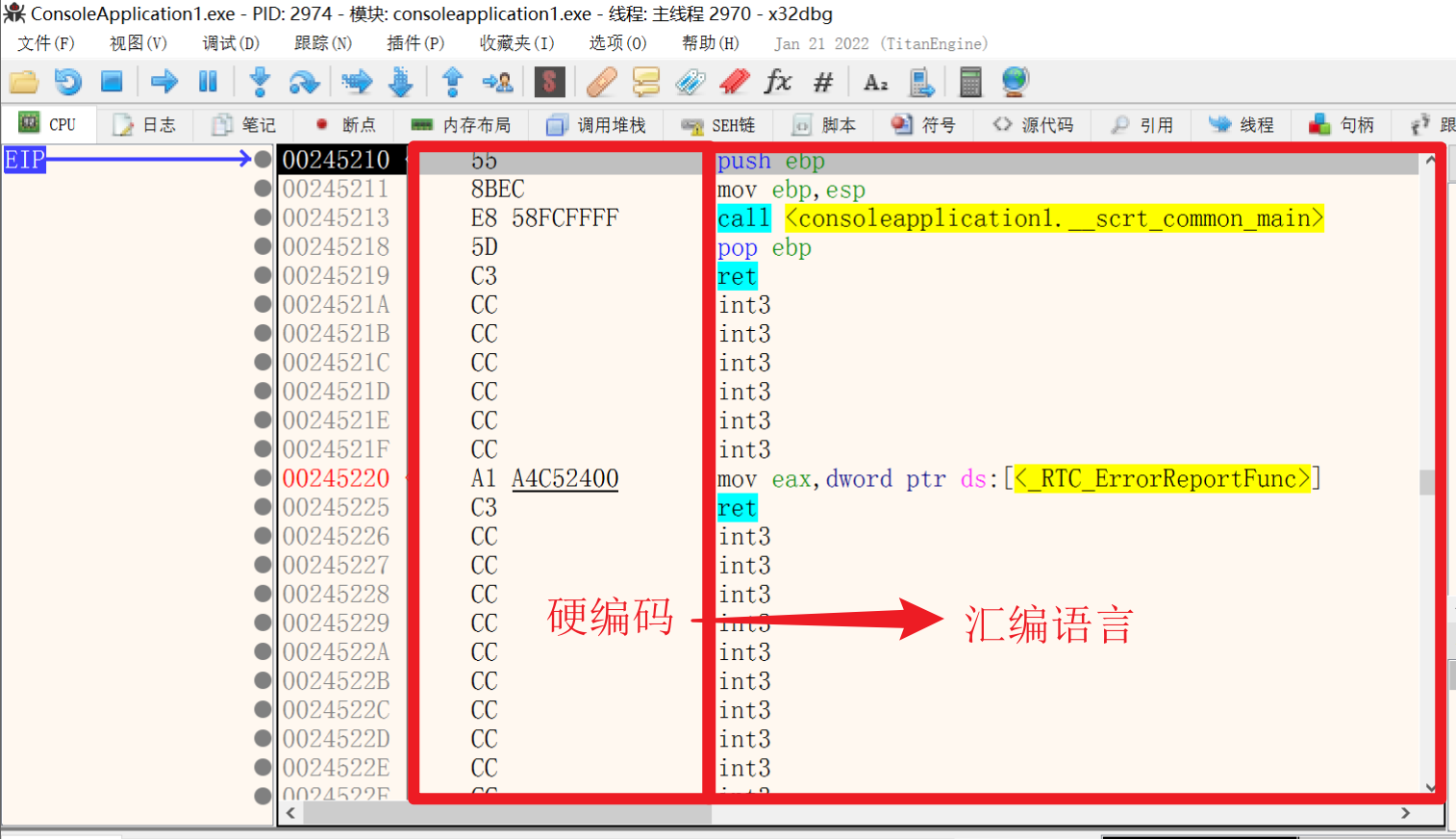
13.硬编码
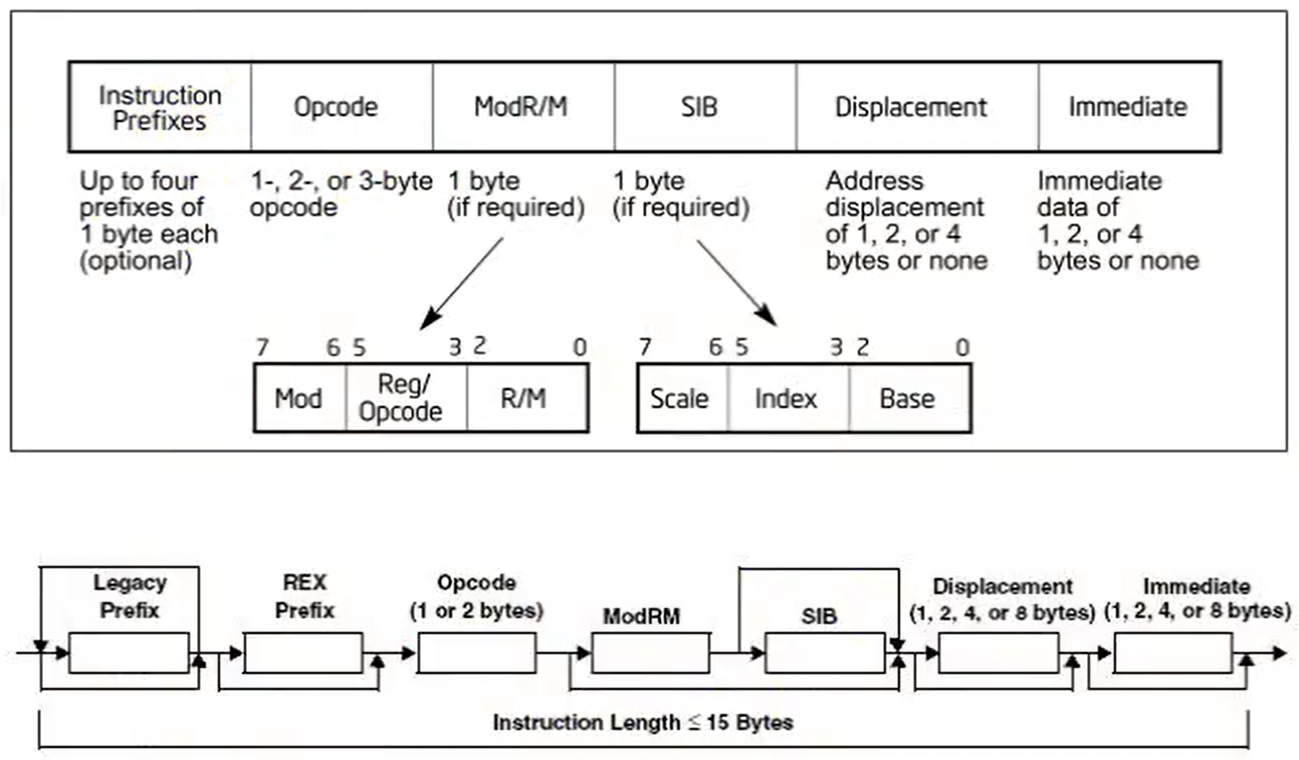
1.指令编码(硬编码)的结构
2.反汇编引擎(x32dbg , DTDebug
将硬编码转换成汇编语言,或将汇编语言转换成硬编码
3.前缀指令

看上面的结构图,最后面有一个(optional),说明指令前缀是可选的。CPU判断一个指令是前缀还是OPcode,通过值来判断。
反汇编引擎会在前缀指令后面加一个冒号来区分。但是,实际上在exe中并没有这个冒号
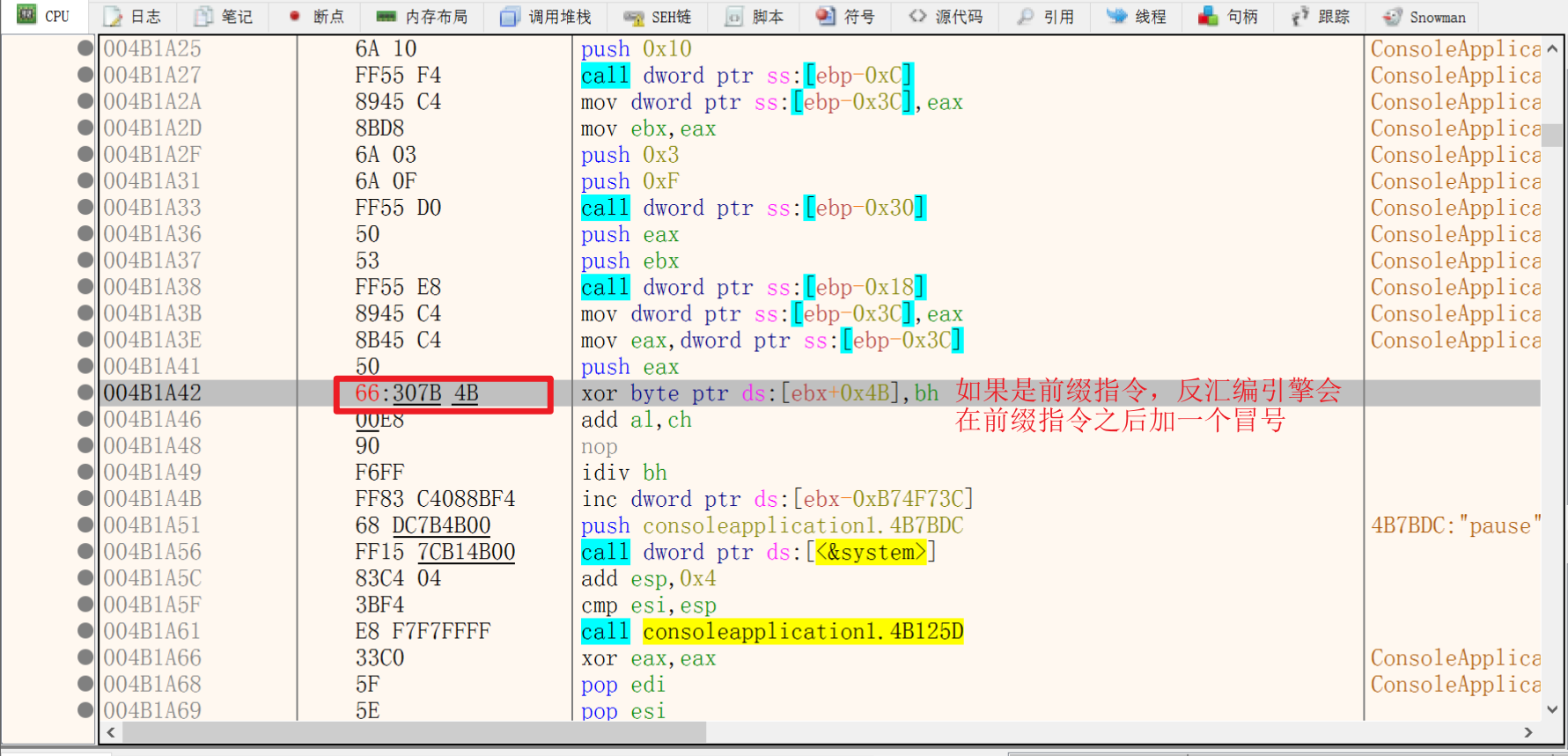
前缀指令是分组的,前缀指令最多四个,每组最多一个

(1)LOCK和REPEAT前缀指令
LOCK F0,用来锁地址总线,如果在一个地址上加上LOCK,如果在同一时刻有多个CPU核执行这条指令,只能有一个核可以读取这个地址,其他核不能读取这个地址。这条指令在多核下才有用,单核没有什么作用
REPNE/REPNZ F2
这两个指令,当EFLAGS寄存器的ZF位为0的时候执行上面的ZF位为1时执行下面的
REP/REPZ F3
(2)段(段寄存器)前缀指令 => 操作系统、内核程序
CS(2E)、SS(36)、DS(3E)、ES(26)、FS(64)、GS(65)
如果不指定哪个段寄存器,则使用DS段寄存器;当寻址时出现了EBP、ESP时,默认使用的段寄存器是SS段寄存器
段寄存器就是指定寻址时,使用的段寄存器是谁
比如,当加上了前缀指令65,那么后面就会使用GS段寄存器

操作数宽度前缀指令 66
66
比如,当硬编码55 PUSH EBP 时,默认的是32位的EBP寄存器,如果想用16位的BP寄存器,则在前面加上前缀指令 66,用来改变操作数宽度。而如果当前CPU默认处于16位状态下,如果加上66前缀,那么操作数就会变成32位的EBP寄存器

地址宽度前缀指令 67
当当前的寻址方式是32位的,当加上地址宽度前缀时,32位的寻址方式会变成16位寻址方式

总结:前缀指令最多四个,每组一个,一行指令可以添加多个前缀指令,前缀指令的顺序没有要求。
4.定长指令与变长指令
Opcode:在硬编码结构中,其他的结构可以没有,但是opcode必须要有,opcode 可以是1byte 2byte 3byte
Opcode是一条指令中最重要的组成部分,后面的ModR/M有没有由Opcode决定,SIB有没有由ModR/M决定。
定长指令:当Opcode确定了,指令长度就确定了
变长指令:仅仅通过Opcode是无法确定长度的
定长指令
经典定长指令:修改ERX(通用寄存器)
1.PUSH/POP 5057,585F

2.INC/DEC 4047,484F
INC加一,DEC减一
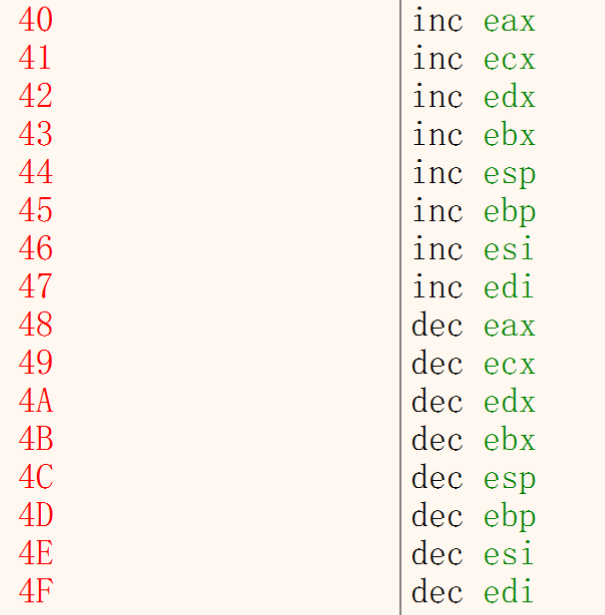
3.mov 寄存器, 立即数
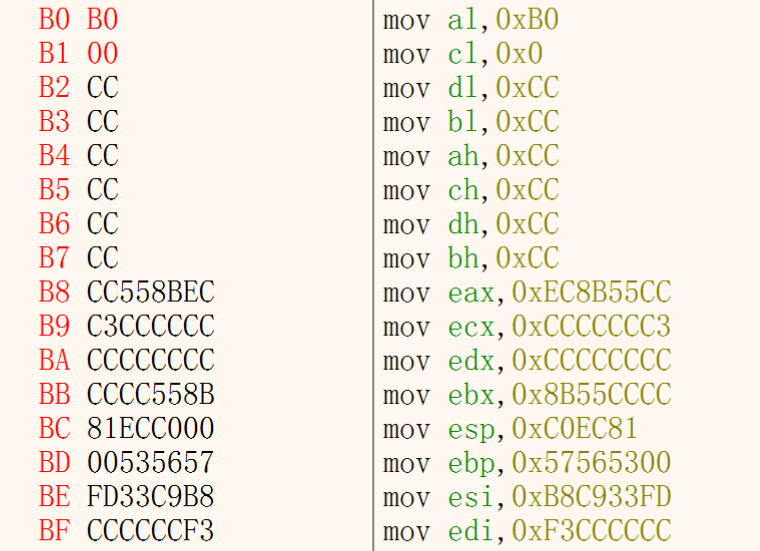
4.XCHG 两个寄存器的值交换
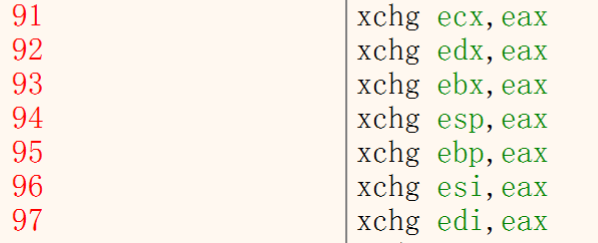
经典定长指令:修改EIP(CPU执行地址)
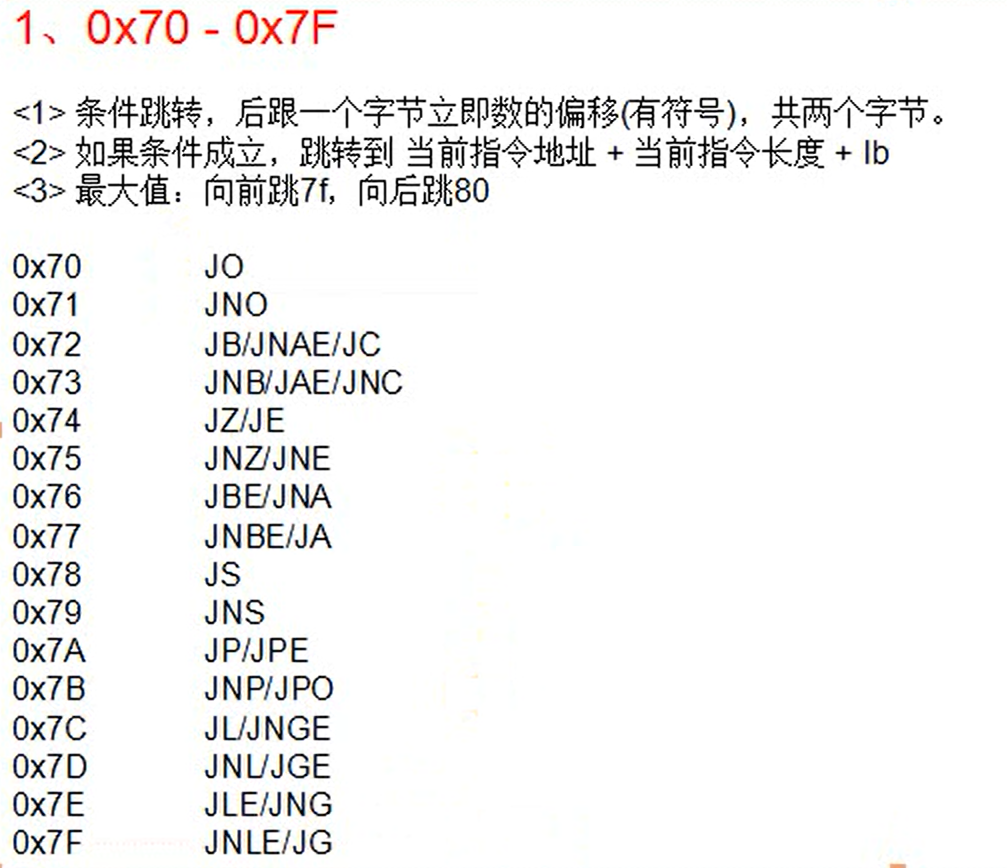
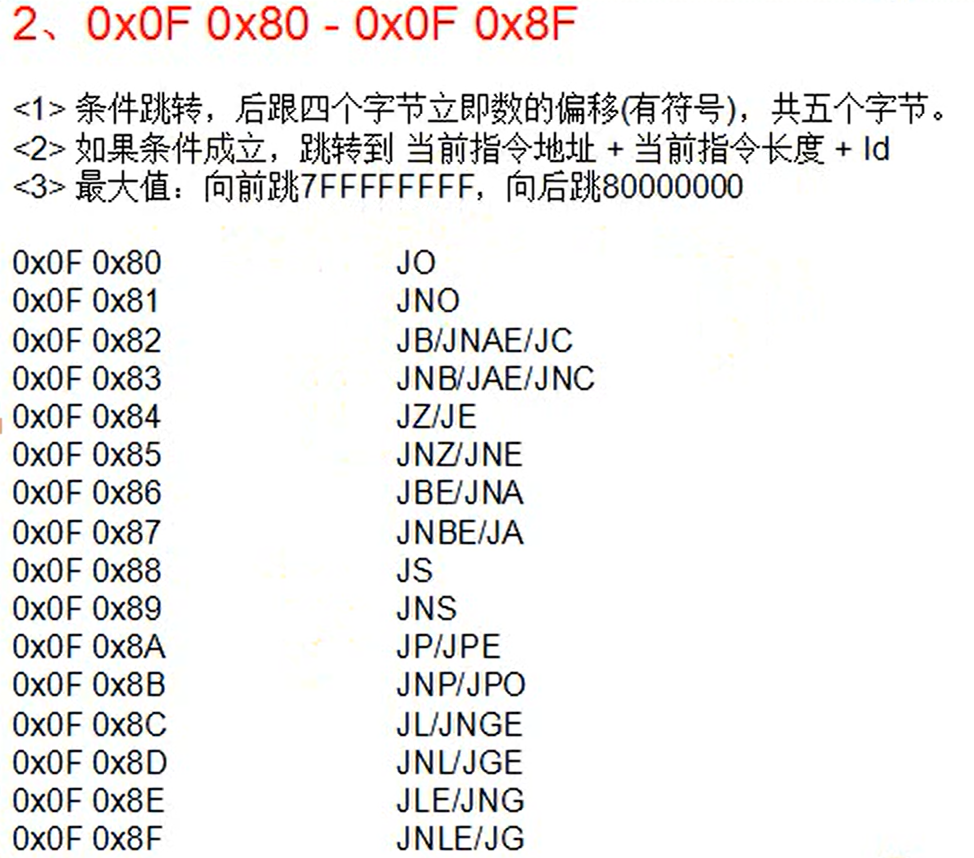


变长指令
当opcode 后面有ModR/M结构时,就是变长指令
重要的变长指令

1 | 0x88 MOV Eb, Gb |
ModR/M占一个字节,该字节的8个位被分成了三部分使用

Mod(6,7位)和R/M(0、1、2位) 共同描述指令中的E部分即寄存器或内存
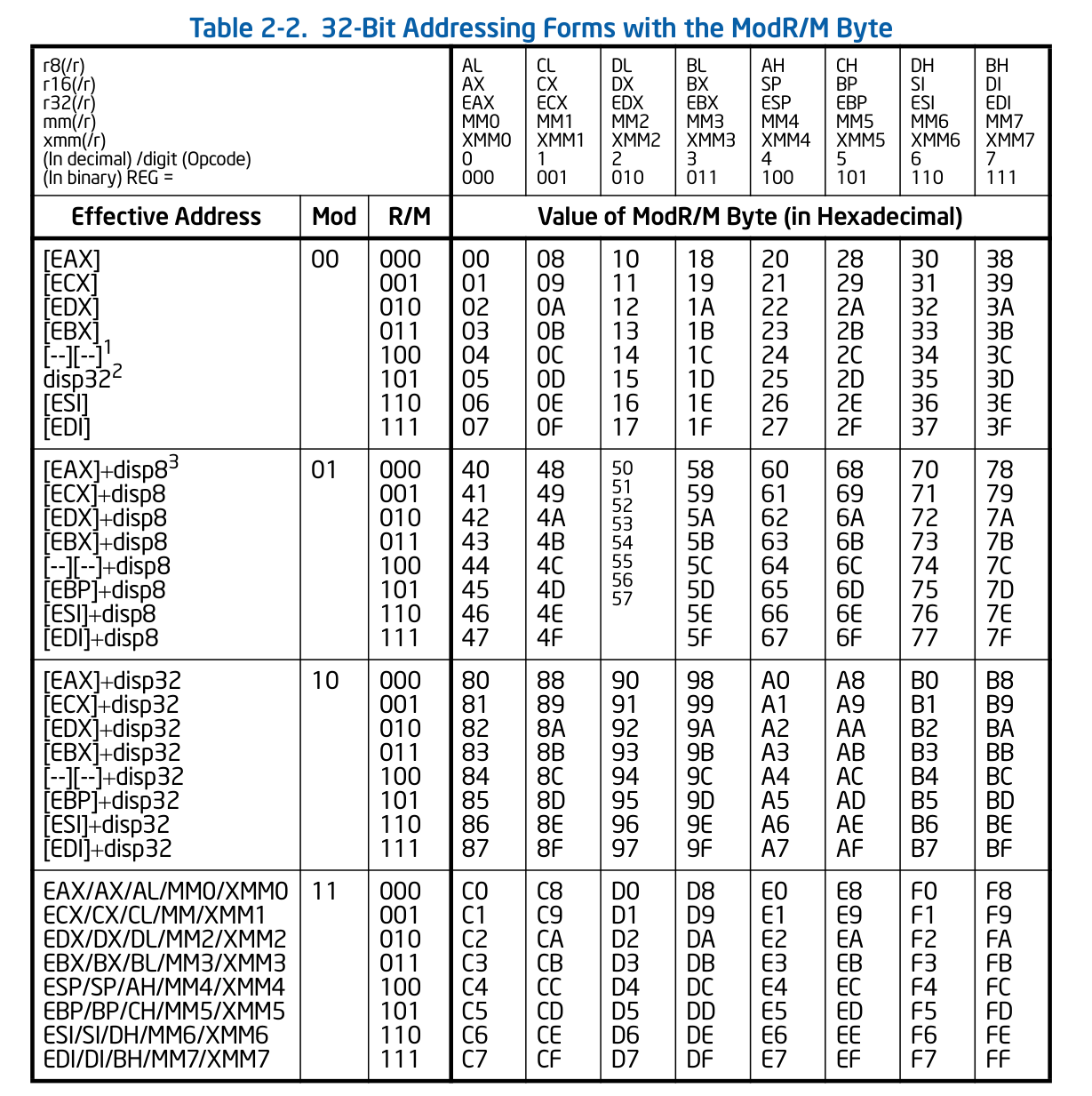
ModR/M中间部分第3、4、5位,用来描述Reg/Opcode也就是指令中的G部分,即寄存器

比如一个硬编码 88 01
88:MOV Eb, Gb
01:00 000 001 第3、4、5位是000,查表能得到EAX/AL。因为G后面跟的b,所以是8位的AL。 现在的指令就是MOV Eb, AL
再查表,Mod:00,R/M:001,对应的寄存器是ECX 所以,指令就变成了 MOV BYTE PTR DS:[ECX], AL
ModR/M结构

1.Mod与R/M共同描述E的意义(内存或者通用寄存器)
2、Reg/Opcode描述了G的意义(通用寄存器)。但3-5字段,并不仅仅用来标识寄存器,有些时候,用来标识Opcode。
拆一个编码 80 65
65: 01 100 101
Mod:01 Reg/Opencode R/M:101
根据Mod R/M查出byte ptr ds:[ebp+dis8], Ib
当查表时看到Grp,就要去查Table A-6

Table A-6:
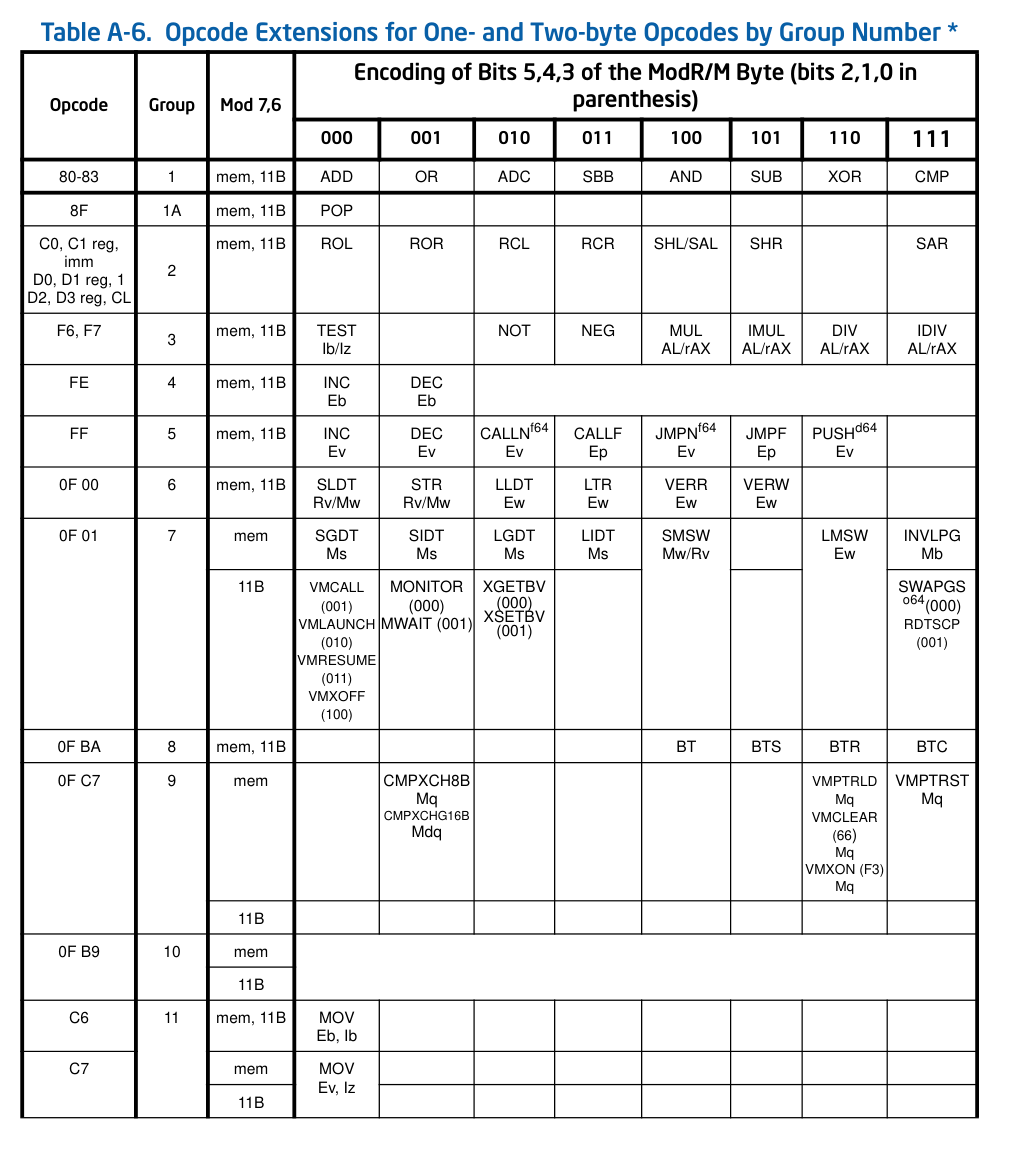
查表A-2能得到100对应的是AND指令,所以,80 65对应的汇编就是AND byte ptr ds:[ebp+dis8], Ib
但是发现这条指令里面还有一个8位的地址偏移DIS8,一个立即数Ib,所以后面还应该有两个值。

定长指令 SIB

如一个指令 88 84 48
通过查表,88是MOV Eb, Gb 那么84就是ModR/M。10 000 100
Mod Reg R/M
Reg:AL 查表得Mod为00,01,10时,R/M对应的是 [ – ] [ – ] 或 [ – ] [ – ] +disp8 或 [ – ] [ – ] +disp32
那么这里的[ – ] [ – ]就是由SIB决定的,因此48就是SIB。
SIB的指令结构:
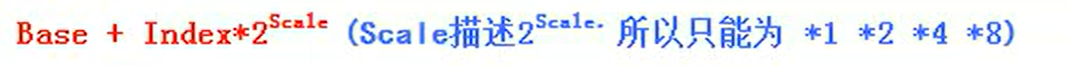
48: 01 001 000 => 查Table2-3
scale index base
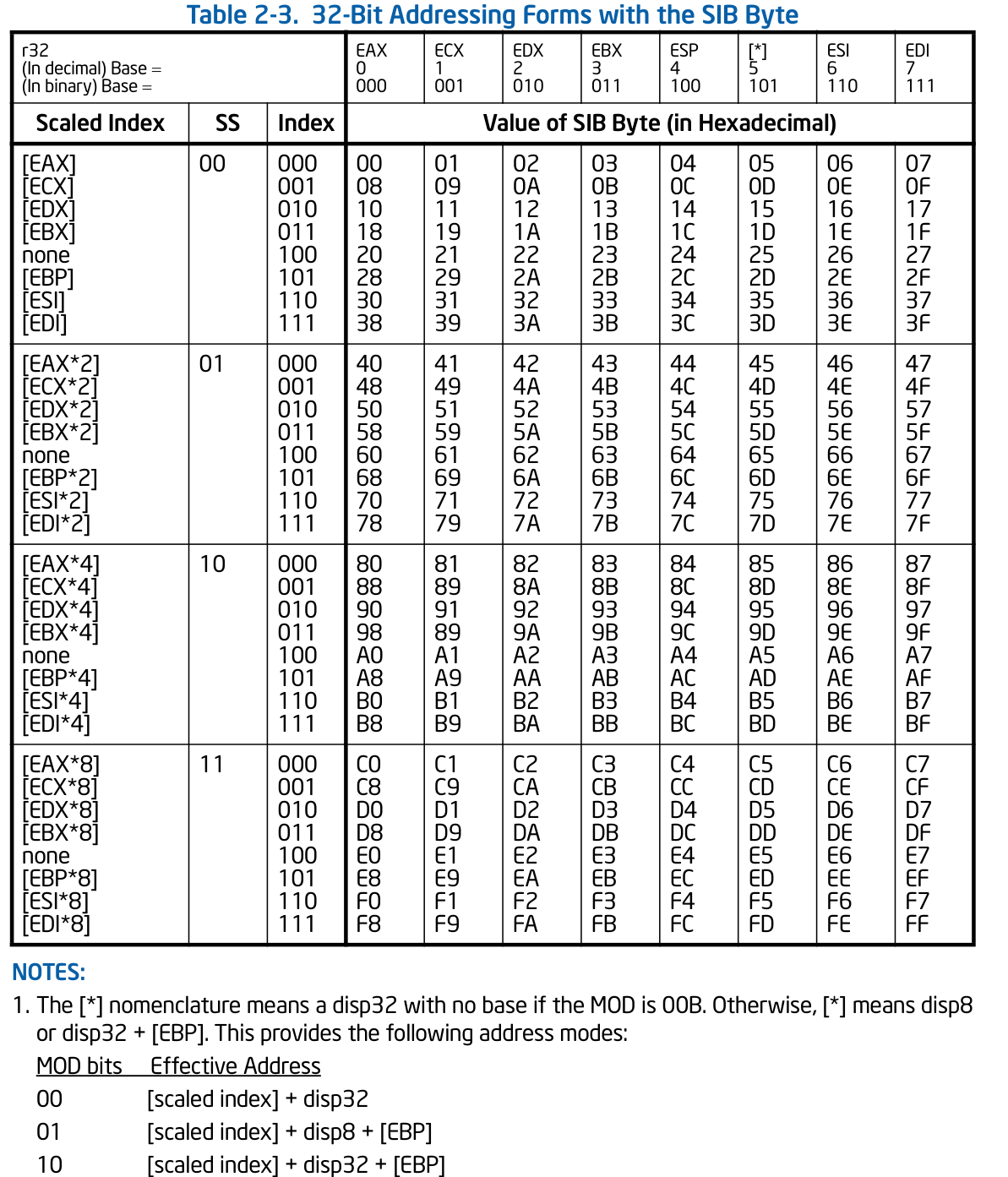

查base是000,所以是[EAX]
再找scale 和 index ,是[ECX * 2]
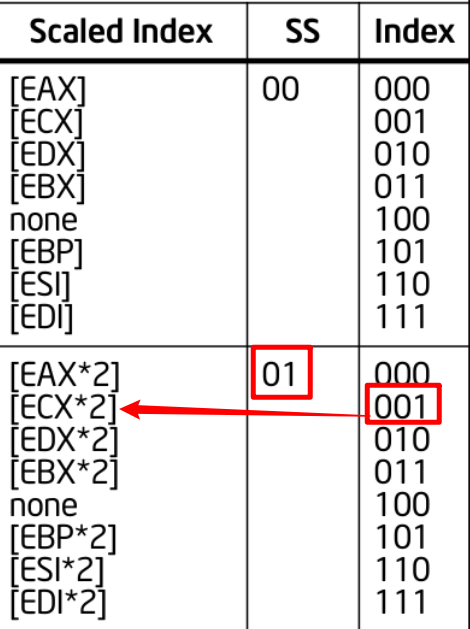
所以48对应的SIB就是[ EAX + ECX * 2 ]
因此,88 84 48对应的汇编代码就是MOV BYTE PTR DS:[ EAX + ECX * 2 + DIS32], AL
因为还有一个32位的地址偏移,所以88 84 48后面还会跟着四个字节
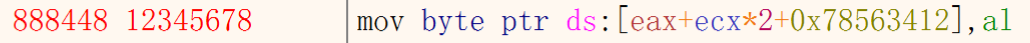
堆栈
堆栈的本质就是一块内存,在程序启动之初就分配好了,给程序执行的之后使用。任何一个程序用到的关键数据都存在堆栈里。
栈是一种后进先出的数据结构
1.ESP和EBP
ESP栈顶指针,它表示当前这块堆栈用到哪里了。ESP上面的堆栈是还未使用的堆栈。
EBP是栈底指针,这个栈底指针不是指堆栈的最底部,而是当前这一段代码(函数)的栈底(本层call的栈底)
2.PUSH、POP 堆栈操作指令
PUSH就是把数据传入到堆栈,POP就是把数据从堆栈中取出来
PUSH是压栈,POP是从栈顶取出一个值
3.PUSHAD和POPAD
PUSHAD:将所有寄存器压入堆栈
POPAD:将所有寄存器从堆栈中还原
4.堆栈平衡
在函数调用的时候,执行完CALL指令,会将下一行地址压入堆栈,此时进入了函数体,当函数在执行时,可能会PUSH一些值到堆栈中,此时ESP指向的地址就不是CALL的下一行地址,如果此时使用了RET指令,那么返回的地址错误,程序就会出错,也就是堆栈不平衡。
所以在函数执行完毕执行RET指令时,要保证ESP指向的地址是之前CALL指令执行后的下一行地址。
还有一种情况就是当在函数调用中向堆栈中PUSH了数据(如:PUSH 1,PUSH 2),但是调用完函数之后,0x00000001和0x00000002没有用了,占了两个堆栈空间,这也是堆栈不平衡。
在CALL函数之后,内平栈或外平栈
调用约定
调用约定规定了两个东西:
- 函数的参数入栈顺序(从左到右还是从右到左)
- 参数平栈的方式(内平栈外平栈)
汇编指令
1.MOV指令
MOV 寄存器, 寄存器
MOV 寄存器, 内存
MOV [内存地址], 寄存器
MOV [内存地址], 立即数
MOV 寄存器, 立即数
2.MOVZX指令
1 | MOV EAX, 0xFFFFFFFF |
1.将AL赋值给EAX,EAX的值就等于FFFFFF11
2.零扩展,其他位清零
所以EAX最后等于 0x00000011
3.LEA指令
取地址 LEA 寄存器, [内存地址]
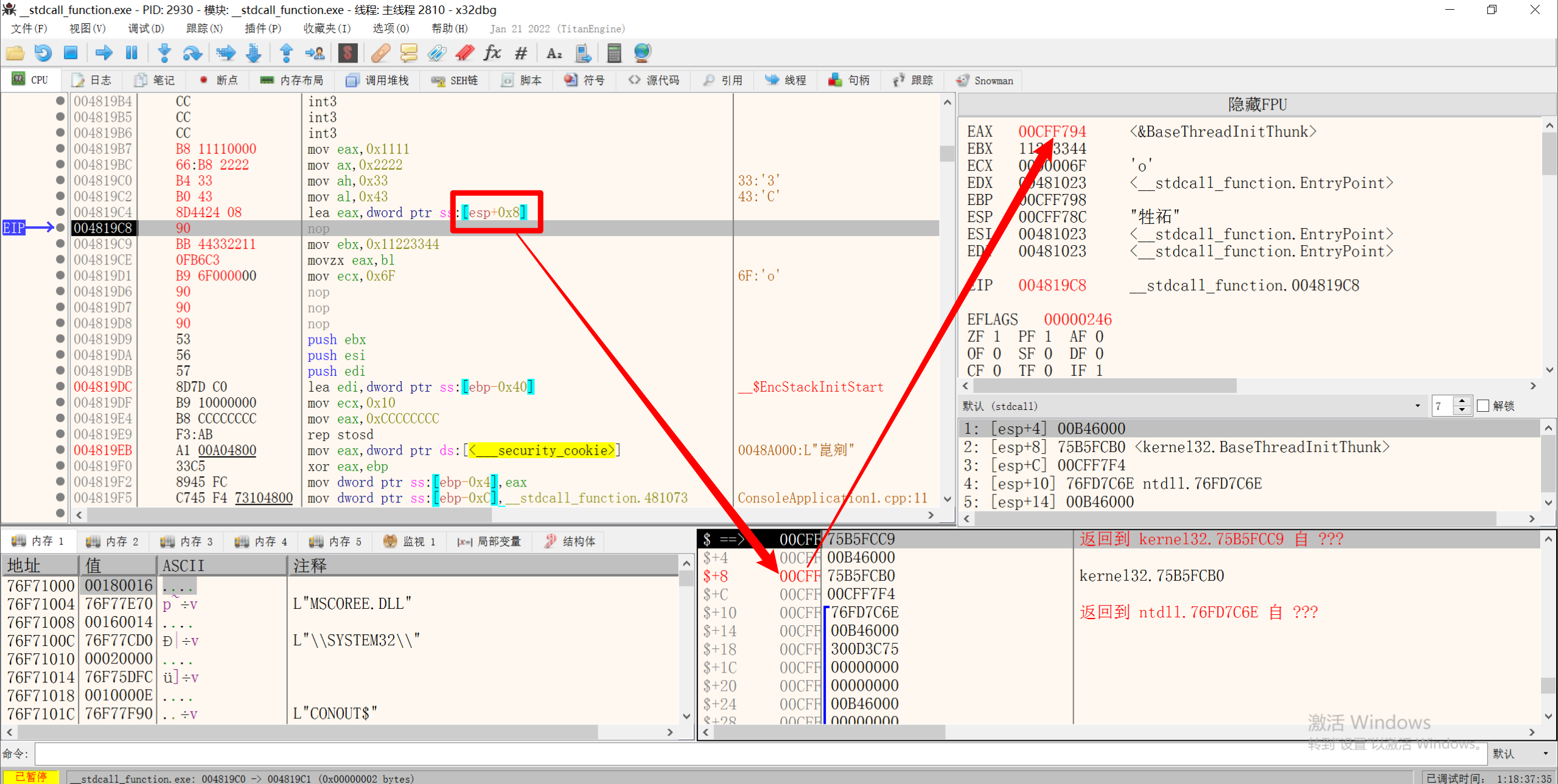
4.XCHG指令 交换指令
交换两个数据
XCHG EAX, EBX => 交换EAX和EBX中的值
5.运算指令
1.ADD指令 加法指令
1 | ADD 操作数1, 操作数2 |
将操作数2加到操作数1
ADD指令不能使用 内存+内存;ADD会影响到进位标志位CF位:无符号整数发生溢出时被置1
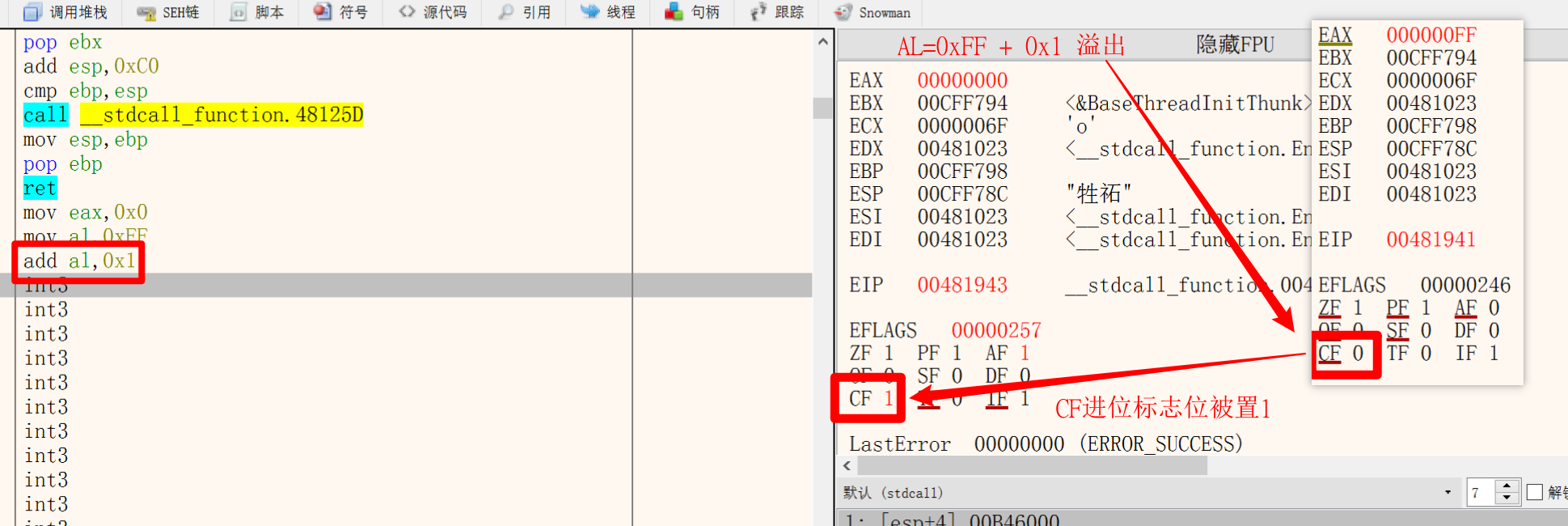
2.ADC指令 进位加指令
1 | ADC 操作数1, 操作数2 |
将操作数2加到操作数1,再加上进位标志位
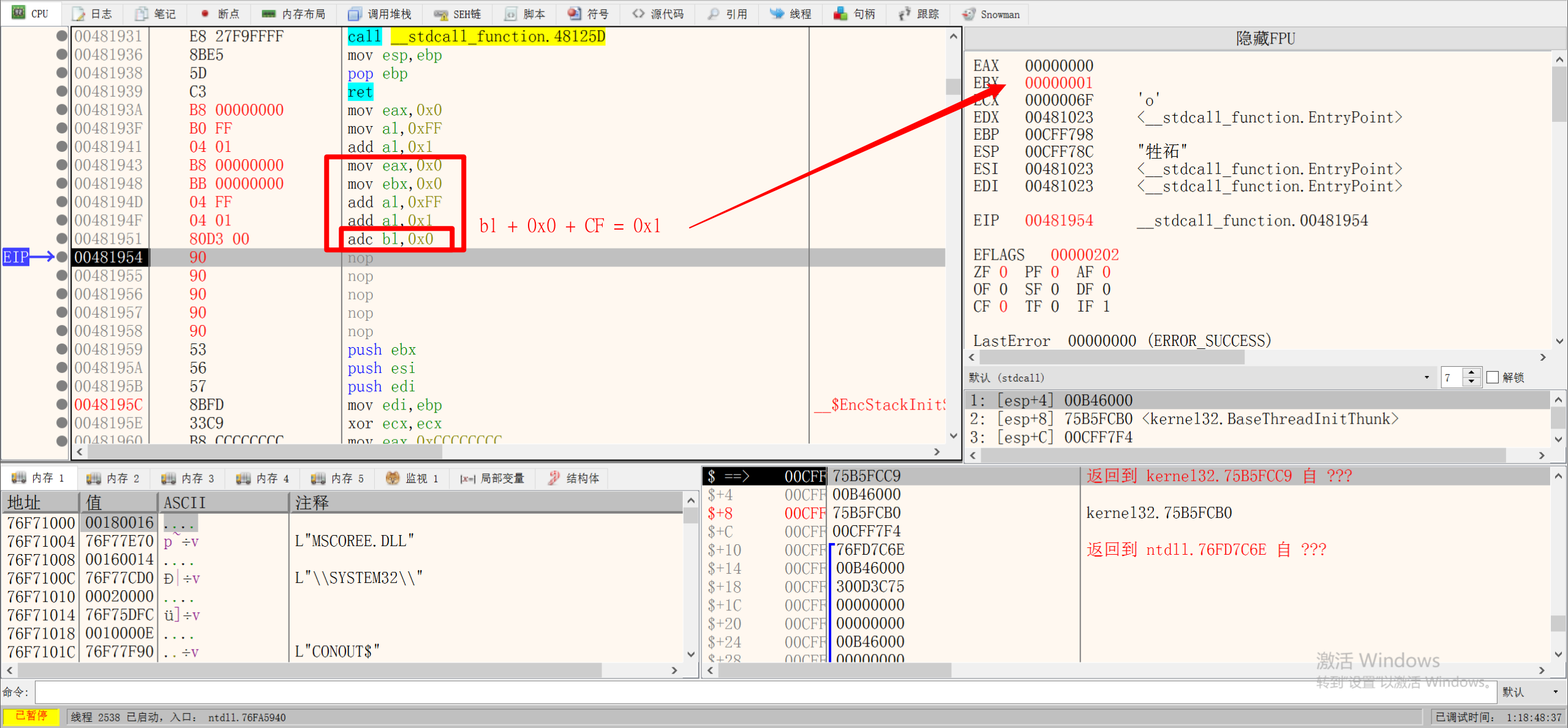
3.SUB指令 减法指令
1 | SUB 操作数1, 操作数2 |
SUB指令也会影响到CF进位标志位,当SUB借位时,CF位也会被置1
4.SBB指令 进位减指令
1 | SBB 操作数1, 操作数2 |
将操作数1减去操作数2,再减去CF进位标志位
5.INC指令 自增指令
自增指令
1 | MOV EAX, 0x0 |
6.DEC指令 自减指令
自减指令
1 | MOV EAX, 0x1 |
7.MUL指令 无符号乘法指令
MUL是单操作数指令 隐藏乘数时EAX
1 | MOV EAX, 0x1234 |

8.IMUL指令 有符号乘法指令
IMUL是双操作数指令
1 | MOV EAX, 0x20 |

会影响到OF溢出标志位:有符号数产生溢出时,OF位被置1
9.DIV指令 无符号除法指令
除法的概念
1 | 5 / 3 = 1 ... 2 |
5是被除数,3是除数,1是商,2是余数

10.IDIV指令 有符号除法指令
与无符号除法基本一样
6.位运算
1.AND指令 与运算指令
操作数1,:reg/mem
操作数2:reg/mem/imm
操作:将操作数1与操作数2进行按位与运算,结果存到操作数1中
2.OR指令 或运算指令
操作数1,:reg/mem
操作数2:reg/mem/imm
操作:将操作数1与操作数2进行按位或运算,结果存到操作数1中
3.XOR指令 异或运算指令
操作数1,:reg/mem
操作数2:reg/mem/imm
操作:将操作数1与操作数2进行按位异或运算,结果存到操作数1中
4.NOT指令 非运算指令
操作数1,:reg/mem
操作数2:reg/mem/imm
操作:将操作数1与操作数2进行按位非运算,结果存到操作数1中
5.SHL指令 左移(LEFT)指令
操作数1:reg
操作数2:imm/CL
操作:左移 (乘2^n)
6.SHR指令 右移(RIGHT)指令
操作数1:reg
操作数2:imm/CL
操作:右移(除以2^n)
7.比较指令
逻辑运算都不会得到运算结果,仅仅设置标志寄存器中的相应标志位,同行==通常都是配合跳转指令,实现汇编中的选择或者循环结构
1.CMP指令
CMP用于比较两个数的大小
操作数1:reg
操作数2:reg/mem/imm
指令结构:CMP 操作数1,操作数2
执行操作:用操作数1减去操作数2,并根据结果设置EFLAGS寄存器中的状态标志
不会设置结果,只会根据结果设置标志寄存器中的值
SF符号位(第七位):设置成结果的最高位,也就是带符号位中的符号位(0表示正数,1表示负数)
ZF零标志位(第六位):当运算结果为0时,该标志位被置1
PF奇偶标志位(第二位):当结果的最低字节中1的个数为偶数(最后的运算结果为偶数)时置1,否则置0
1 | MOV EAX, 0x1 |
执行CMP指令,EAX会被减1,但是运算后的值不会赋值给EAX
执行后,EAX运算的值是0,因此,ZF位被置1
当两数相等时,CMP两个数,ZF位和PF位都会被置1。
当EAX中的值小于后面的数时,EAX-IMM为负数,所以SF符号位会被置1
2.TEXT指令
最常用的功能就是测试某个寄存器的值是不是0
操作数1:reg
操作数2:reg/mem/imm
指令结构 TEST 操作数1,操作数2
执行操作:将操作数1和操作数2进行按位与运算,并根据结果设置SF ZF PF状态标志,然后丢弃结果
一般会写:
1 | TEST EDX, EDX |
用来判断某个寄存器中的值是否为0。当某个寄存器中的值为0时,ZF位会被置1
8.串操作指令
1.MOVS指令 将ESI地址指向的内存复制到EDI指向的内存中
之前的MOV指令不允许MOV内存到内存;MOVS指令可以从一个内存地址移动到另一个内存地址
1 | MOVS BYTE PTR ES:[EDI], BYTE PTR DS:[ESI] ----------> 简写:MOVSB |
前面是目的操作数dest( [EDI] ),后面是源操作数src( [ESI] )
当DF位方向标志位置1时,执行完串操作指令,串操作指令地址会自动自减(高地址向低地址)
当DF位方向标志位置0时,执行完串操作指令,串操作指令地址会自动自增(低地址向高地址)
当MOVSB时,EDI ESI自减(增)一个字节;MOVSW时自减(增)两个字节;MOVSD时自减(增)四个字节
串操作指令用到的寄存器都是EDI和ESI,不能用其他的寄存器。
以C语言为例:
1 | strcpy(dest, src, size) |
EDI就相当于dest,ESI就相当于src,BYTE/WORD/DWORD就相当于size
2.STOS指令 将EAX的值复制到EDI指向的内存地址中
1 | STOS BYTE PTR ES:[EDI] ----------> 简写为STOSB |
STOS指令是将AL/AX/EAX中的值存储到EDI里。
执行完之后,EDI的值也会自增(减),也取决于DF标志位和操作数宽度
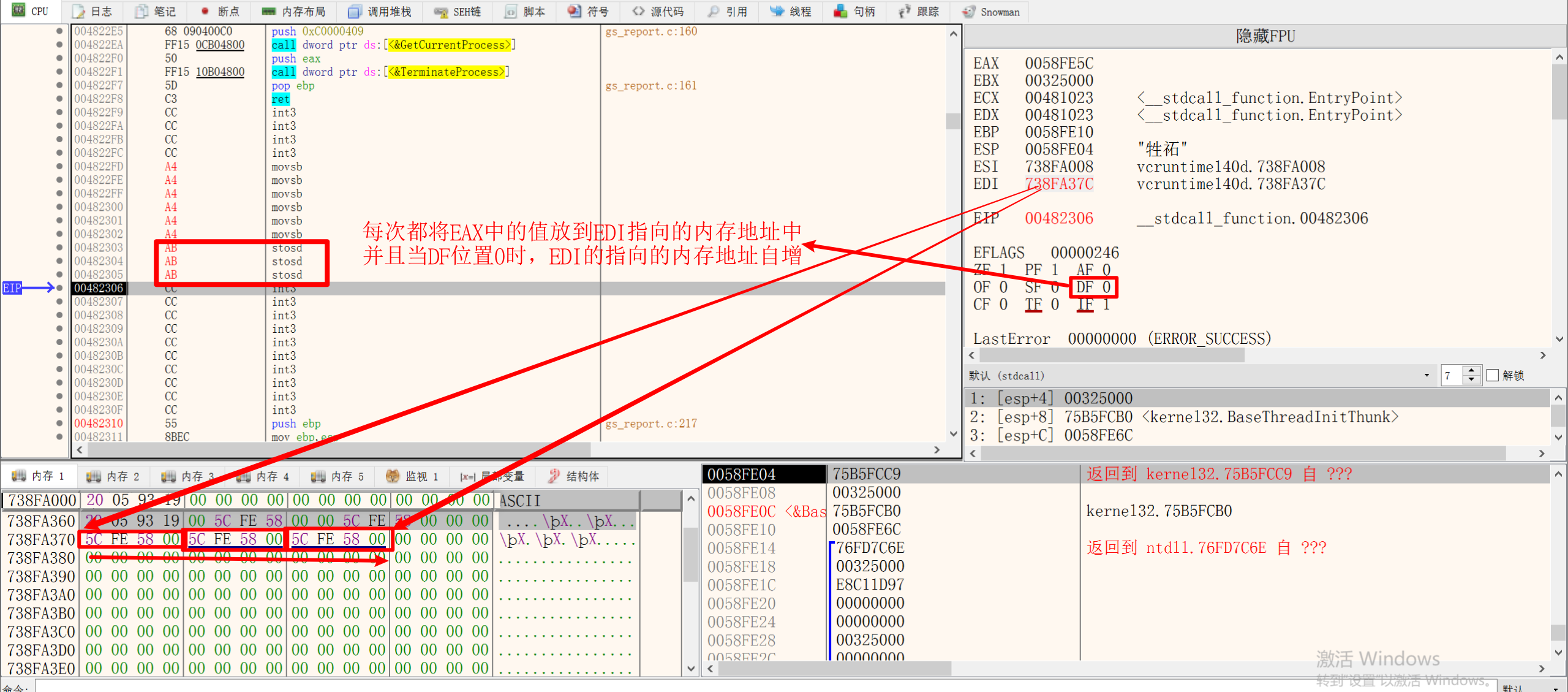
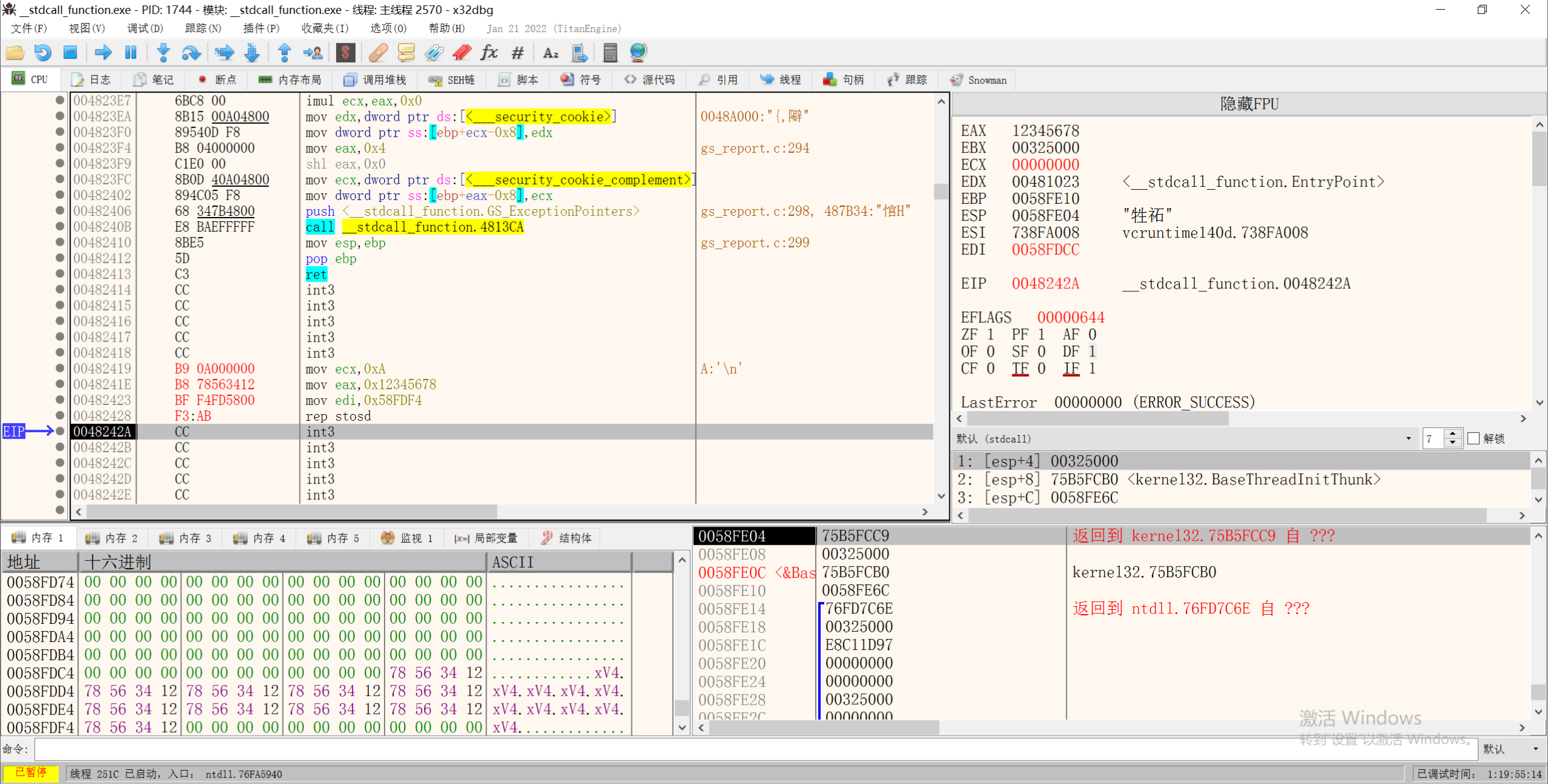
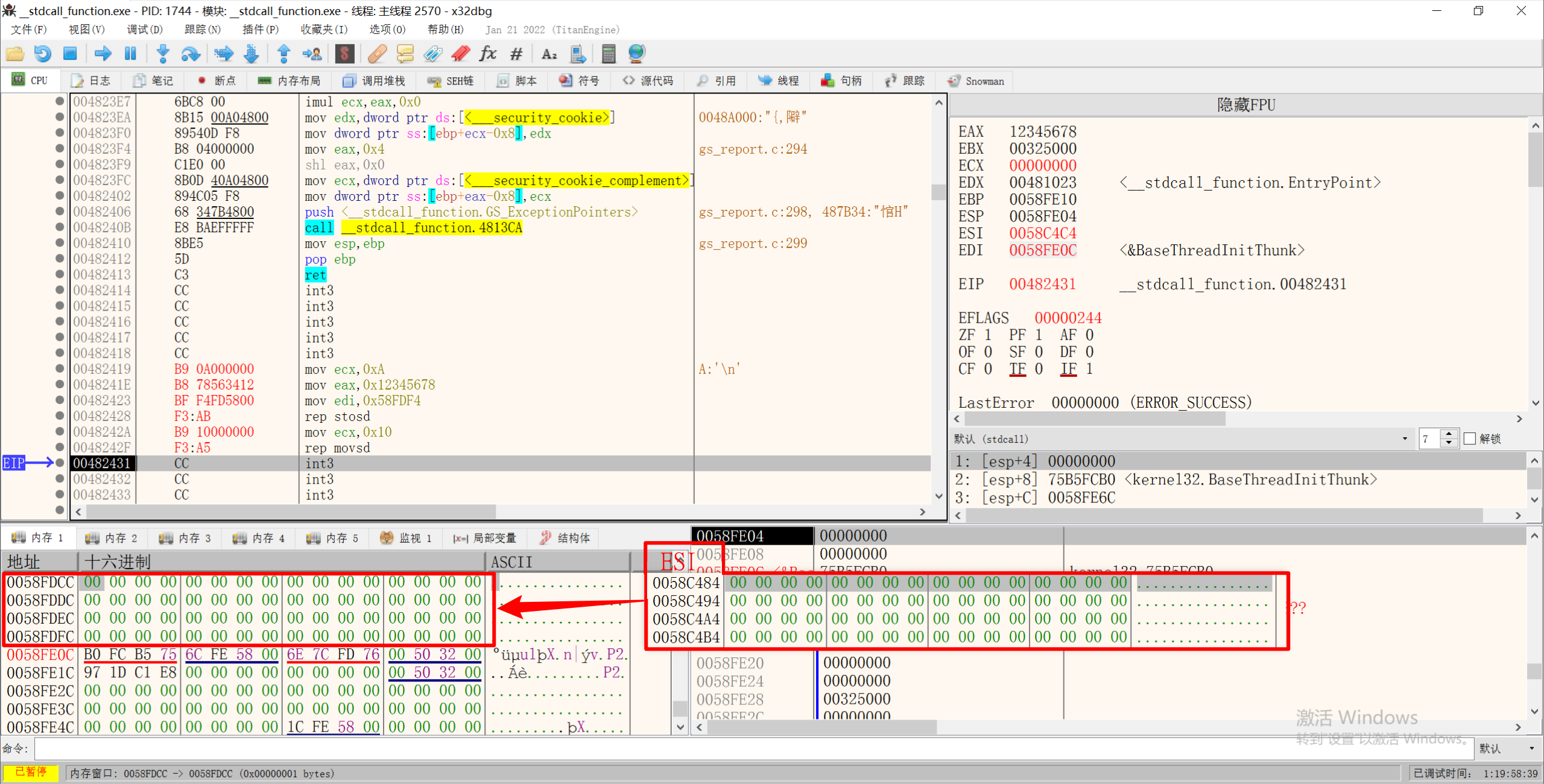
3.REP重复执行指令
按ECX寄存器中指定的次数重复执行字符串指令,并且每执行一次ECX中的数值就会减一。
1 | MOV ECX, 0x10 |
9.修改EIP指令
1.JMP指令
当要修改EIP指针时,不能使用mov eip, 0xFFFFFFFF直接修改EIP的值
但是可以通过JMP指令间接修改EIP。JMP指令表示需要跳转到哪个内存地址
JMP可以直接跟地址,或者跟一个寄存器
1 | JMP 0x00000000 |
2.CALL指令
1 | CALL 0x00000000 |
10.EFLAGS寄存器
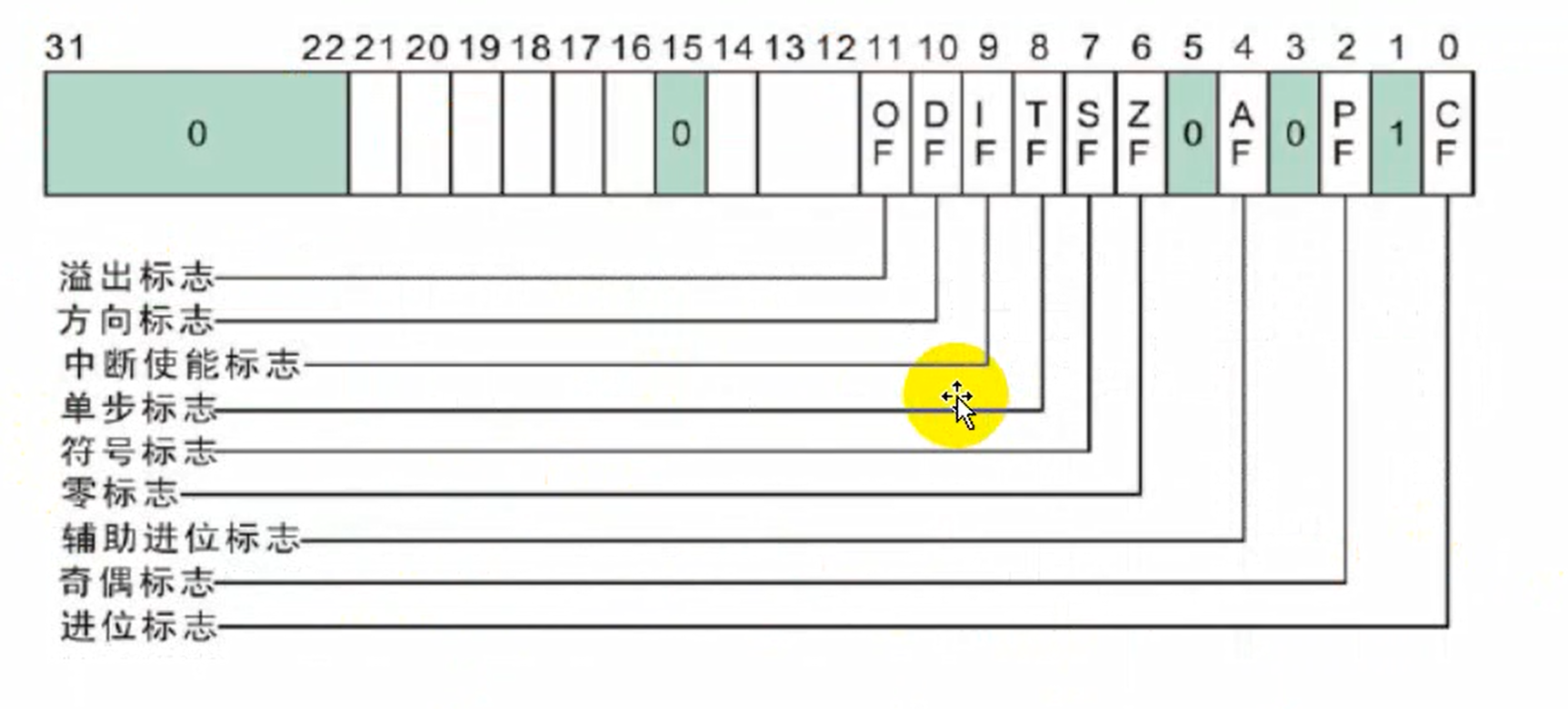
1、进位标志CF(Carry Flag)
进位标志CF主要用来反映运算是否产生进位或借位。如果运算结果的最高位产生了一个进位或借位,那么,其值为1,否则其值为0。
使用该标志位的情况有:多字(字节)数的加减运算,无符号数的大小比较运算,移位操作,字(字节)之间移位,专门改变CF值的指令等。
2、奇偶标志PF(Parity Flag)
奇偶标志PF用于反映运算结果中“1”的个数的奇偶性。如果“1”的个数为偶数,则PF的值为1,否则其值为0。
利用PF可进行奇偶校验检查,或产生奇偶校验位。在数据传送过程中,为了提供传送的可靠性,如果采用奇偶校验的方法,就可使用该标志位。
3、辅助进位标志AF(Auxiliary Carry Flag)
在发生下列情况时,辅助进位标志AF的值被置为1,否则其值为0:
(1)、在字操作时,发生低字节向高字节进位或借位时;
(2)、在字节操作时,发生低4位向高4位进位或借位时。
对以上6个运算结果标志位,在一般编程情况下,标志位CF、ZF、SF和OF的使用频率较高,而标志位PF和AF的使用频率较低。
4、零标志ZF(Zero Flag)
零标志ZF用来反映运算结果是否为0。如果运算结果为0,则其值为1,否则其值为0。在判断运算结果是否为0时,可使用此标志位。
5、符号标志SF(Sign Flag)
符号标志SF用来反映运算结果的符号位,它与运算结果的最高位相同。在微机系统中,有符号数采用补码表示法,所以,SF也就反映运算结果的正负号。运算结果为正数时,SF的值为0,否则其值为1。
6、溢出标志OF(Overflow Flag)
溢出标志OF用于反映有符号数加减运算所得结果是否溢出。如果运算结果超过当前运算位数所能表示的范围,则称为溢出,OF的值被置为1,否则,OF的值被清为0。
7、追踪标志TF(Trap Flag)
当追踪标志TF被置为1时,CPU进入单步执行方式,即每执行一条指令,产生一个单步中断请求。这种方式主要用于程序的调试。
指令系统中没有专门的指令来改变标志位TF的值,但程序员可用其它办法来改变其值。
8、中断允许标志IF(Interrupt-enable Flag)
中断允许标志IF是用来决定CPU是否响应CPU外部的可屏蔽中断发出的中断请求。但不管该标志为何值,CPU都必须响应CPU外部的不可屏蔽中断所发出的中断请求,以及CPU内部产生的中断请求。具体规定如下:
- (1)、当IF=1时,CPU可以响应CPU外部的可屏蔽中断发出的中断请求;
- (2)、当IF=0时,CPU不响应CPU外部的可屏蔽中断发出的中断请求。
CPU的指令系统中也有专门的指令来改变标志位IF的值。
9、方向标志DF(Direction Flag)
方向标志DF用来决定在串操作指令执行时有关指针寄存器发生调整的方向。在微机的指令系统中,还提供了专门的指令来改变标志位DF的值。
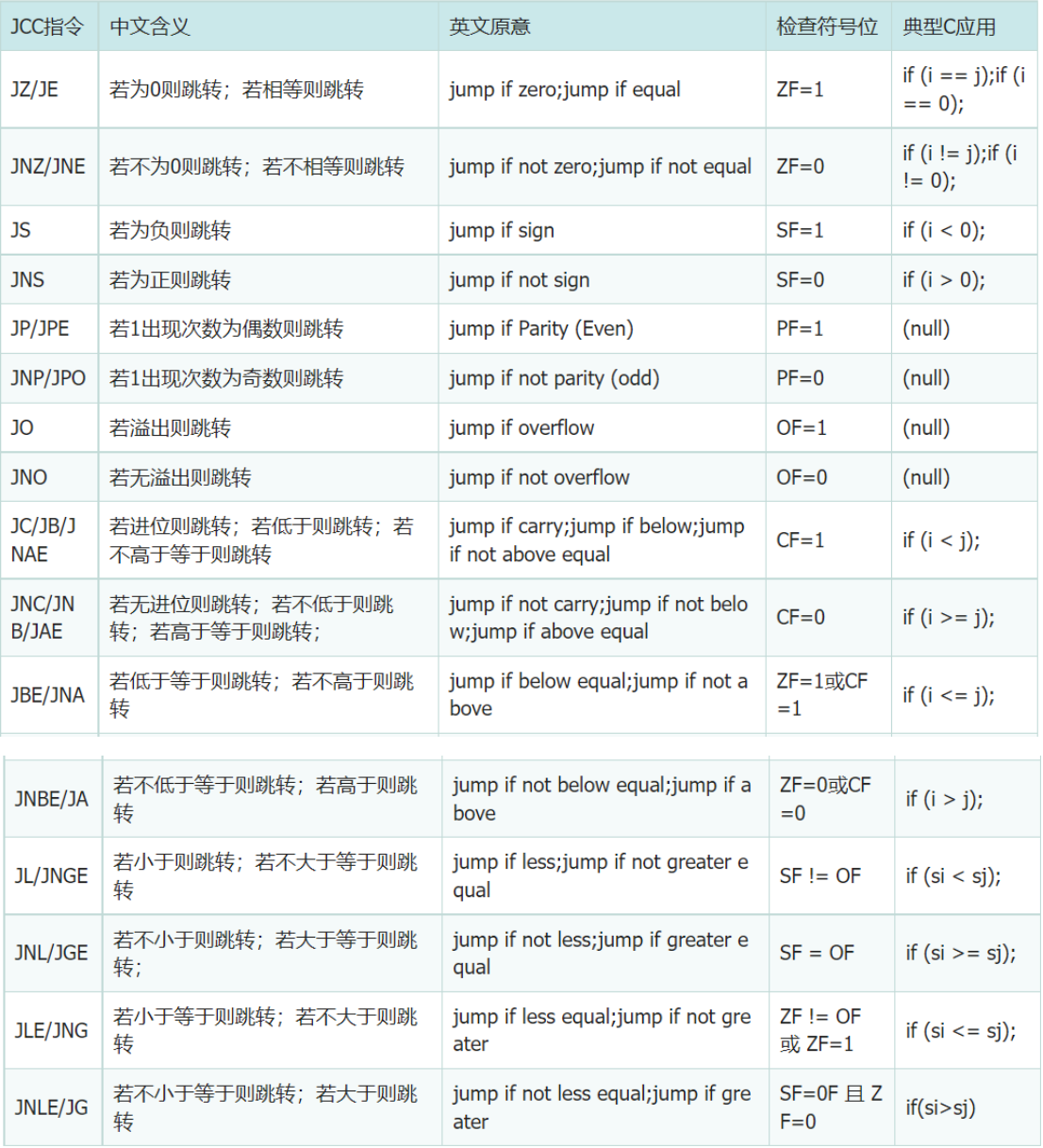
11.JCC指令