
c
C
C基础
一、c语言分步编译
1.预处理:宏定义展开 头文件展开 条件编译 去注释
2.汇编 检查语法 将C语言转变成汇编语言
3.汇编 将汇编语言转成机器语言
4.链接 将C语言依赖库链接到程序中


一步编译
1 | gcc -o hello.exe hello1.c hello2.c |
常见代码异常
1.编辑时异常
2.编译时异常
3.运行时异常
程序执行过程
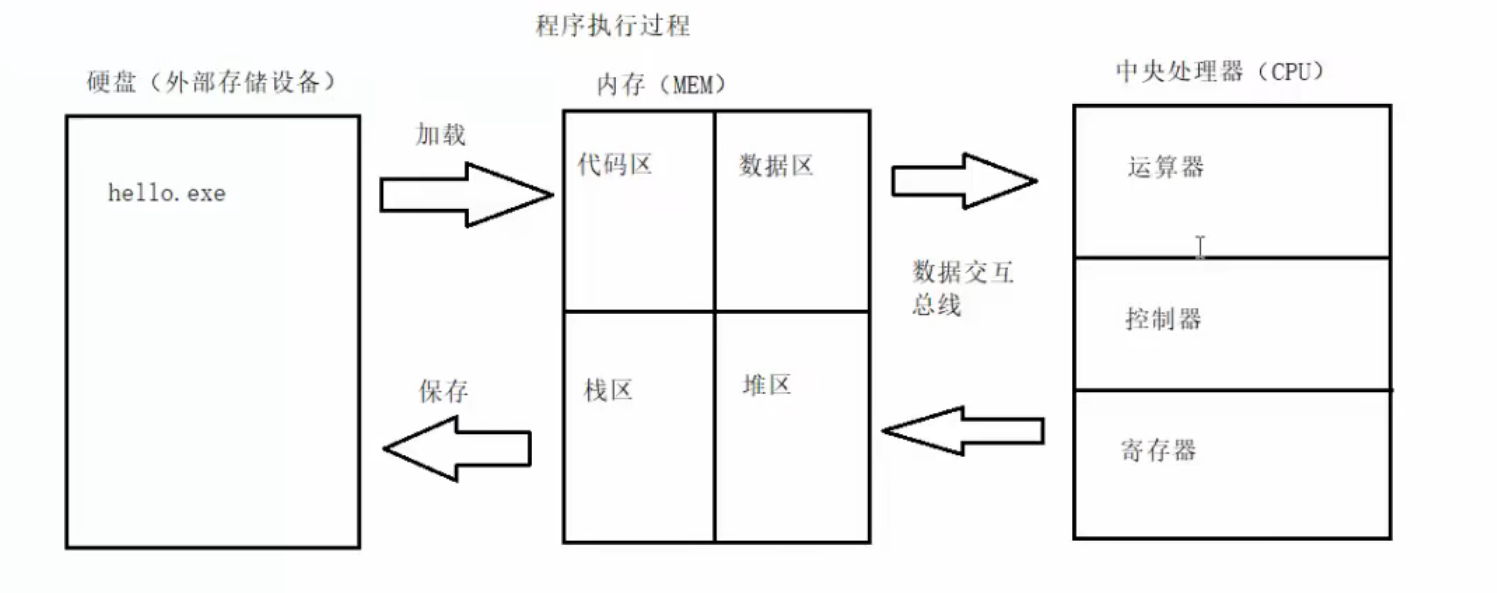
二、汇编语言和程序调试
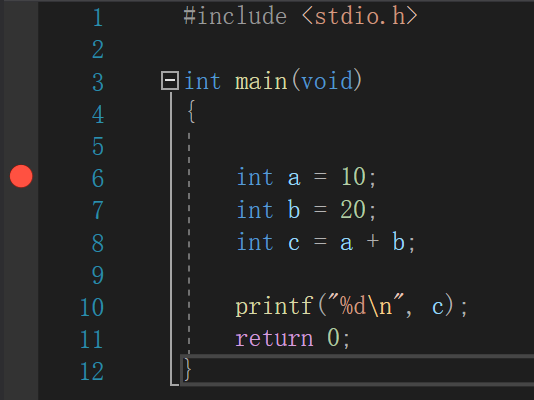
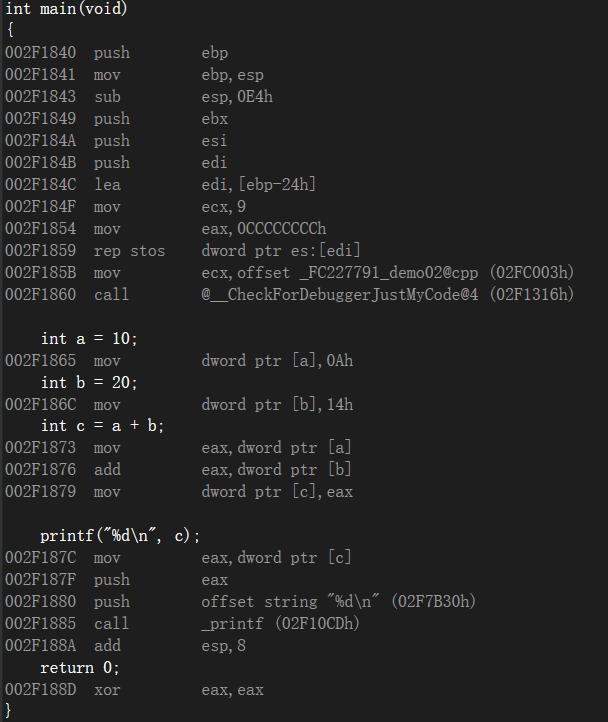
汇编语言
mov 移动
add 添加
push 压栈
pop 出栈
call 调用
eax 32位寄存器
简单的加法计算
1 | mov a, 3 |
快捷键:
断点 F9
调试 F5
逐语句执行 F11
逐过程执行 F10
寄存器名字

三、数据类型
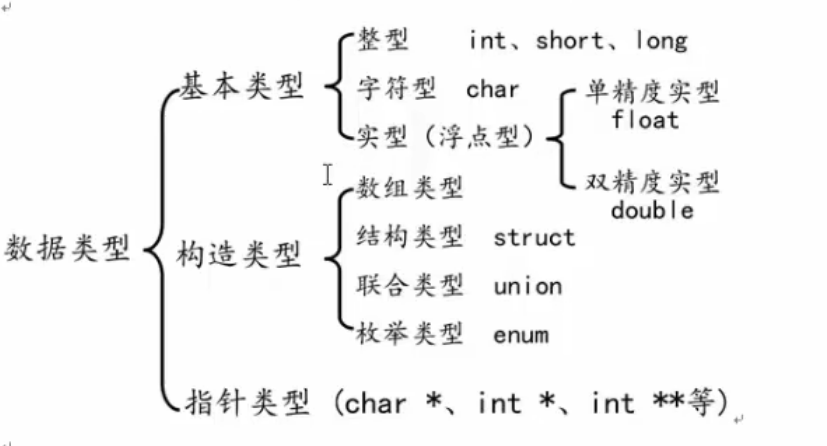
变量与常量
1.定义常量名
const 数据类型 常量名 = 值;(不建议,不安全
#define 常量名 值;
2.整形变量的定义和输出
| 打印格式 | 含义 |
|---|---|
| %d | 输出一个有符号的10进制int类型 |
| %o | 输出8进制的int类型 |
| %x | 输出16进制的int类型,字母以小写输出 |
| %X | 输出16进制的int类型,字母以大写输出 |
| %u | 输出一个10进制的无符号数 |
3.进制计算
整形输入
1 | int main(void) |
出现报错:
error C4996: ‘scanf’: This function or variable may be unsafe. Consider using scanf_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS
解决scanf()安全问题
使用
1 |
或
1 |
short、int、long、long long
| 数据类型 | 占用空间 |
|---|---|
| short | 2字节 |
| int | 4字节 |
| long | Windows为4字节,Linux为4字节(32位),8字节(64位) |
| long long | 8字节 |
输出时的占位符:

sizeof计算数据类型大小

字符型:char
定义:char 数据名 = ‘字符’;
sizeof(char) 1字节
对应ASCII码表
float double
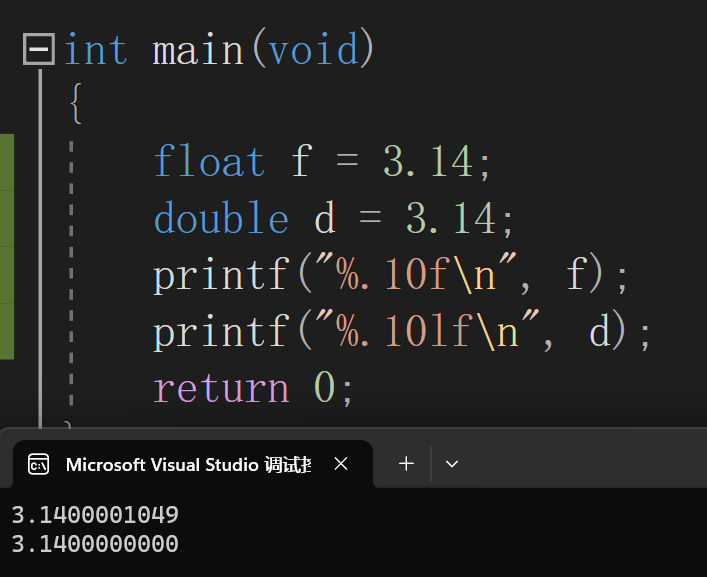
float和double认为保留小数点后6位是精确的
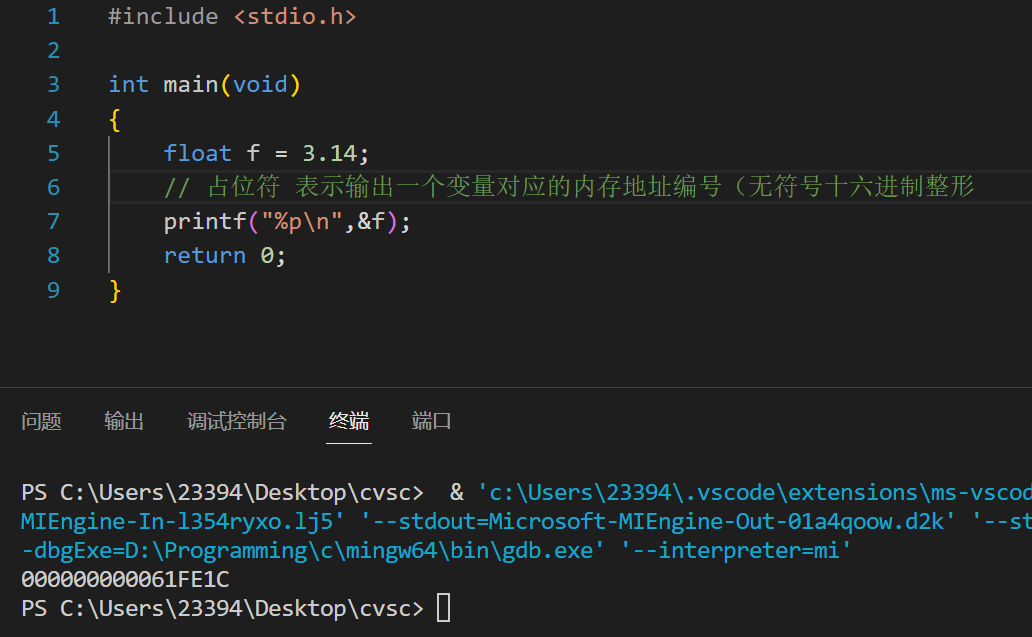
打印地址编号
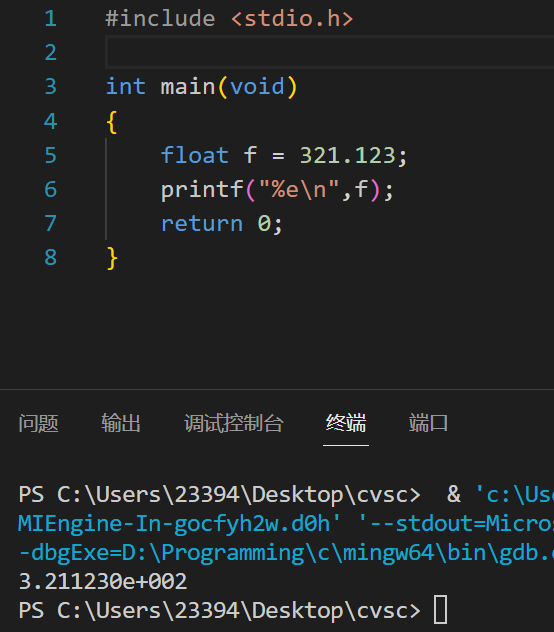
科学计数法打印float:占位符 %e
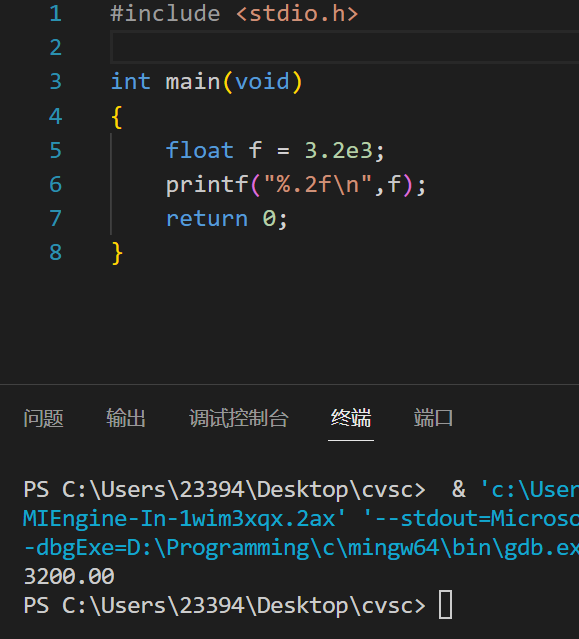
将科学计数法转换成正常浮点数
四、进制相互转化
二进制十进制互转:转低进制,除二反序取余法,转高进制,权值法

八进制十进制互转:除八反序取余法,权值法

十进制十六进制互转:除十六反序取余法

进制转变简单方法
二进制十进制互转:8421法则
① 11101 16+8+4+0+1=29
② 29 29不包含32,从16开始,29-16=13,13包含8,13-8=5,5包含4,5-4=1
所以1 4 8 16分别对应1 100 1000 10000,将这四个数相加得11101
二进制八进制互转:三位一隔
① 11001000100111110101010 从后向前三位一隔
11 001 000 100 111 110 101 010
3 1 0 4 7 6 5 2
所以11001000100111110101010 => 31047652
② 31047652 将每一位数转换成三位二进制数
3 1 0 4 7 6 5 2
11 001 000 100 111 110 101 010
所以31047652 => 所以11001000100111110101010
二进制十六进制互转:四位一隔
① 7 3 a b c
0111 0011 1010 1011 1100
②0111 0011 1010 1011 1100
7 3 a b c
五、计算机内存数值存储方式
原码:
①最高位作为符号位,0为正,1为负
②其他数值部分就是数值本身绝对值的二进制数
③负数是在绝对值的基础上将最高位变为1
| +15 | 0000 1111 |
| -15 | 1000 1111 |
| +0 | 0000 0000 |
| -0 | 1000 0000 |
原码表示法简单易懂,与带符号数本身转换比较方便,只要符号还原即可,但是,当两个正数相减或不同符号数相加时,必须比较两个数哪一个绝对值大,才能决定谁减谁,才能决定结果是正是负,所以原码不便于加减运算。
反码:
①对于正数,反码与原码相同
②对于负数,符号位不变,其他部分取反(1,0)
| +15 | 0000 1111 |
| -15 | 1111 0000 |
| +0 | 0000 0000 |
| -0 | 1111 1111 |
反码运算起来也不方便,通常用来作为求补码的中间过度。
补码:
①对于正数,原码、反码、补码相同
②对于负数,补码为它的反码+1
③补码符号位不动,其他位求反,最后整个数+1,得到反码
计算:
①56 - 45 => 56 + (-45)
原码:0011 1000
反码:0011 1000
补码:0011 1000
原码:1010 1101
反码:1101 0010
补码:1101 0011
56补码 0011 1000
-45补码 1101 0011
56 - 45 补码:1 0000 1011
多一位,将第一位舍弃
得0000 1011 补码和原码相同 => 11
②26 - 68
原码:0001 1010
反码:0001 1010
补码:0001 1010
原码:1100 0100
反码:1011 1011
补码:1011 1100
26补码:0001 1010
-68补码:1011 1100
26 + (-68)
补码:1101 0110
反码:1101 0101
原码:1010 1010 => -42
数据区间
8bit:-2^7 ~ 2^7-1 -128~127
32bit:-2^31 ~ 2^31-1 -2,147,483,648~2,147,483,647
64bit:-2^63 ~ 2^63-1 -9,223,372,036,854,775,808~9,223,372,036,854,775,807
无符号 数据存储在计算器中不存在符号位
unsigned char 0~255
最大值:1111 1111 2^8-1
最小值:0000 0000 0
unsigned int 0~4,294,967,295
最大值:1111 1111 1111 1111 1111 1111 1111 1111 2^32-1=4,294,967,295
最小值:0000 0000 0000 0000 0000 0000 0000 0000 0
数据溢出
当超出一个数据类型能够存放的最大范围时,数值会溢出
有符号位 最高位溢出的区别:符号位溢出会导致数的正负发生改变,但最高位溢出会导致最高位丢失
如: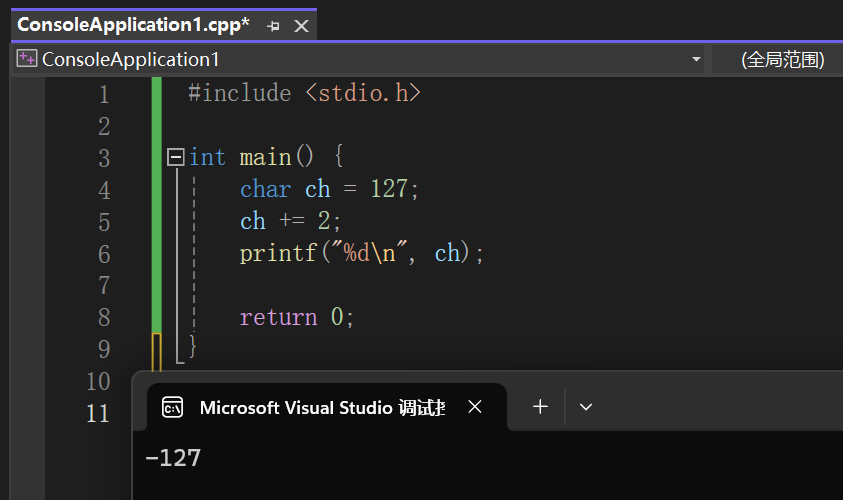
类型限定
| 限定符 | 含义 |
|---|---|
| extern | 声明一个变量,extern声明的变量没有建立存储空间。extern int a;//变量在定义的时候创建存储空间 |
| const | 定义一个常量,常量的值不能修改。 const int a = 10; |
| Volatile | 防止编译器优化代码 |
| register | 定义寄存器变量,提高效率。这是建议型指令,而不是命令型指令,如果CPU有空闲寄存器,那么register生效 |
printf函数和putchar函数
printf是输出一个字符串,putchar输出一个char
printf格式字符:
| 打印格式 | 对应数据类型 | 含义 |
|---|---|---|
| %d | int | 接收整数值并将他表示为有符号的十进制整数 |
| %hd | short int | 短整数 |
| %hu | unsigned short | 无符号短整数 |
| %o | unsigned int | 无符号8进制整数 |
| %u | unsigned int | 无符号10进制整数 |
| %x,%X | unsigned int | 无符号16进制整数,x对应abcdef,X对应ABCDEF |
| %f | float | 单精度浮点数 |
| %lf | double | 双精度浮点数 |
| %e,%E | double | 科学计数法表示的数,e的大小写代表输出是使用的E的大小写 |
| %c | char | 字符型。可以把输入的数字按照ASCII码相应转换为对应的字符 |
| %s | char * | 字符串。输出字符串中的字符直至字符串中的空字符 (字符串以‘\0结尾,这个\0即空字符’) |
| %p | void * | 以16进制形式输出指针 |
| %% | % | 输出一个百分号 |
printf附加格式:
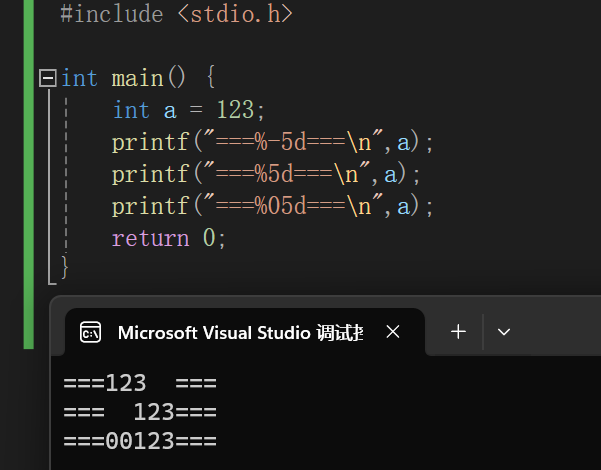
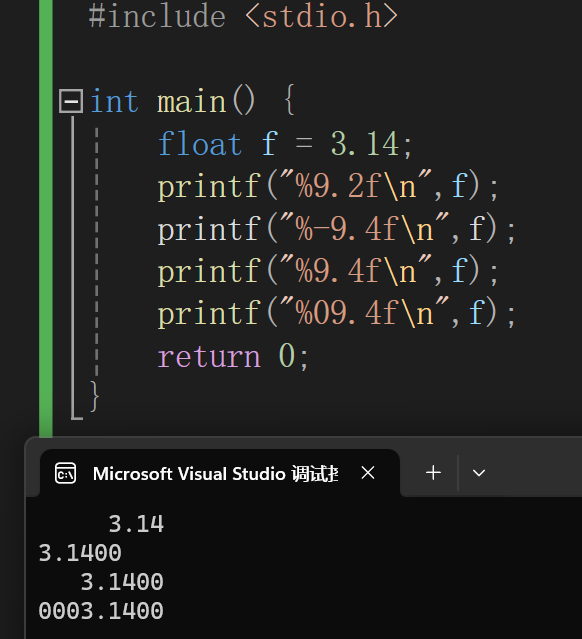
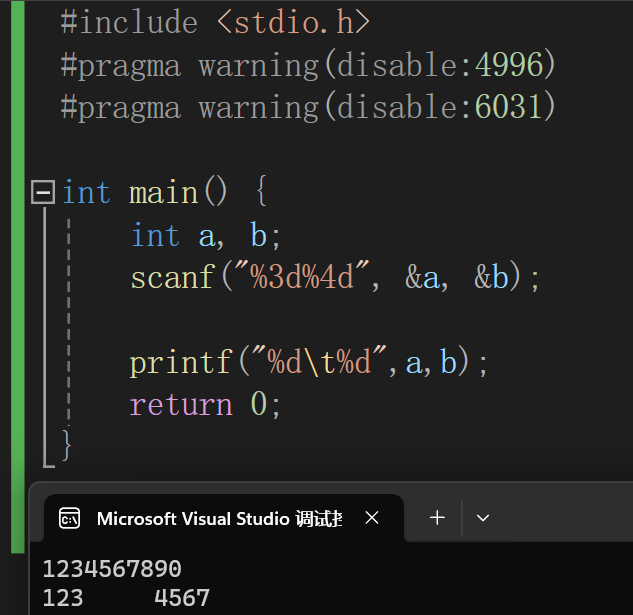
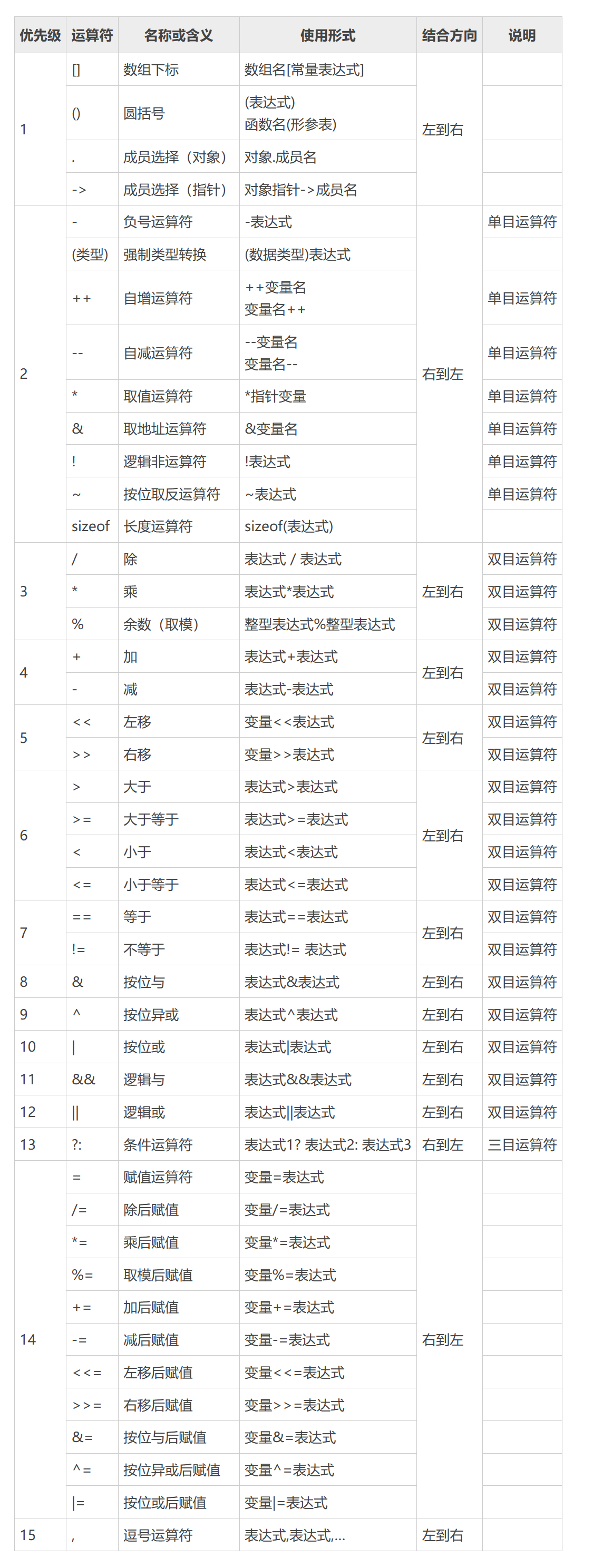
运算符优先级别
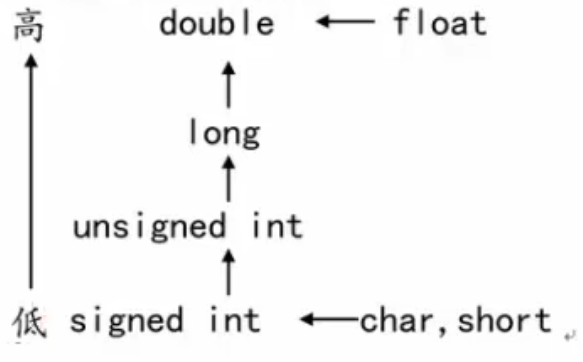
数据类型转换
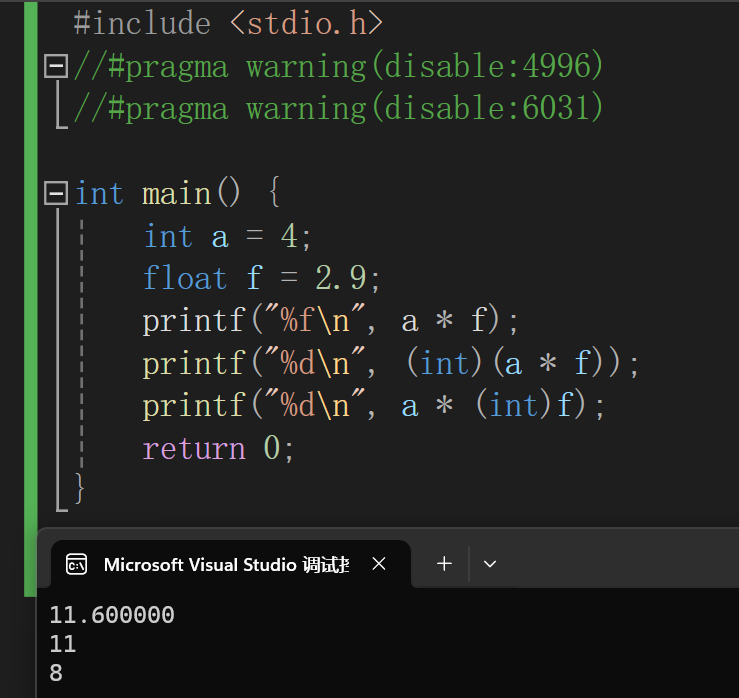
强制转换
格式:(数据类型)变量名;
类型转换原则:占用内存字节数少(值域小)的类型,向占用内存字节数多(值域大)的数据类型转换,以保证精度不降低。
从占用字节多的数据类型向占用字节数少的数据类型转换时,会降低精度:
程序流程结构
1.分支结构
if结构
1 | if(condition) |
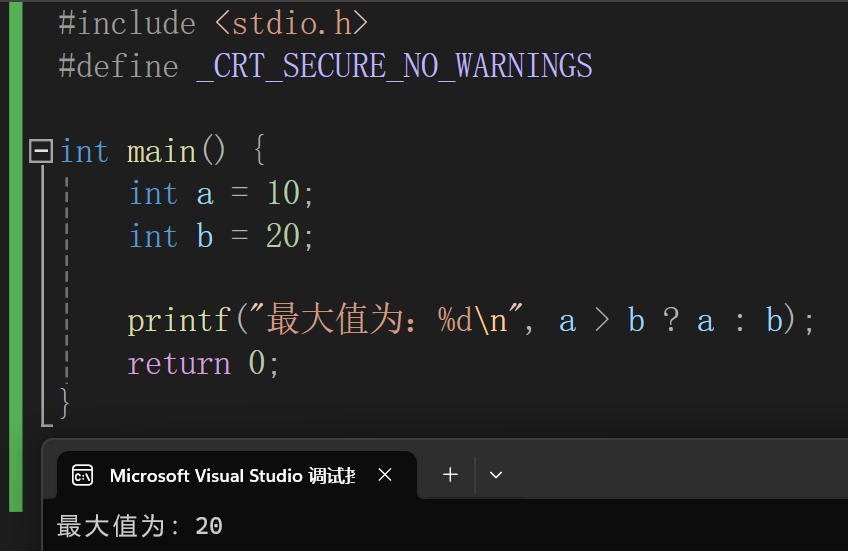
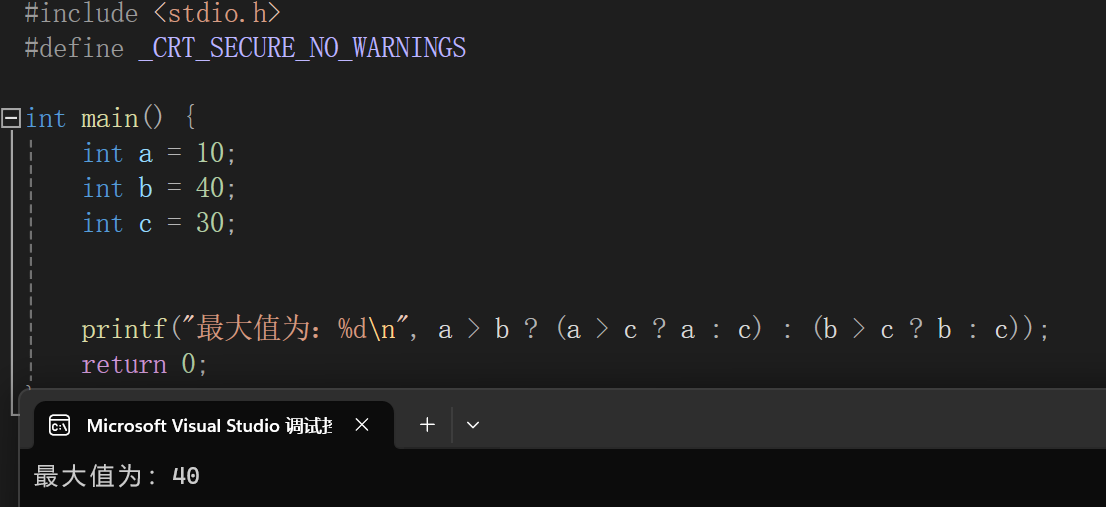
三目运算符
1 | 表达式1?表达式2:表达式3 |
如果表达式1为真,则用表达式2作为结果,为假用表达式3作为结果
三目运算符的嵌套
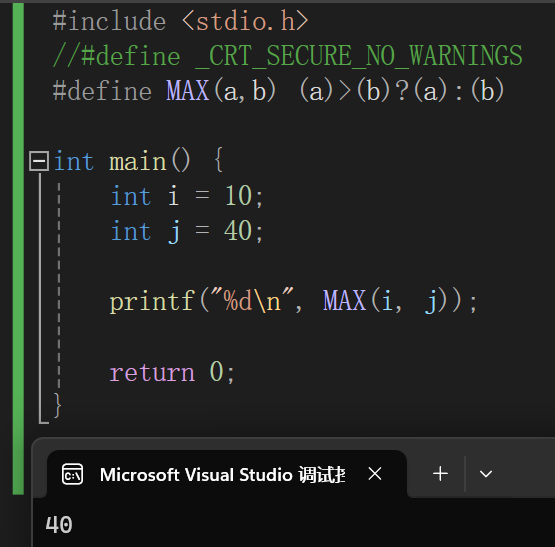
使用#define宏定义表达式
2.选择结构
1 | switch (switch_on) |
3.循环结构
while循环结构
1 | while(condition){ |
1 | do{ |
do…while可以用于第一句执行条件为假,当第一句执行完后条件为真再进行后面循环的情况。
for循环结构
1 | for (int i = 0; i < value; i++) |
for循环嵌套实例:时钟
1 |
|
实例:九九乘法表
1 |
|
4.跳转语句
break语句
1.在switch中,跳出case并结束switch
2.在循环中结束循环
3.在嵌套循环中,跳出最近循环
continue语句
结束本次循环,跳到下一次循环
如只输出偶数:
1 |
|
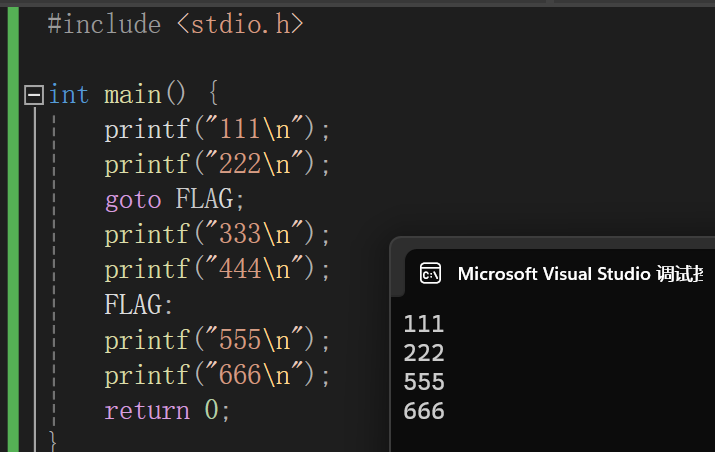
goto语句
六、数组与字符串
概述
定义数组:数据类型 数组名[元素个数] = {值1,值2,值3,……};
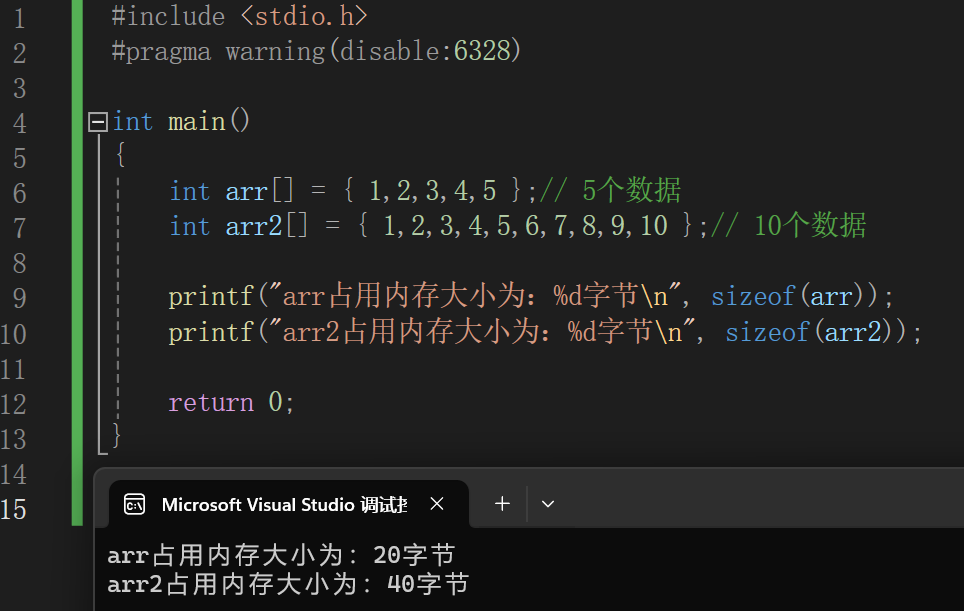
数组在内存中存储方式和大小
数组存储在内存中连续的相同类型鹅变量空间。同一个数组所有的成员都是相同的数据类型,同时所有的成员在内存中的地址是连续的。因此可以通过地址找到数组的下一个
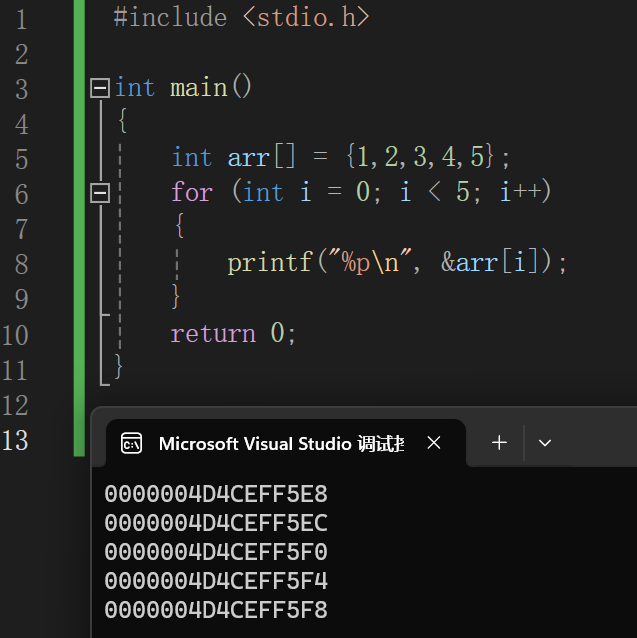
数组名是一个地址常量 指向数组首地址的常量
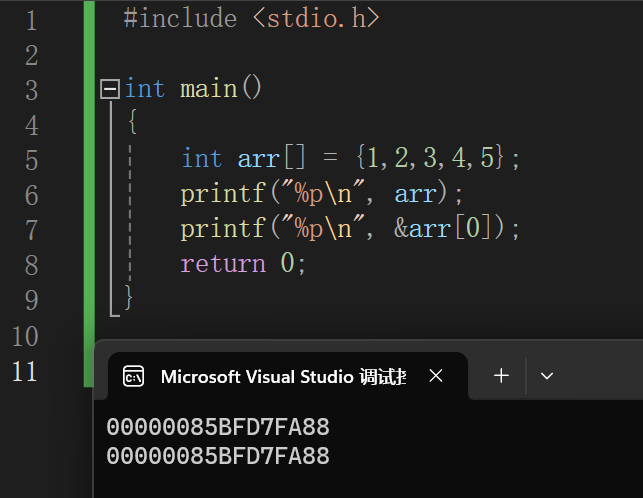
数组占用内存的大小与数据个数和类型有关
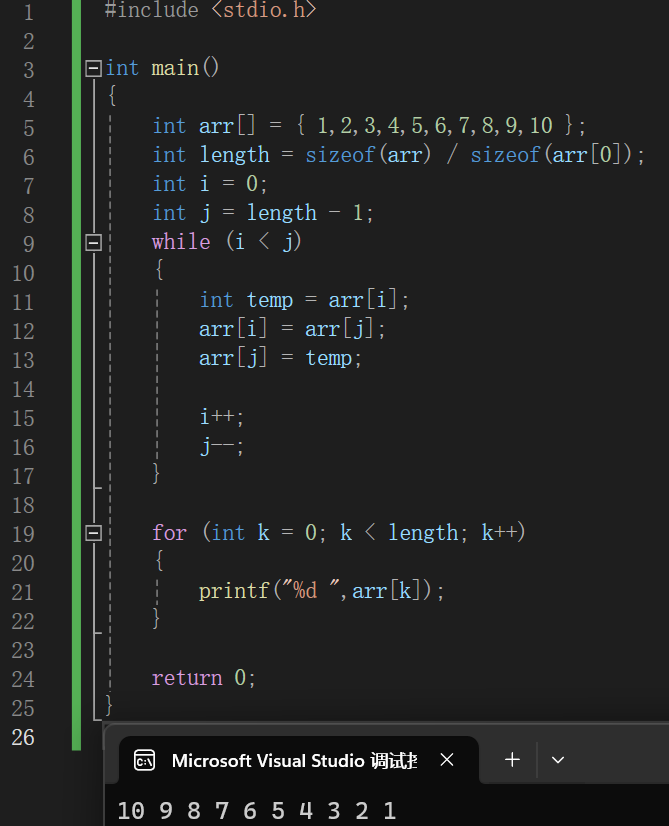
数组逆置
1 |
|
冒泡排序
1 |
|
二维数组
判断二维数组行数和列数:
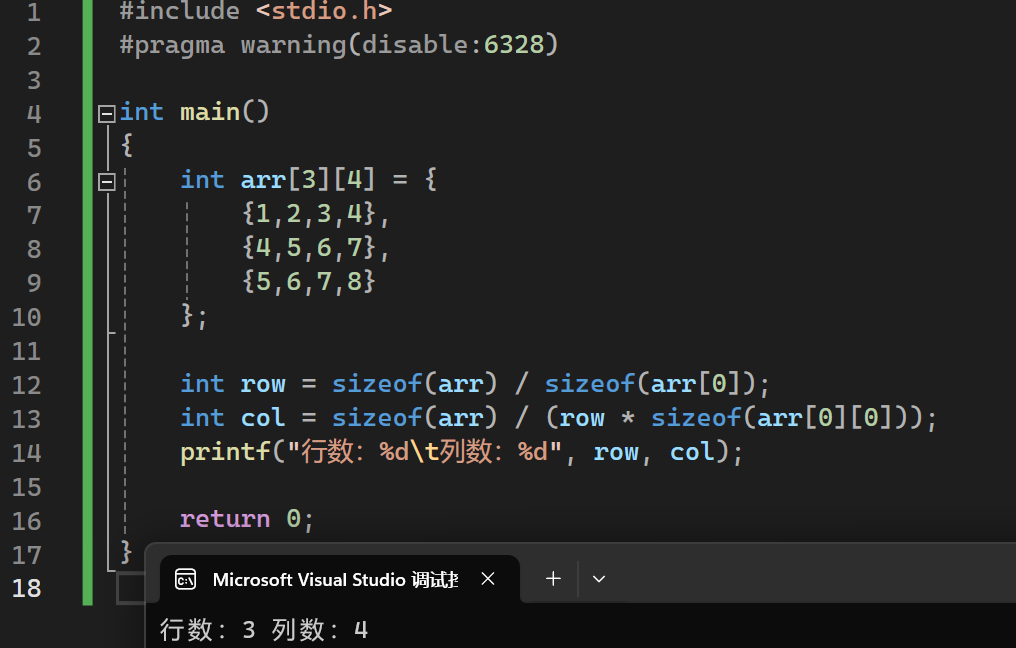
** 打印二维数组 **
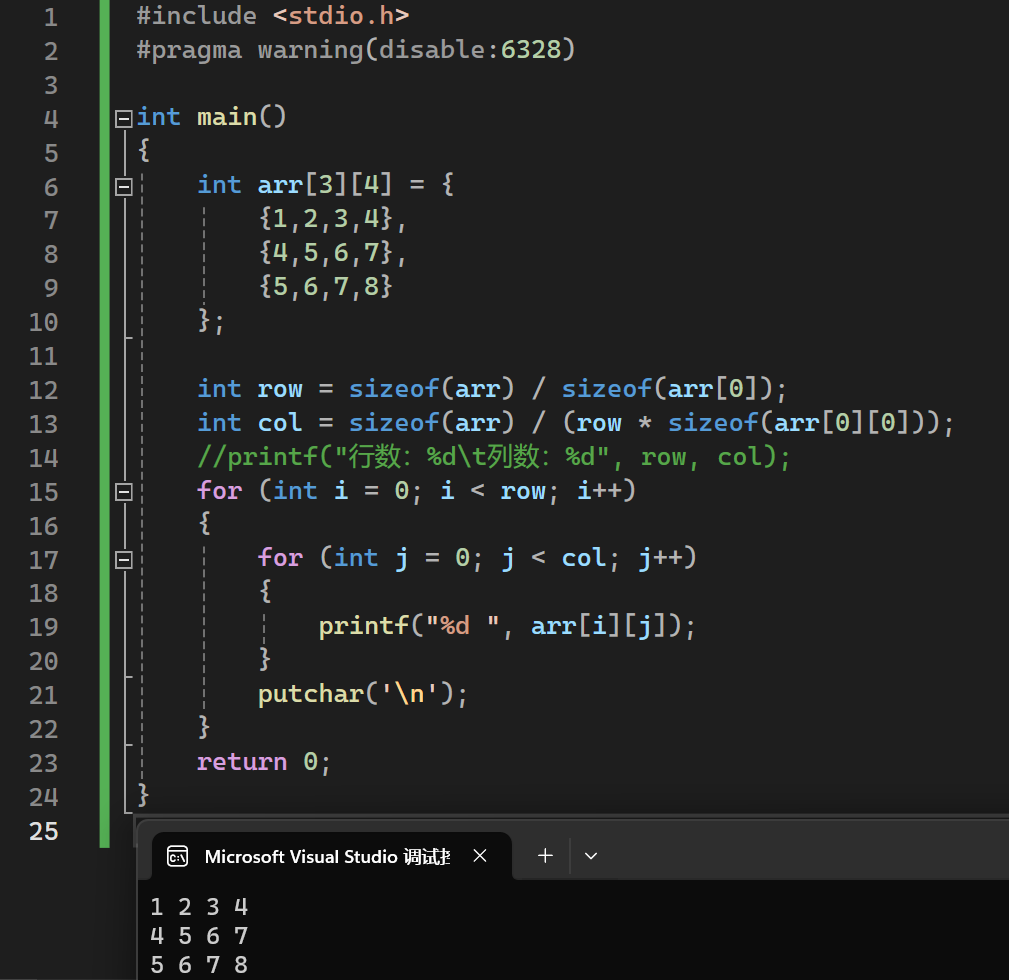
多维数组
三维数组
1 | 数据类型 数组名[层][列][行] |
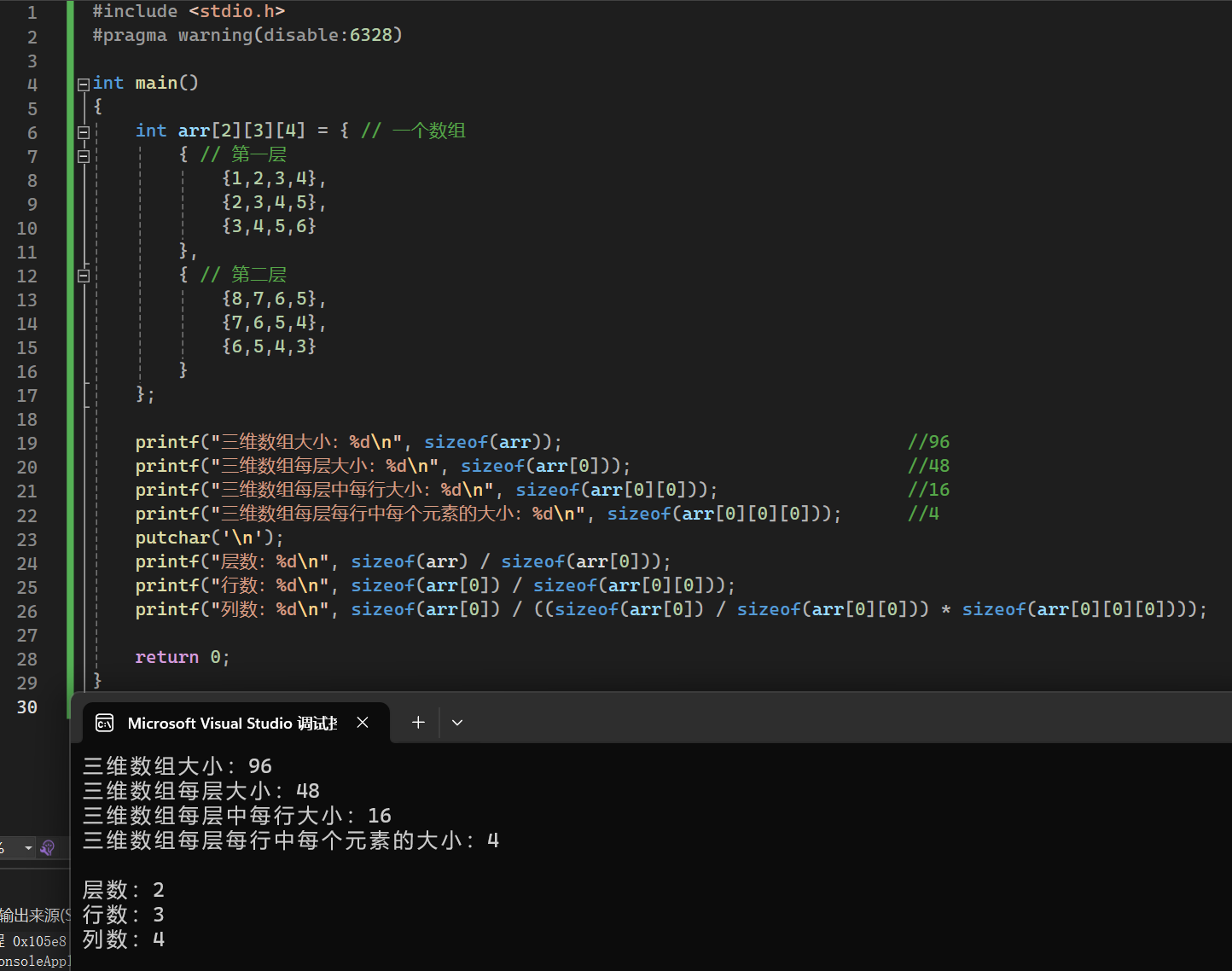
1 |
|
字符数组
定义字符数组:
1 | char 数组名[元素个数] = {'h','e','l','l','o'}; |
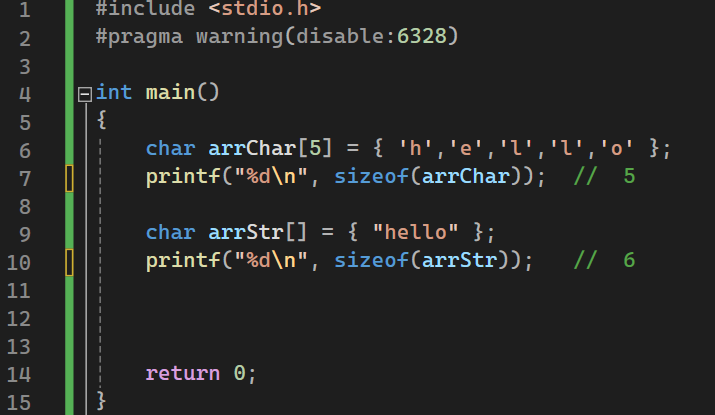
字符串最后一个字符为 \0,所以有6位。
字符串拼接
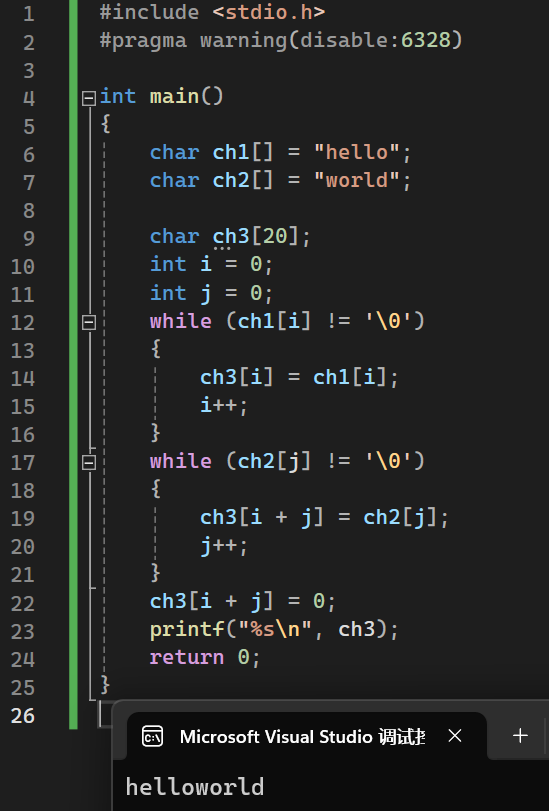
1 |
|
字符串
字符串与字符的区别
C语言中没有字符串这种数据类型,可以通过char的数组来替代:
字符串一定是一个char的数组,但char的数组未必是字符串;
数字0(和字符’\0’等价)结尾的char数组就是一个字符串,但如果char数组没有以数字0结尾,那么就不是一个字符串,只是普通字符数组,所以字符串是一种特殊的char的数组。
字符串的输入与输出
gets()
1.功能:从标输入读入字符,并保到指定的内存间,直到出现换行符或读到文件结尾为止。
2.gets(str)与scanf(“%s”,str)的区别:
gets(str)允许输入的字符串含有空格
scanf(“%s”,str)不允许含有空格
但是scanf()可以通过正则表达式输入带空格的字符串:
1 | scanf("%[^\n]", ch) |
意思是接收非回车以外的所有数值。
注意:由于scanf()和gets()无法知道字符串s大小,必须遇到换行符或读到文件结尾为止才接收输入,因此容易导致字篮颗组画界(缓冲区溢出)的情况
fgets()
1.功能:从stream指的文件内读入字符,保存轾到所指定的内存空间,直到出现换行字符、读到文件结尾或已读了size-1个字符为止,最后会自动加上字符’\0’作为序符束。
可以接受空格。
2.参数:
s:字符串
size:指定最大读取字符串的长度(size - 1)
stream:文件指针,如果读键盘输入的字符串,固定写为stdin
1 | int main() |
puts()
功能:标准设备输出s字符串,在输出完成后自动输出一个’\n’
fputs()
1.功能:将str所指定的字符串写入到stream指定的文件中,字符串结束符’\0’ 不写入文件。
2.参数:
str:字符串
stream:文件指针,如果把字符串输出到屏幕,固定写为stdout
1 | int main() |
strlen()
1.功能:计算字符串长度(有效长度),计算的是第一个\0之前的长度,不包含\0
2.返回值:返回值为unsigned int类型。
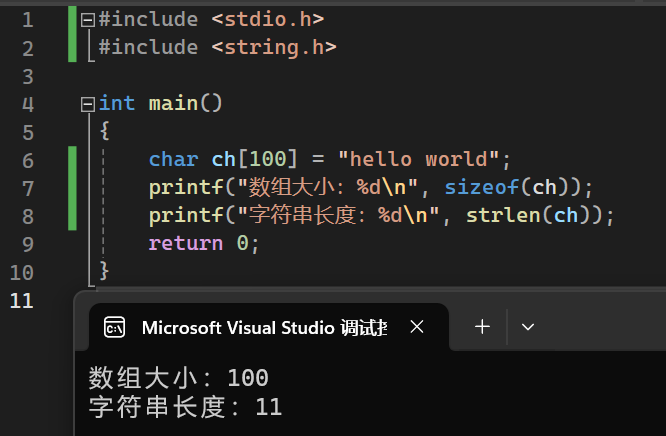
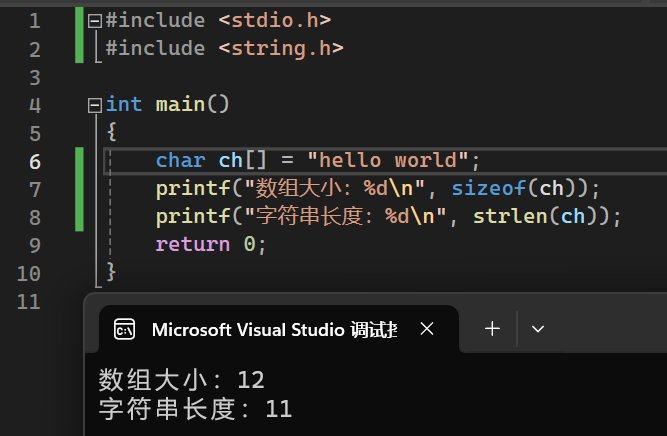
↑↑↑↑↑↑↑ 12,因为还有一个\0
使用strlen()函数要导入头文件 #include <string.h>
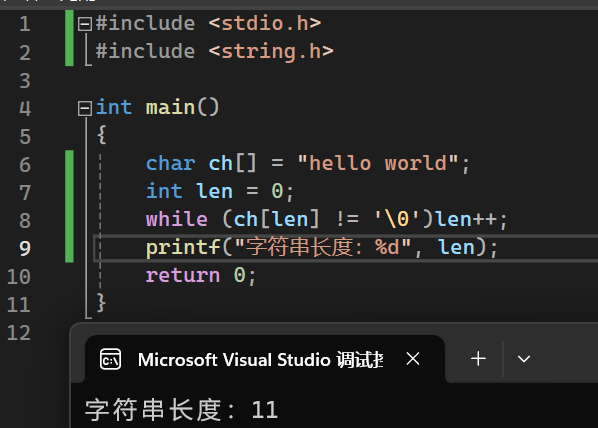
自己实现字符串长度计算
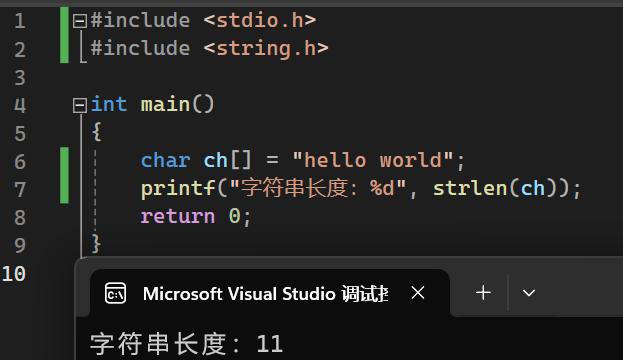
strlen()
七、函数
函数调用:产生随机数
当调用函数时,需要关心5要素:
头文件:包含指定的头文件
函数名字:函数名字必须和头文件声明的名字一样
功能:需要知道此函数能干啥后才调用。
参数:参数类型要匹配
返回值:根据需要接收返回值。
1 |
|
1 |
|
1 |
|
直接产生的随机数
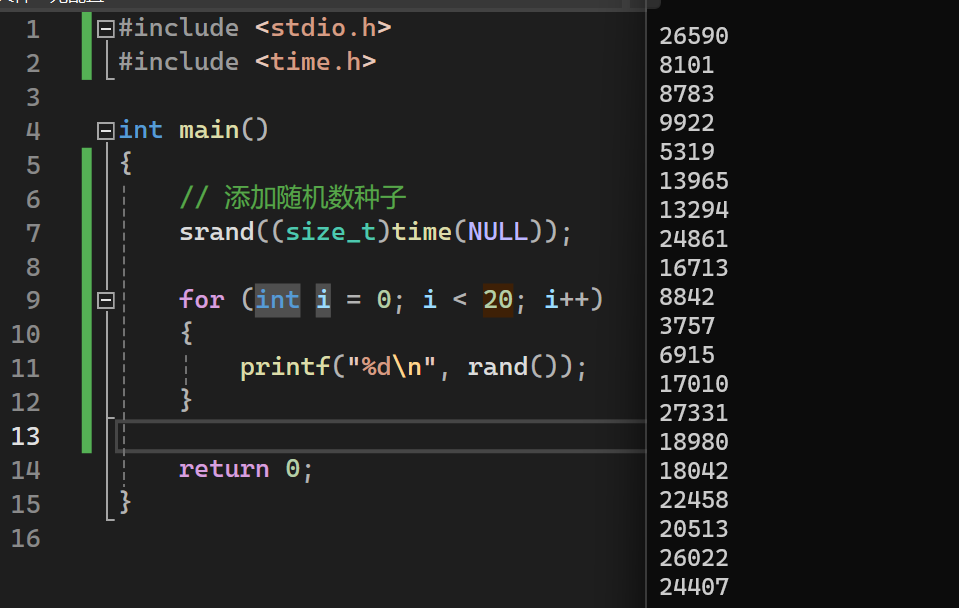
1 |
|
生成特定范围的随机数
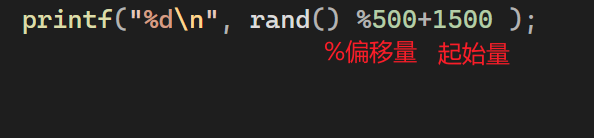

双色球案例:注意去重
1 |
|
1.函数的定义与使用
函数的定义
1 | 返回值类型 函数名(参数列表) |
定义静态函数static与非静态函数,静态函数与非静态函数的区别:
- 可见性:静态函数只能在当前文件内使用,不能被其他文件调用,而非静态函数可以被当前文件以外的其他文件调用,具有全局可见性。
- 生命周期:静态函数在程序运行期间一直存在,不会被释放,而非静态函数则是在被调用时动态地创建并在函数返回时被释放,拥有较短的生命周期。
- 内存分配:非静态函数调用时从堆栈中动态分配内存空间,函数返回时空间被释放,而静态函数分配内存空间仅一次,且在程序运行期间一直存在,调用时并不会重新分配内存空间。
- 其他:静态函数不能被其他文件调用,因此可以被认为是一种信息隐藏方法,能够有效地维护代码的安全性。同时,在一些对性能要求较高的场景,静态函数相比非静态函数性能更好,因为静态函数的调用时间更短。
函数实例:判断字符串是否相等
1 |
|
2.函数样式
1.无参函数
1 | int function() |
2.有参函数
1 | int function(int a,int b) |
3.函数的声明
如果函数定义在主函数之后,则函数需要在主函数之前声明。
4.main函数和exit函数
exit()函数:结束程序运行
在主函数中,main(),使用return和exit基本没有区别,都会结束程序运行
在函数中,使用return会返回返回值,使用exit()也会停止整个程序
例如:一个程序中有一个加载图片的函数,图片加载不了程序不能正常运行,则此时使用exit()函数使程序终止。
八、多文件编程
·可以再头文件中声明函数,在主函数中只导入头文件即可,不用一直声明函数。
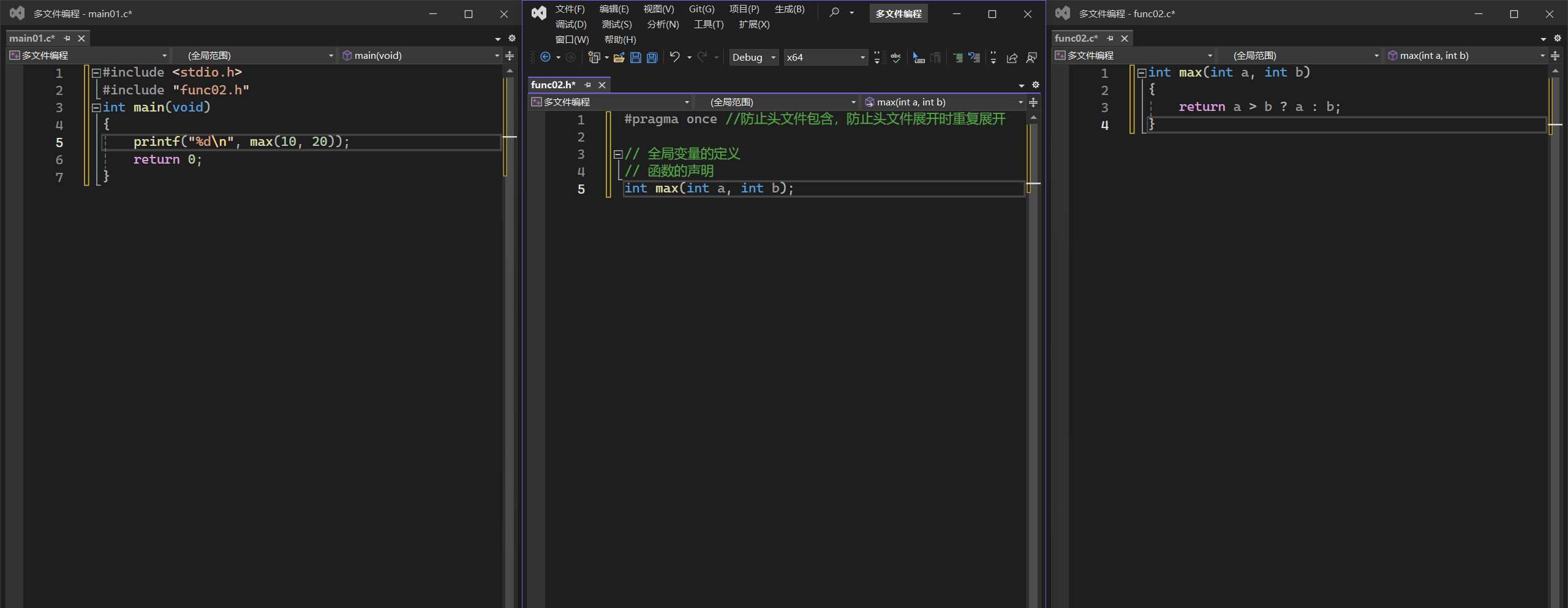
自定义函数文件和自定义头文件可以文件名相同,可以方便捋顺程序
自定义的头文件中要写,防止main函数 头文件包含
1 |
如果头文件包含则会报错:

为了避免同一个文件被include多次,C/C++中有两种方式,一种是#ifndef方式,一种是pragma once方式
#pragma once:
1 |
|
#ifndef
1 |
|
九、指针
1.定义指针
1 | int a = 10; |
定义指针时,想存储什么类型的数据就要定义什么类型的指针。
通过指针赋值:
1 |
|
| 运算符 | |
|---|---|
| * | 取值运算符 |
| & | 取地址运算符 |
可以通过 &a 取出 a 的地址赋值给指针p,也可以通过 * p 取出指针p所指向的变量存储的值
指针所占内存大小:
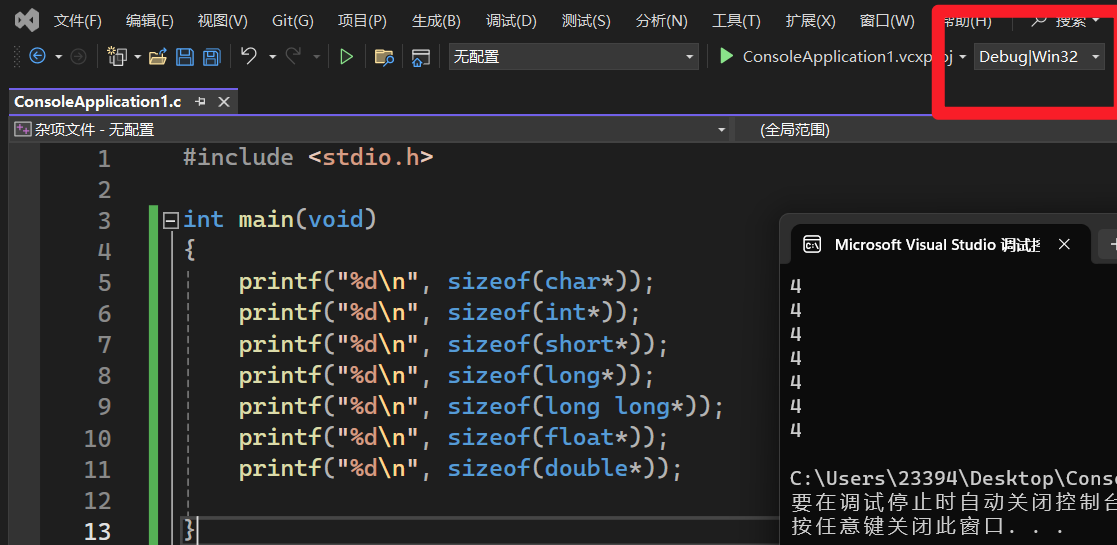
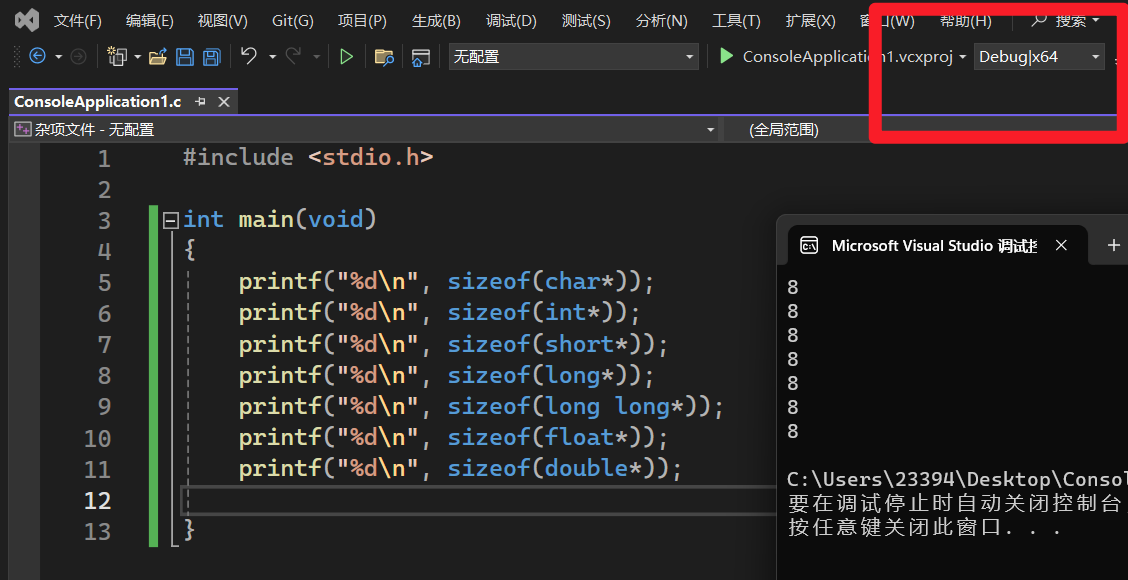
在32位操作系统中,指针大小为4字节 在64位操作系统中,指针大小为8字节
2.野指针和空指针
野指针
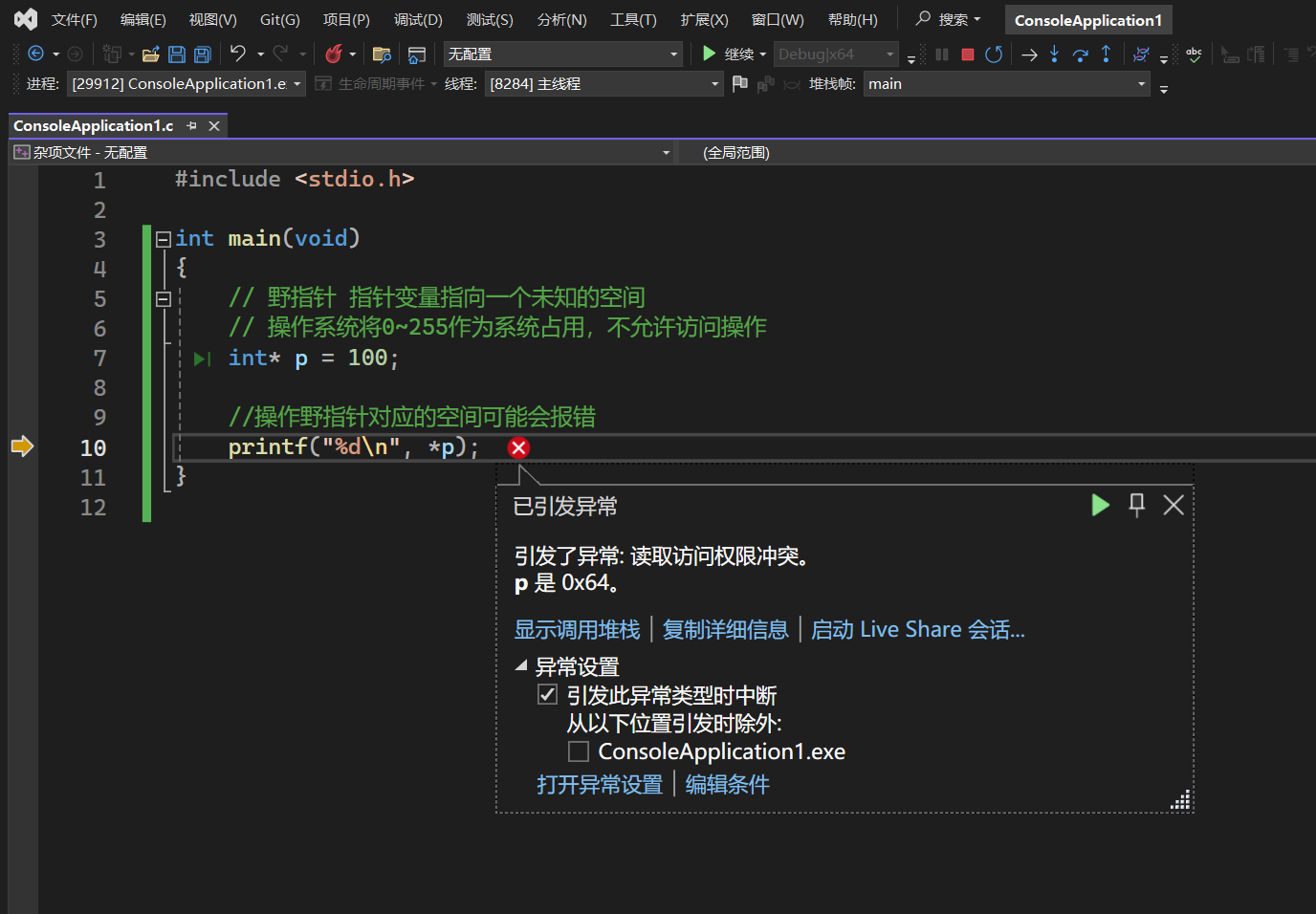
所以,存在野指针不会出现错误,但是操作或访问野指针时可能会出错。
不建议把一个变量的值直接赋值给指针。
空指针
空指针是指内存地址编号为0的空间
1 | int* p = NULL; |
空指针也不能访问或操作
应用:空指针可以用作条件判断
1 | if (p==NULL) |
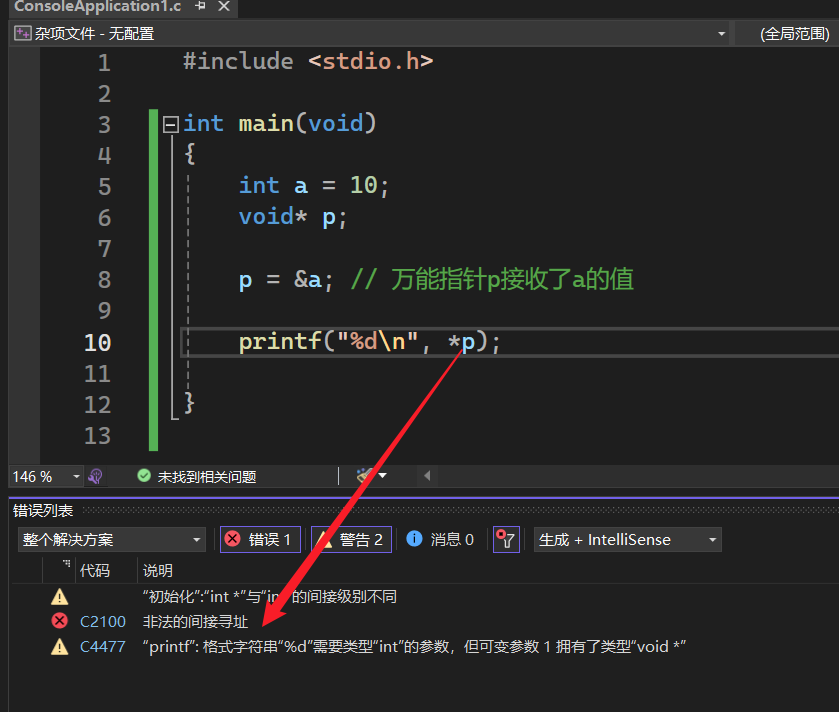
万能指针 void*
所占字节大小
在32为操作系统下占4个字节,在64为操作系统下占8个字节
万能指针可以接受任意类型变量的内存地址
但是通过万能指针操作(访问、修改)所指变量时,必须找到变量对应的指针类型,如:
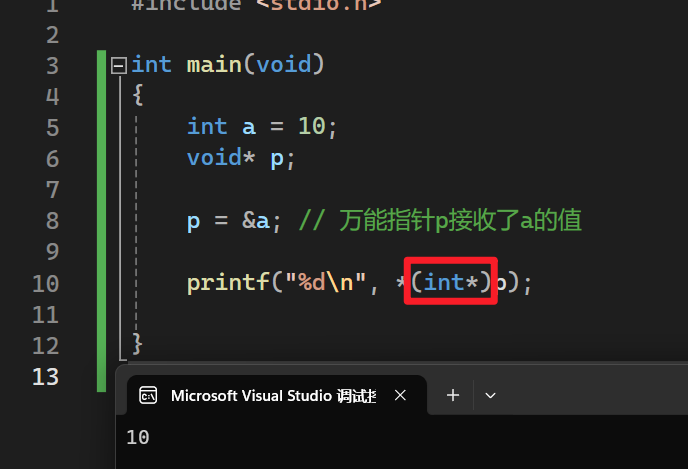
必须将指针p强制转换为int类型指针:
const修饰的指针类型
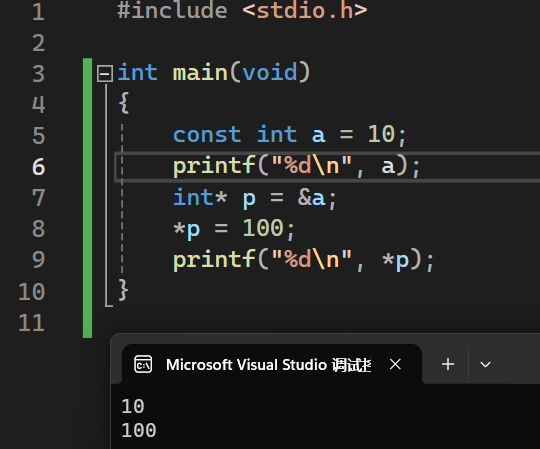 通过指针修改了const修饰的常量
通过指针修改了const修饰的常量
1.const修饰指针类型
可以修改指针变量的值,不可以修改指针指向内存空进的值。(const离谁近就不能改谁
2.const修饰指针变量
可以修改指针指向内存空间的值
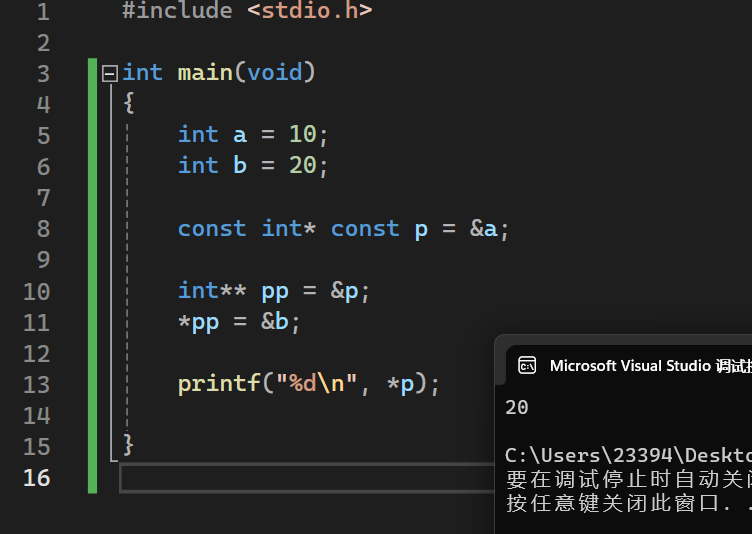
3.const同时修饰指针类型和指针变量(只读指针)
当const同时修饰指针类型和指针变量时,可以使用二级指针对一级指针所指的变量进行修改。
3.指针与数组
指针与数组(p与arr)的区别:
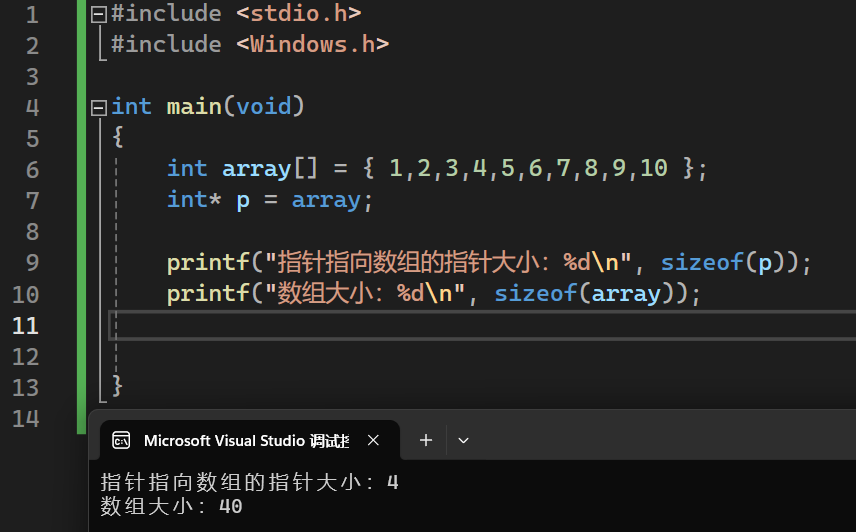
数组arr所指的地址不仅有地址,还包含数组的长度,使用指针p接收arr的地址,p只是一个指针变量,不具有整个数组的长度。
当数组作为函数参数会退化为指针。变成指针后,一个指针变量的大小为4字节(32位),丢失了数组的元素个数
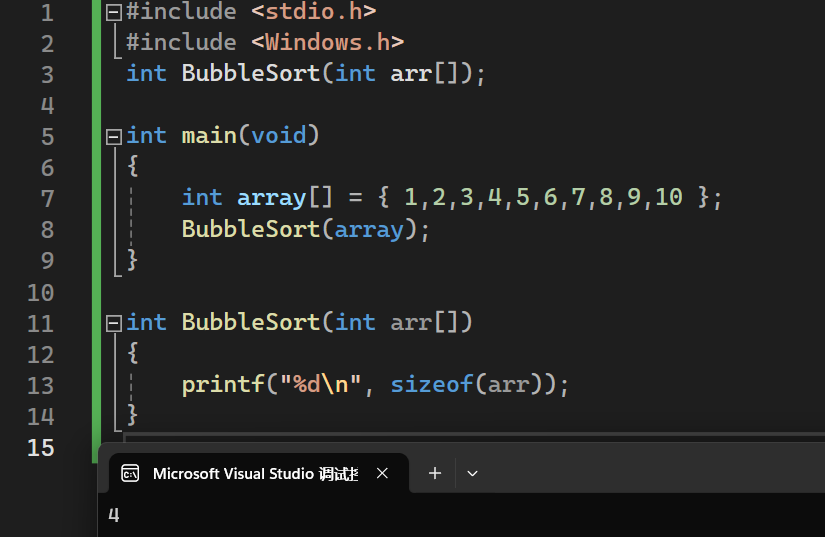
4.指针的加减运算
1.加法运算
指针计算不是简单得整数相加,
如果是一个int *,+1的结果是增加一个int的大小;
如果是一个char*,+1的结果是增加一个char大小。
通过指针运算,计算字符串长度。
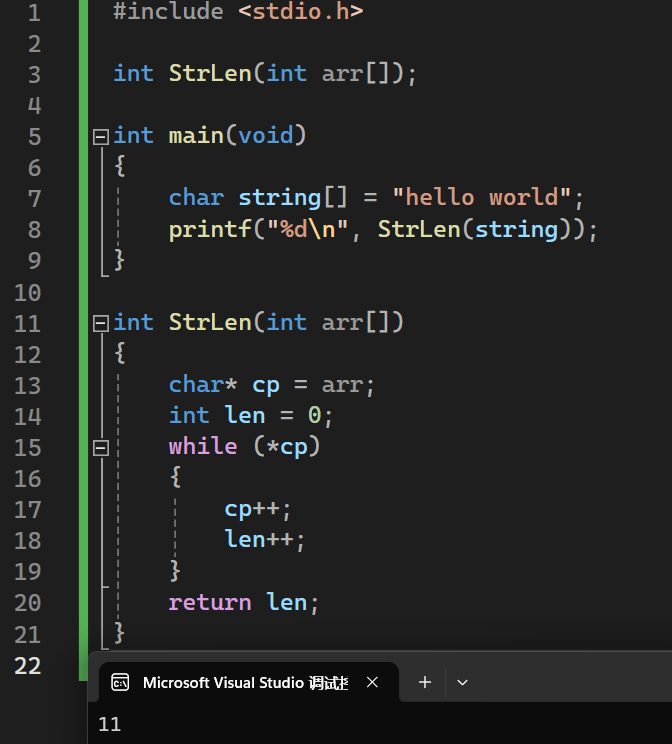
复制字符串
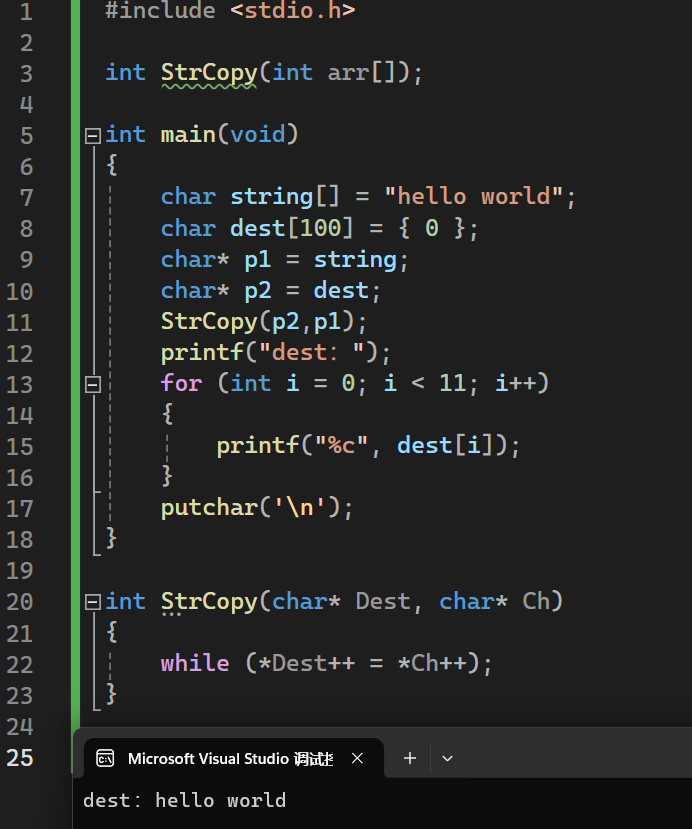
2.减法运算
C 汇编
1.参数与返回值
函数定义
1 | 返回类型 函数名(参数列表) |
返回类型和参数列表的参数类型,如int(4byte), short(2byte),char(1byte)等用来说明数据宽度是多大
函数返回值
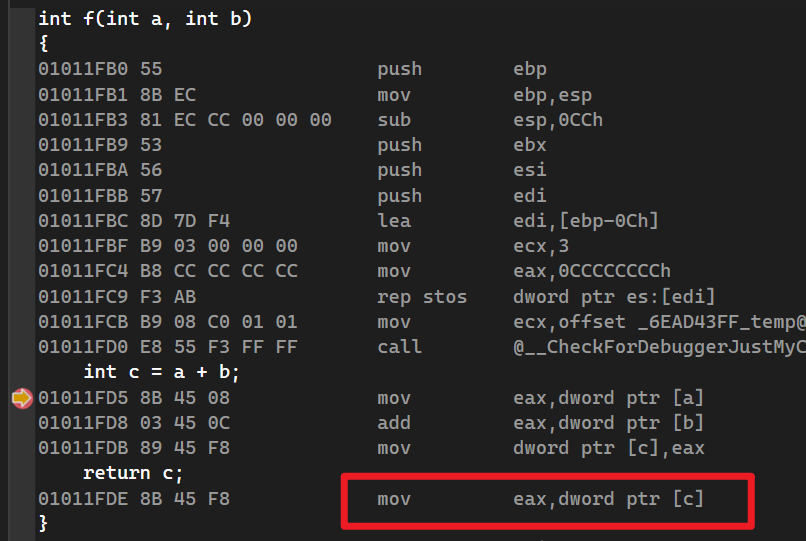

函数返回后使用eax存储,函数ret后,eax存储的返回值被压到堆栈中。
2.变量
全局变量
1 |
|
1)编译的时候就已经确定了内存地址和宽度,变量名就是内存地址的别名。
2)如果不重写编译,全局变量的内存地址不变。游戏外挂中的找“基址”,其实就是找全局变量。
3)全局变量中的值任何程序都可以改,是公用的。
局部变量
1 |
|
1)局部变量是函数内部申请的,如果函数没有执行,那么局部变量没有内存空间。
2)局部变量的内存是在堆栈中分配的,程序执行时才分配。我们无法预知程序何时执行,这也就意味着,我们无法确定局部变量的内存地址。
3)因为局部变量地址内存是不确定的,所以,局部变量只能在函数内部使用,其他函数不能使用。
函数调用的内存布局
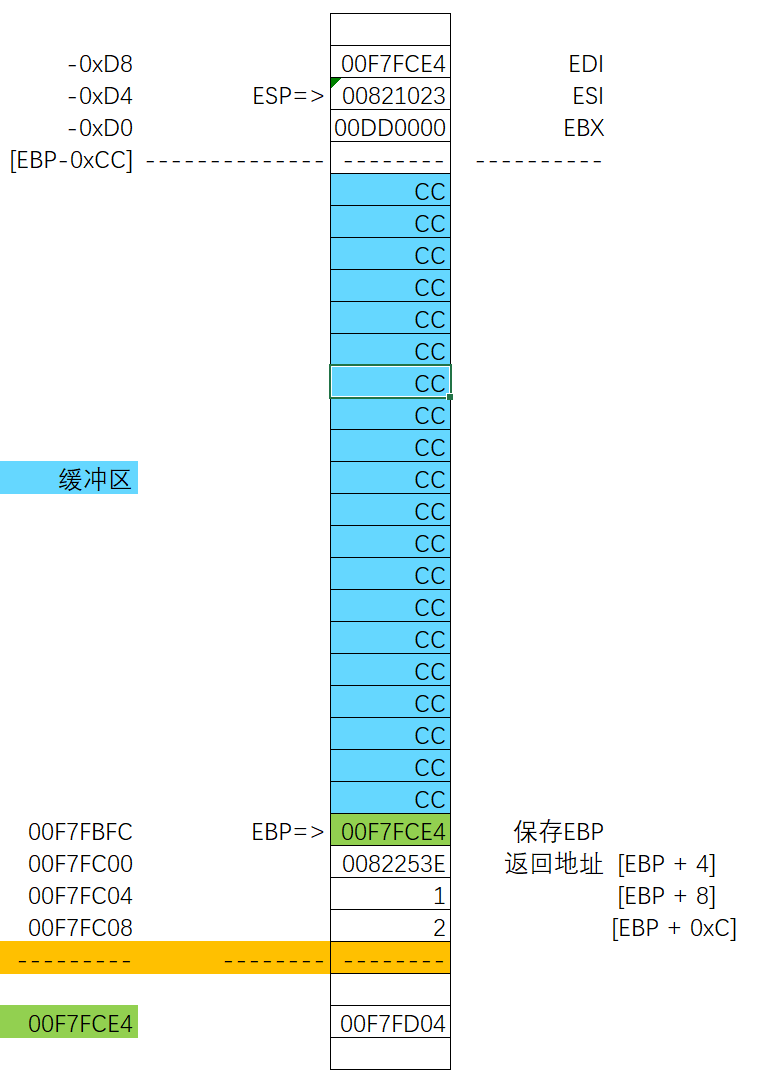
函数嵌套调用的内存布局
变量类型
基本类型
整数类型
整数类型的宽度:char short int long
char 8BIT 1字节
short 16BIT 2字节
int 32BIT 4字节
long 32BIT 4字节
浮点类型
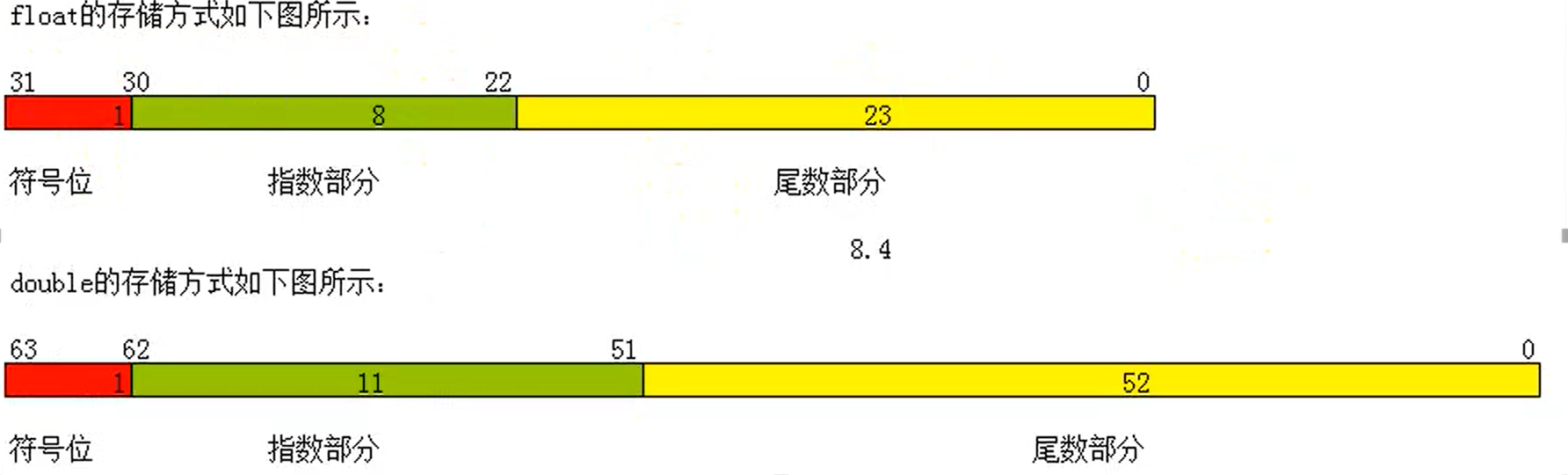
浮点类型的存储格式:float和double在存储方式上都是遵从IEEE编码规范的
8.25转成浮点存储:整数部分
整数部分8转成2进制
8/2 = 4 0
4/2 = 2 0
2/2 = 1 0
1/2 = 0 1
从下往上读,所以8转成2进制是1000
9转2进制:
9/2 = 4 1
4/2 = 2 0
2/2 = 1 0
1/2 = 0 1
所以9转2进制是1001
所以,所有的整数部分一定能转成2进制
8.25转2进制:小数部分
小数部分转2进制用乘法
0.25转2进制:
0.25 * 2 = 0.5 0
0.5 * 2 = 1.0 1
当小数部分乘出0时停止
从上往下读:0.25转成2进制是01
如小数部分0.4转成2进制:
0.4 * 2 = 0.8 0
0.8 * 2 = 1.6 1
0.6 * 2 = 1.2 1
0.2 * 2 = 0.4 0
……
会发现当0.4转成2进制的时候,小数部分永远得不到0,所以用二进制描述小数,不可能做到完全精确
使用IEEE规则存储小数8.25 -> 1000.01 -> 1.00001 * 2(10)^3
第一位是符号位,整数填0负数填1
尾数部分00001从前往后填,float类型尾数23位,所以尾数是00001000000000000000000
指数部分:当使用科学计数法时,小数点向左移,指数的最高位填1,向右移时填0
因为是3次方,所以3-1=2,将2转换为2进制,2 => 10
所以指数最后填10
所以8.25的2进制存储格式为 0 10000010 00001000000000000000000
这个数用16进制表示为 -> 0x41040000

if, if…else
if语句在编译器编译后,汇编语句比较灵活
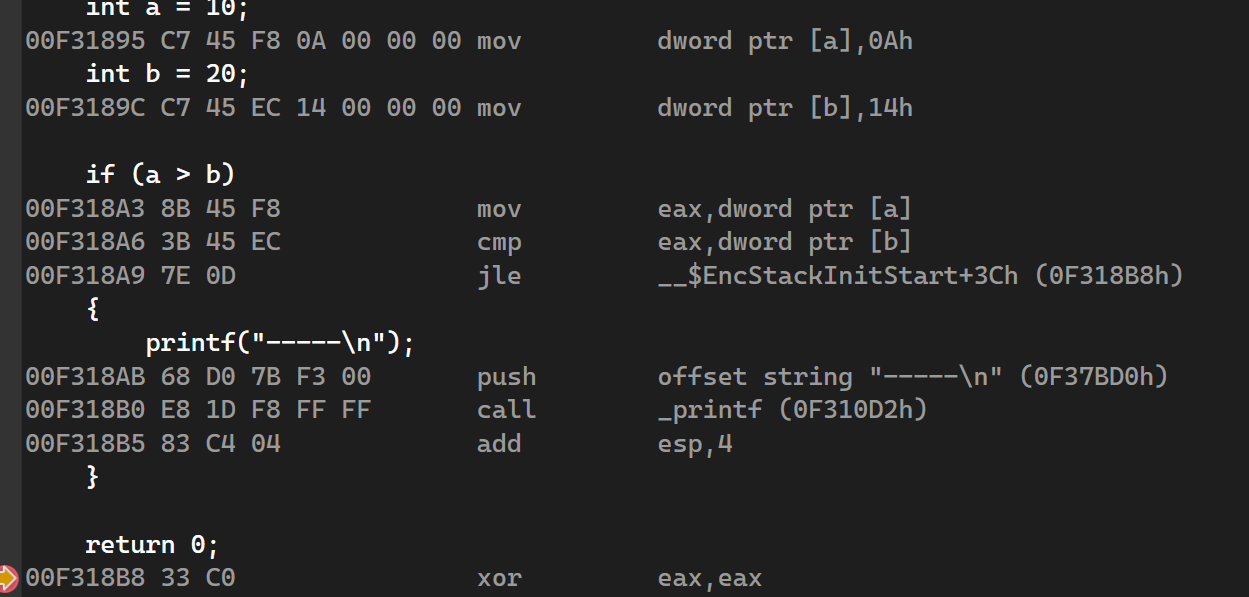
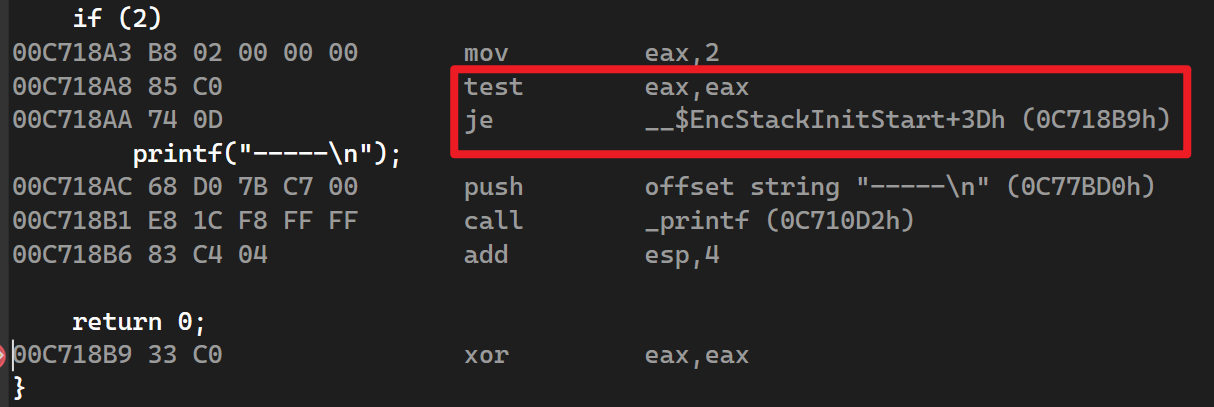
当条件为a > b时,汇编指令实际上做的是判断a <= b:当a > b时,JLE指令不执行,直接按步执行;当a <= b时,执行JLE指令,跳过if中的执行语句。
当条件较简单时,编译器也会将汇编编译成TEST。
if else
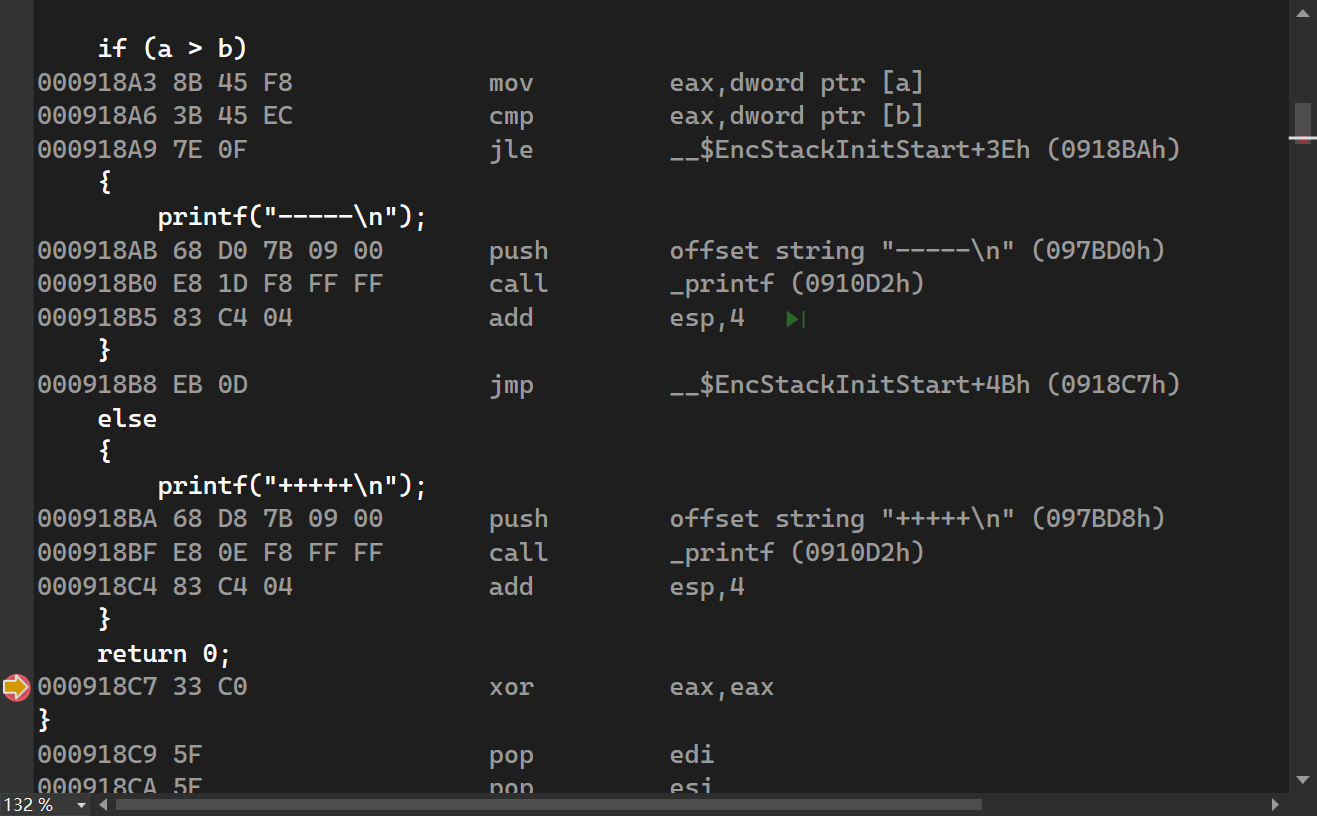
当if中判断不满足条件时,会跳转到else语句内部,当满足条件时,汇编语句会按步向下执行,在else上面的JMP跳过else的执行语句。
所以当判断语句是if…else时,一般中间会有一个JMP指令,用来跳过else执行语句。
switch
一般的switch
一般来说,使用switch分支语句比if的执行效率要高。
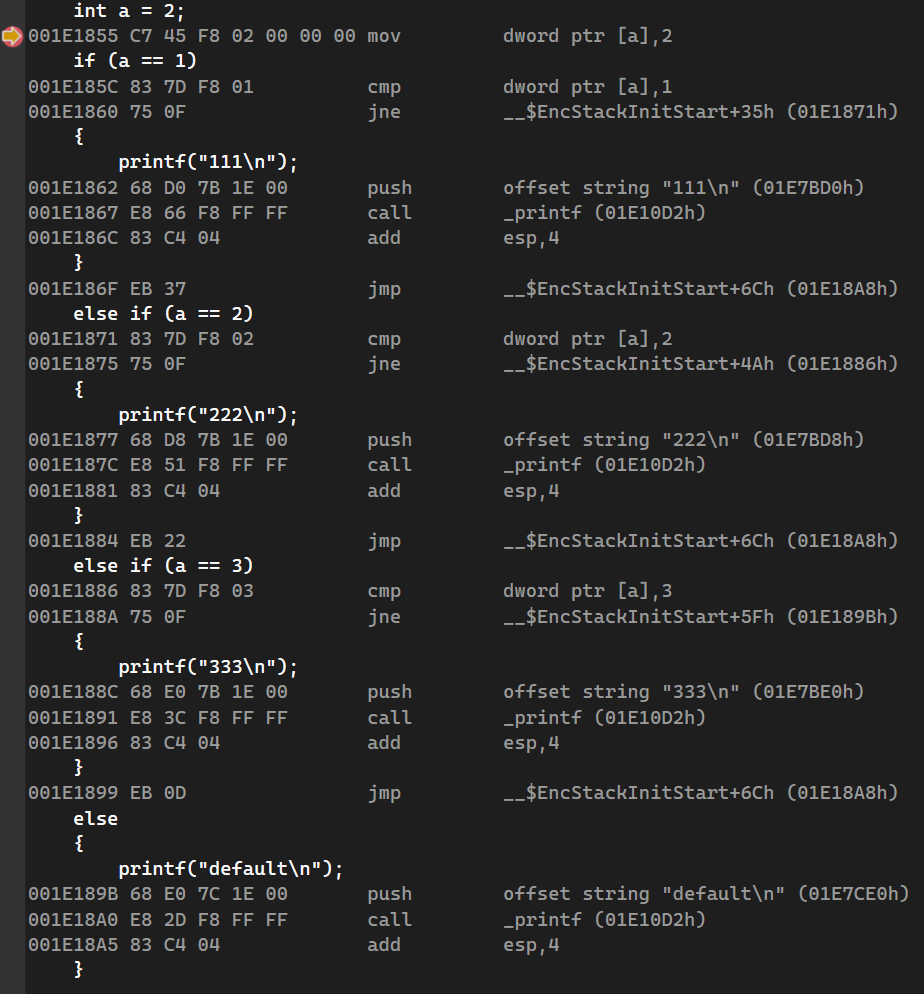
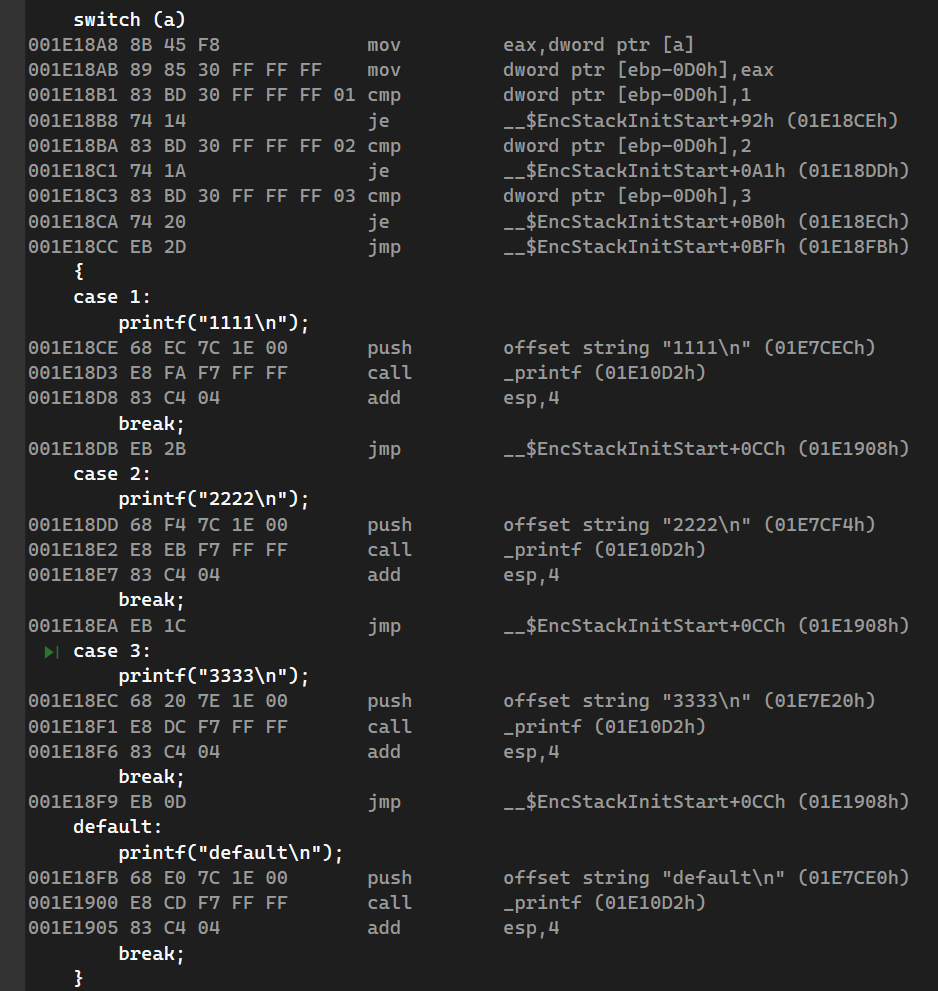
当情况较少时,使用if和switch的分支语句的执行效率差不多
但当情况较多时,使用switch的执行效率较高:
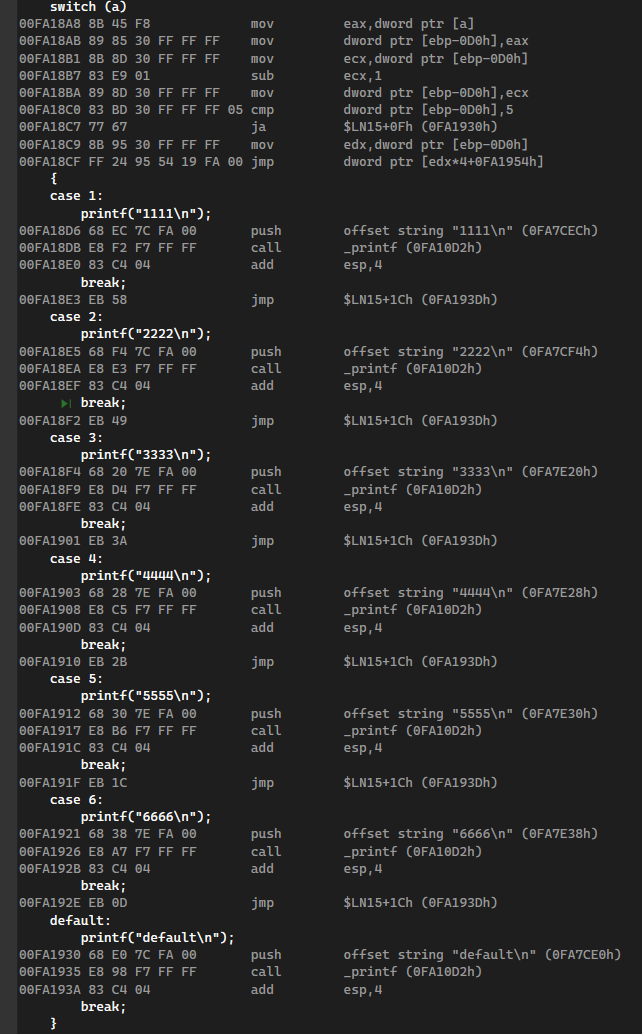
发现switch的跳转语句只有上面一点
1 | 00FA18A8 8B 45 F8 mov eax,dword ptr [a] |
switch语句在程序启动时已经在内存中生成了一个“跳转表”,在上面的这段汇编指令中,这个跳转表的地址就是从最后一句的0x0FA1954开始的,所以转到内存中查看这个内存地址:
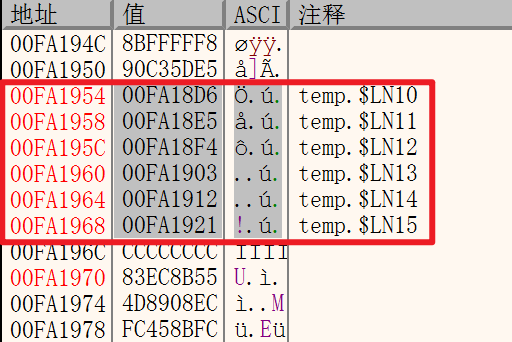
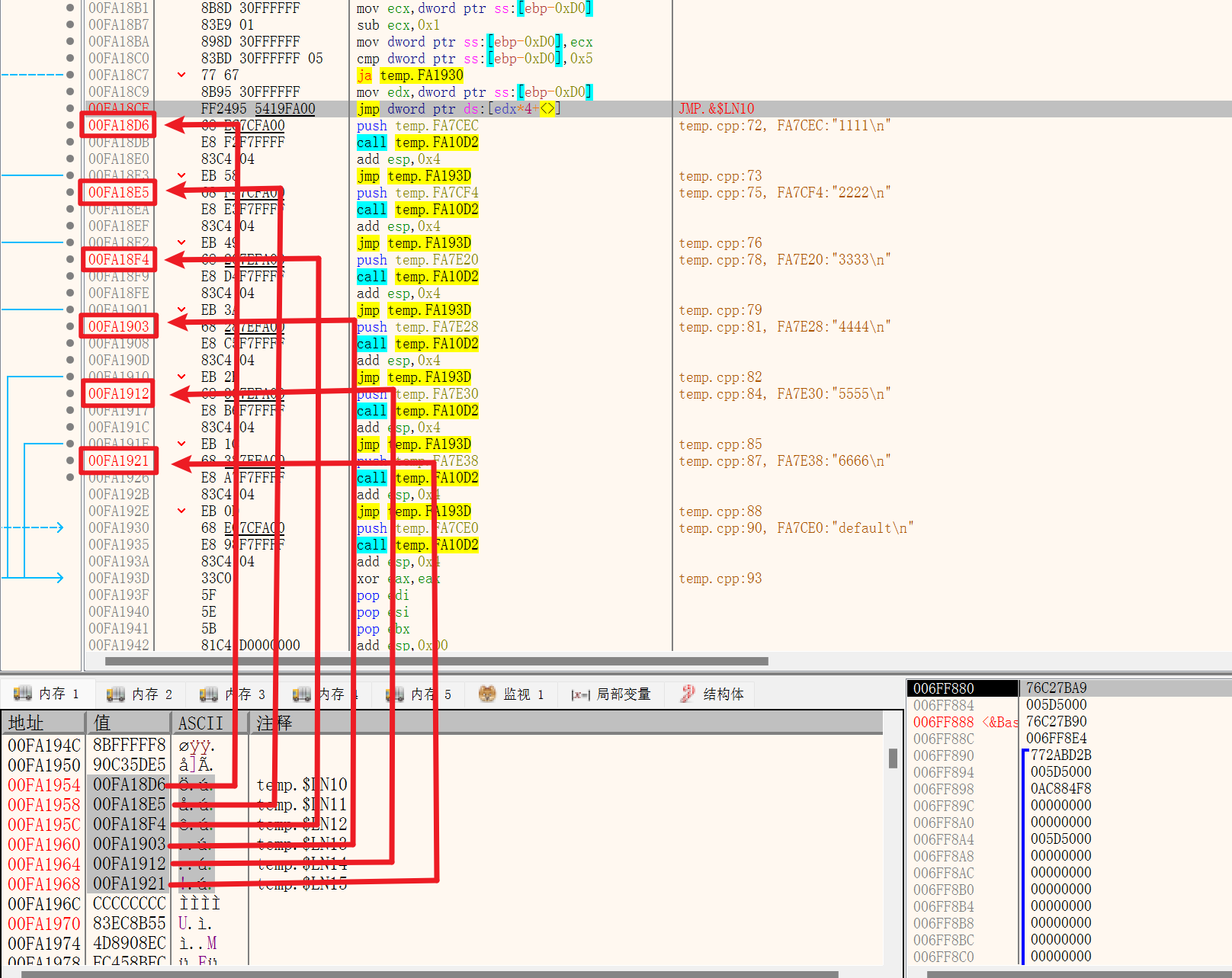
在内存地址中刚好存了这一段跳转表。
当跳转时,先有一句
1 | 00FA18B7 83 E9 01 sub ecx,1 |
这里减的是switch中最小的那个数,因为原码中写的switch条件是:
1 | int a = 2; |
所以最后减完的值会放到EDX中,使用EDX偏移计算要跳转的地址
switch运行速度快的第一点是:判断switch_on与最大的值的大小,当switch_on的值比最大的case还要大时,直接跳出switch
1 | 00FA18C0 83 BD 30 FF FF FF 05 cmp dword ptr [ebp-0D0h],5 |
计算完SUB之后,将计算完的值存到EDX寄存器,然后根据EDX计算跳转地址偏移。
当switch之中的值不是连续的
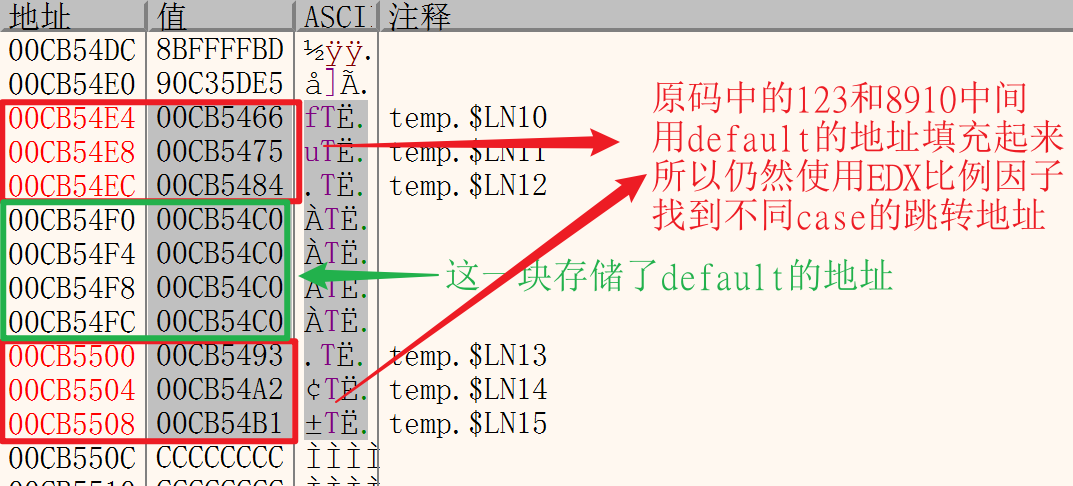
c原码:
1 | int a = 2; |
当case的值没有规律时
当case的值不连续且没有啥规律时,再多的case也可能跟if一样,每一个跳转都会有一个JMP
当原码是:
1 | switch (a) |
发现case的值有规律,但是从3到998差了很多,因此用EDX比例因子查内存地址的话,中间要差几百个default的地址,所以在这种情况下也不会使用EDX比例因子找,只会生成一堆JCC跳转指令。
1 | 006A5438 8B 45 F8 mov eax,dword ptr [a] |
因此当使用switch时,连续的case会提高代码的执行速度
do…while
do…while一般用于先执行后判断
for
for循环在反汇编中的形式
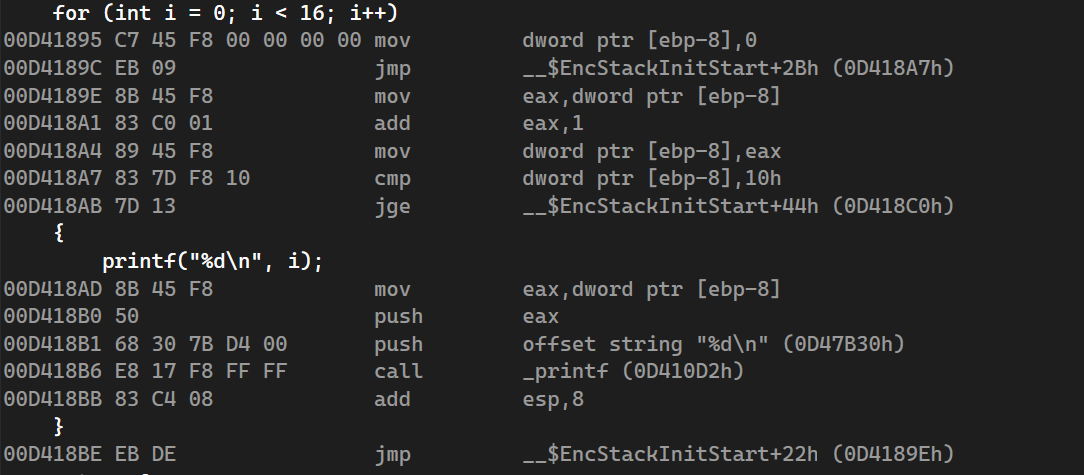
for循环的执行效率可能不是特别高,但是可读性比较好,比较容易写
for循环的第一个和第三个表达式可以使用逗号连接多个表达式,比如:
1 | int i; |
结构体数组
结构体数组的定义
定义结构体
类型 变量名[常量表达式]
定义结构题类型
struct stStudent
{
int Age;
int Level;
}
定义结构体变量
struct stStudent st;
定义结构题数组
struct stStudent arr[10] 或者 stStudent arr[10]
结构体数组的赋值
1 | struct MyStruct arr[3] = { {0,0},{1,1},{2,2} }; |
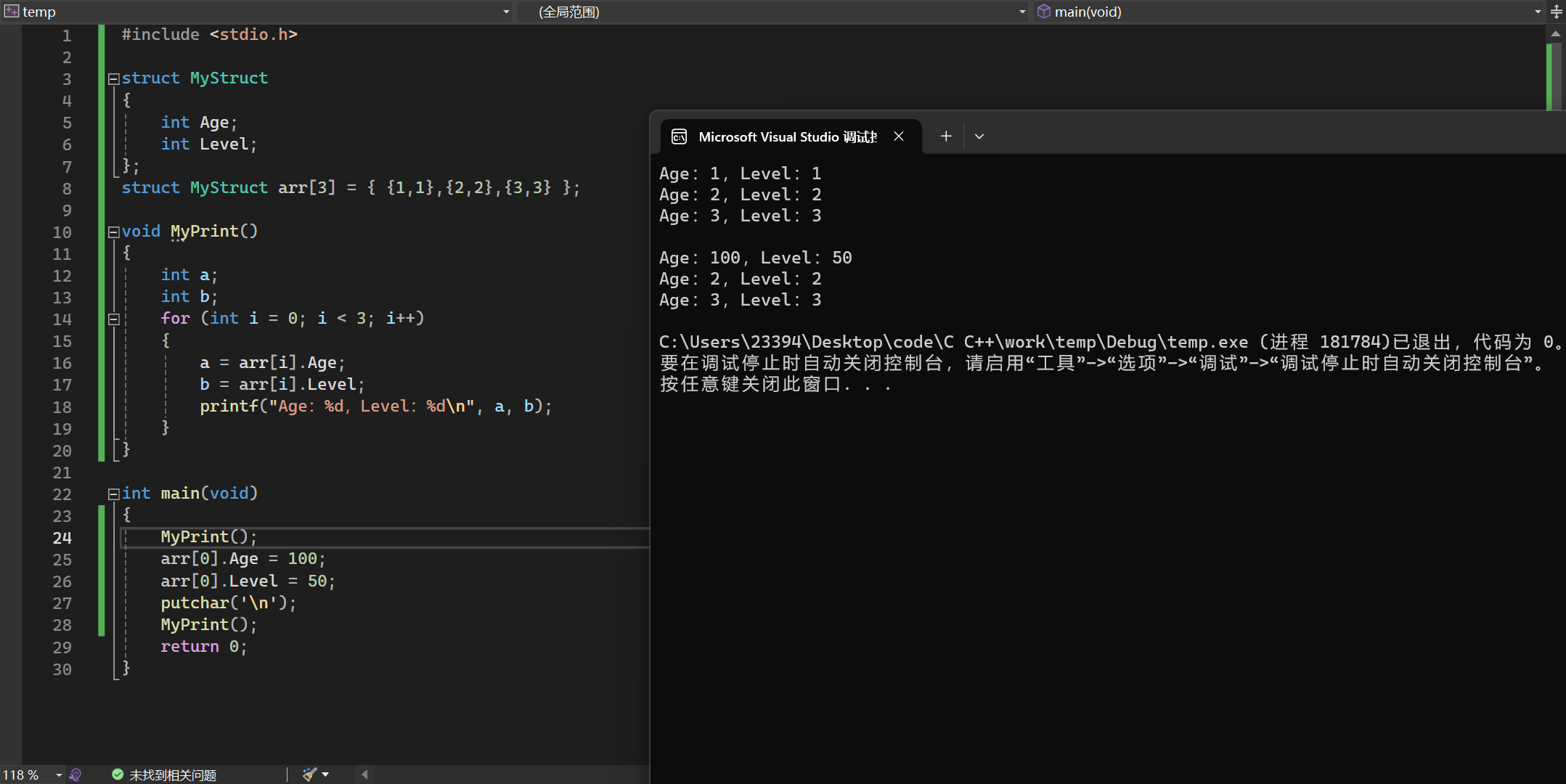
结构体数组中字符串成员的处理
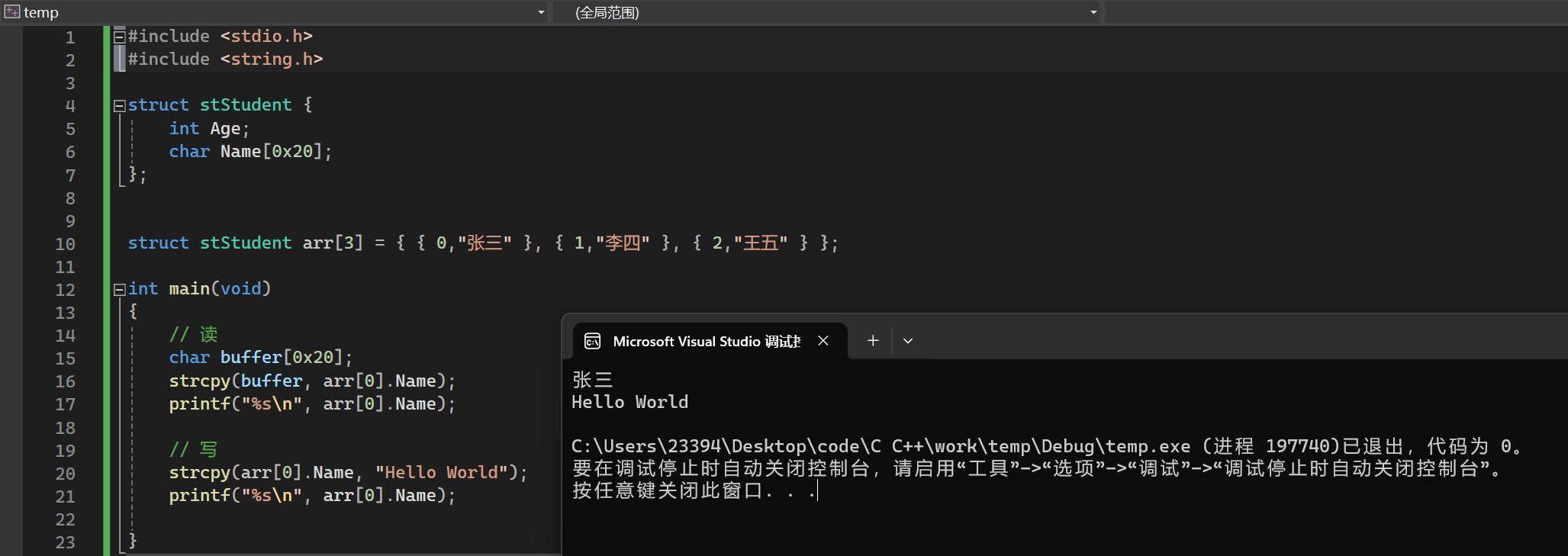
指针类型
任何类型都可以带上*,加上*以后是新的类型,统称为“指针类型”。
*可以是任意多个。
1 | char* x; |
指针变量的赋值

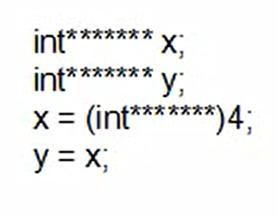
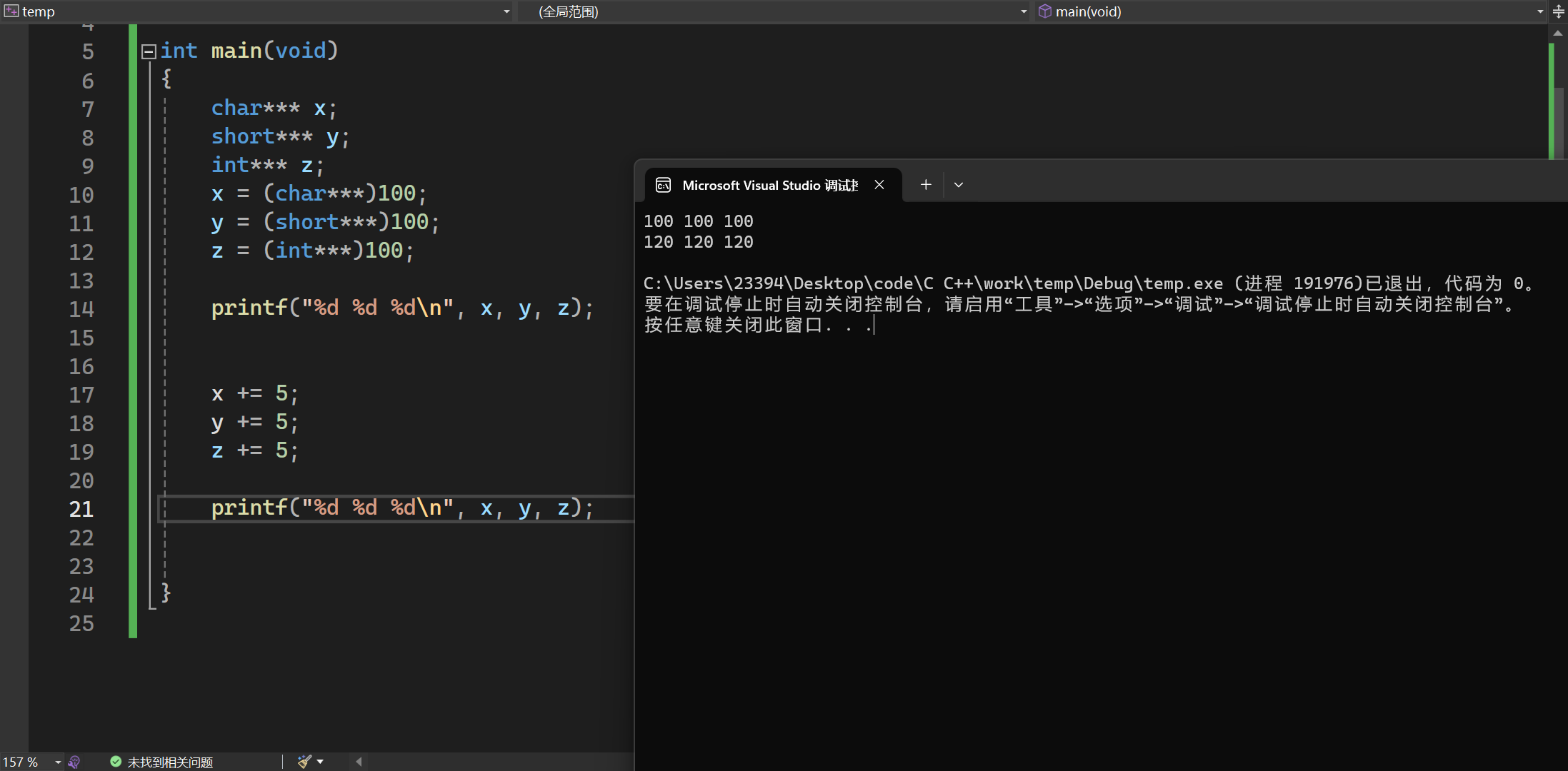
指针变量宽度
指针类型的变量宽度永远是4字节、无论指针类型是什么,无论是几级指针
指针变量的自加自减
1、不带*类型的变量,++或者–都是加1或者减1
2、带*类型的变量,++或者–新增(减少)的数量是去掉一个*后变量的宽度
也就是当指针变量是一级指针时,指针自加后,char类型会加1,short类型会加2.int类型会加4
当指针变量是二级以上时,指针自加后,都会加4,因为这时去掉一个*后,宽度都是指针的宽度4.
指针的加减运算
指针不能进行乘除运算,只能加减。
当指针时多级指针时:
当指针是一级指针时
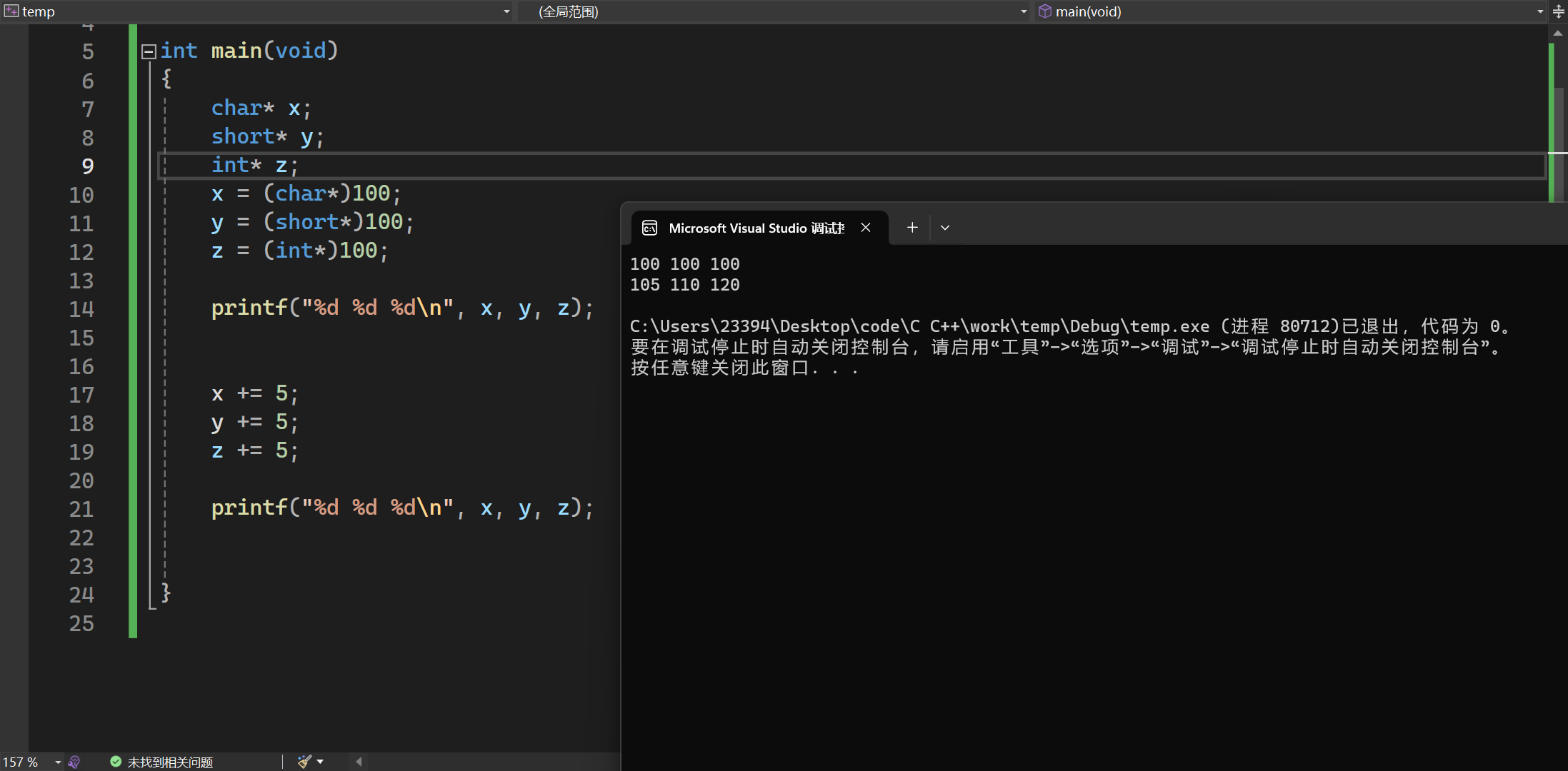
总结:

指针取值方式
1 | (p+i)=p[i] |
数组
数组参数传递
在反汇编中,arr[i]等价于*(p+i),使用函数传递数组参数时,传递的是数组的首地址,并且传送时不会传递数组的宽度。要使用数组的宽度时,必须要把数组的宽度也传递进去。
在函数中使用数组,如果是按照指针传递的数组,在使用时也可以按照数组来使用;如果是按照数组传递的参数,也可以按照指针的方式来使用。
字符串
字符串的定义方式
1 | char str[5] = {'a','b','c','d','\0'} |
程序会找到'\0'或者0来停止寻找字符串
1 | char str[] = "ABCDEF"; // 在常量区找一段空间放,然后在复制到数组中,因为复制到数组中才可以对其进行修改,比如str[0]=‘K',然后就变成了"KBCDE" |
1 | char* str = "ABCDE" |
这种方式是将字符串放在了常量区,但是没有复制到字符数组中,所以这样定义的字符串只能读,不能写(也有可以改的方法)
处理字符串函数
1.int strlrn(char * str)
返回值是字符串s的长度。不包括结束符’\0’。、
2.char * strcpy(char * dest, char * src);
复制字符串src到dest中,返回值为dest的值。
3.char * strcat(char * dest, char * src);
将字符串src添加到dest尾部,返回值为dest的值。
4.int strcmp(char * str1, char * str2);
一样返回0,不一样返回非0
结构体指针
首先定义一个结构体
1 | struct Point |
给结构体赋值、定义结构体指针
1 | Point p = { 1, 2 }; |
通过指针读取结构体时不用.,而是用->
1 | int x = px->x | x = 1 |
通过结构体指针修改结构体成员数值
1 | px->y = 100 | y = 100 |
指针数组 与 数组指针
指针数组的赋值
1 | char * a = "Hello"; |
数组指针的定义
1 | int(*px) [5]; //一维数组指针 |
int* p[5]和int (*p)[5]的区别:
int* p[5]:[]的优先级高于*,所以int* p[]是一个(int*)类型的指针数组,p本质上是一个数组;
int (*p)[5]:()的优先级高于[],所以p先与*结合,是一个指针,指针的类型是一个int[]数组,int (*p)[]是一个数组指针,p本质上是一个指针。
???


调用约定
| 调用约定 | 参数压栈顺序 | 平衡堆栈方式 |
|---|---|---|
| __cdecl | 从右至左入栈 | 调用者清理栈 |
| __stdcall | 从右至左入栈 | 自身清理堆栈 |
| __fastcall | ECX/EDX传递前两个参数,剩下还多的,从右至左入栈 | 自身清理堆栈 |
函数指针
定义函数指针变量:
1 | int (__cdecl *pFun)(int, int); |
为指针变量赋值:
1 | pFun = (int (__cdecl *)(int, int))10; // 这里随便赋了一个10,使用时应该赋一个函数的地址 |
使用函数指针变量:
1 | int r = pFun(1, 2); |