
PE
PE
PE文件结构
可执行文件
可执行文件(executable file)指的是可以由操作系统进行加载执行的文件
exe。txt之类的不是可执行文件,因为txt文件依赖exe打开。
可执行文件格式
1 | Windows平台: PE(Portable Executable)文件结构 |
应用
<1>病毒与犯病毒
<2>外挂与反外挂
<3>加壳与脱壳(保护与破解)
<4>无源码修改功能、软件汉化等
PE指纹
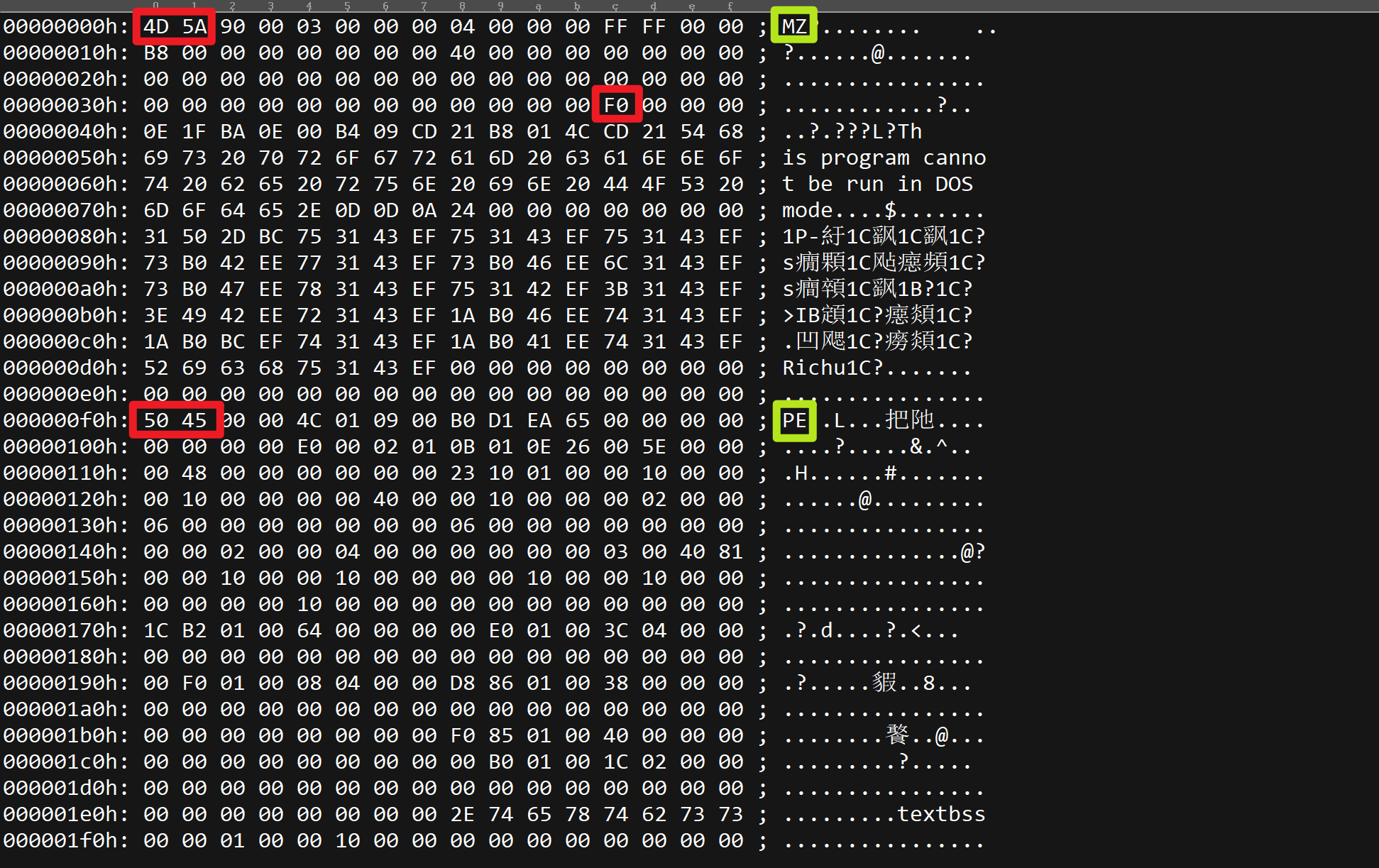
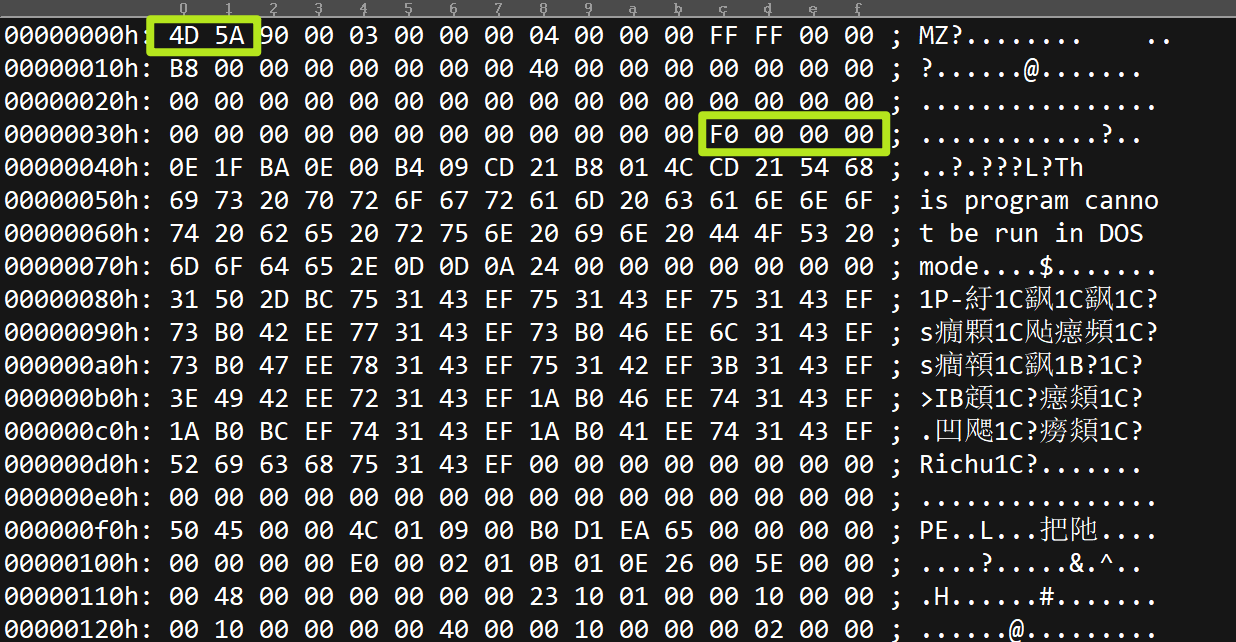
开头是4D 5A,往后查到0x3C的位置,这里存着一个地址,F0,从头往后查F0个地址,发现是50 45也就是PE,这就是PE指纹。
.sys .exe .dll都符合PE文件结构,都有这样一个结构体:
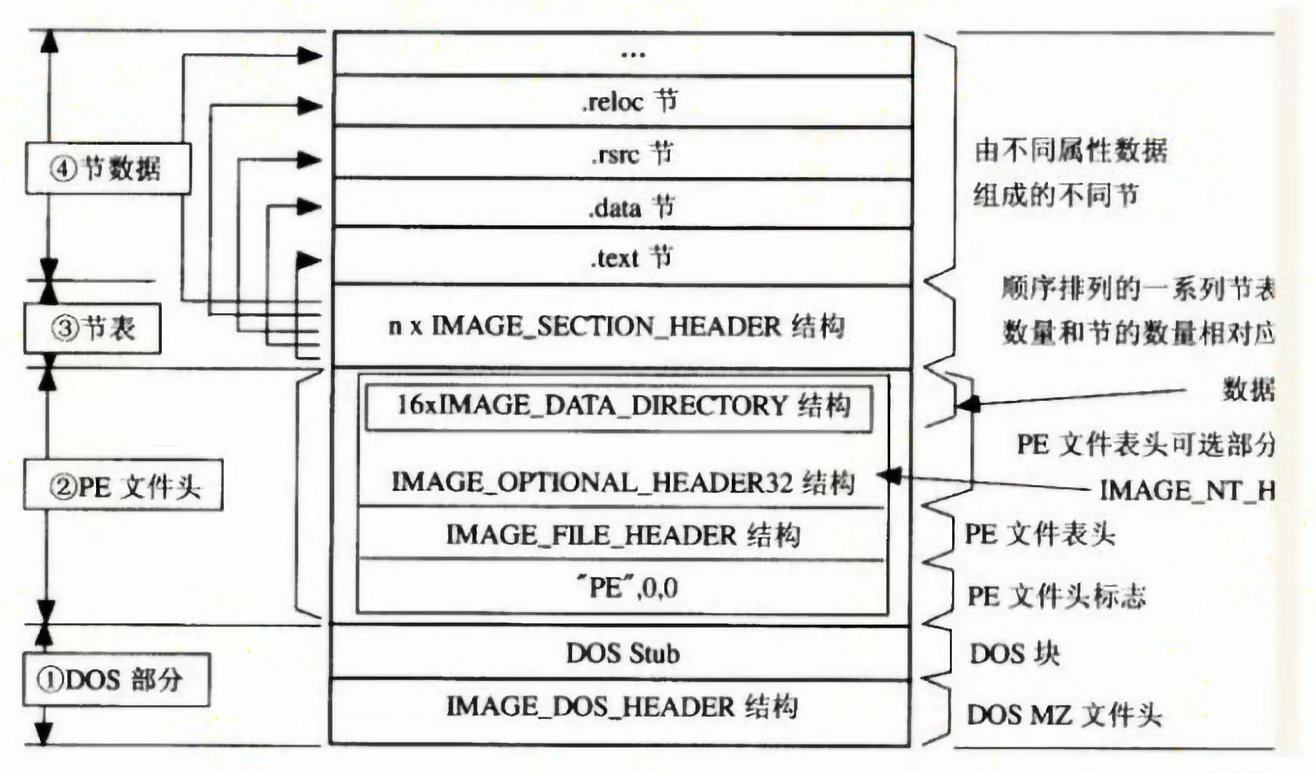
PE文件的两种状态
DOS MZ头 DOS块 4个字的PE标识 20个字节标准PE头 224个字节的扩展PE头 40个字节第一个节表里面的数据 40个字节节表里的第二个成员 40个字节第三个成员 40个字节第四个成员 至此标准PE头结束
DOS头属性说明
DOS MZ文件头结构

1 | //注释掉的不需要重点分析 |
这个结构体是16位的,但是现在的程序一般都运行在32位或64为的平台,但是有两个例外(标红的)。
两个红的还在使用,也就是这两个地方↓↓↓。除了这两个地方,其他的地方删了也不影响程序的正常运行。
PE头
1 | typedef struct _IMAGE_NT_HEADERS{ |
PE标识:PE标识不能破坏,操作系统在启动一个程序的时候会检测这个标识
标准PE头
1 | typedef struct _IMAGE_FILE_HEADER { |
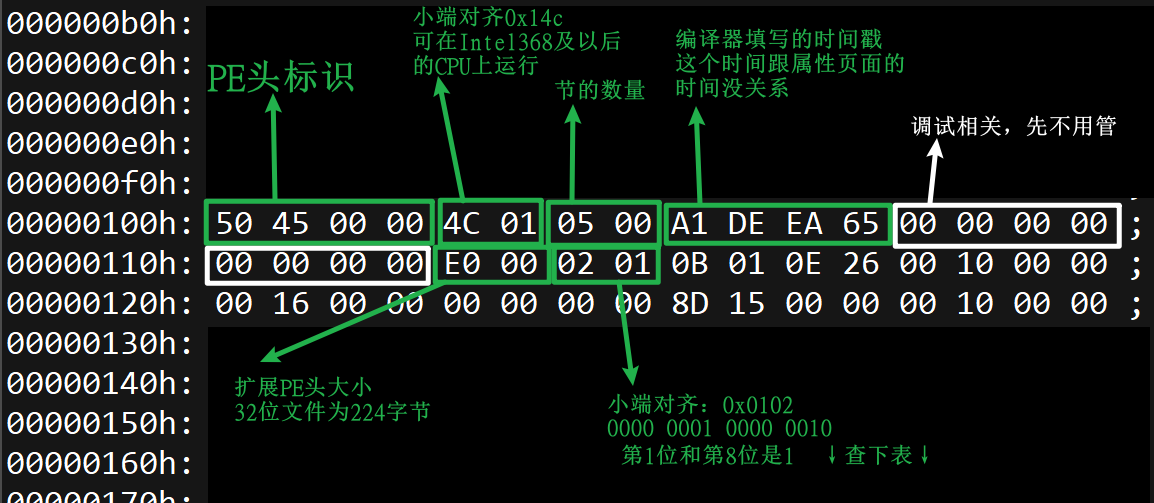
文件属性:
扩展PE头
32位的扩展PE头和64位的扩展PE头不太一样,这里只说32位的扩展PE头
1 | typedef struct _IMAGE_OPTIONAL_HEADER { |
Magic表示当前PE文件是32位还是64位,32位时该值对应0x10B,64位时该值对应0x20B。
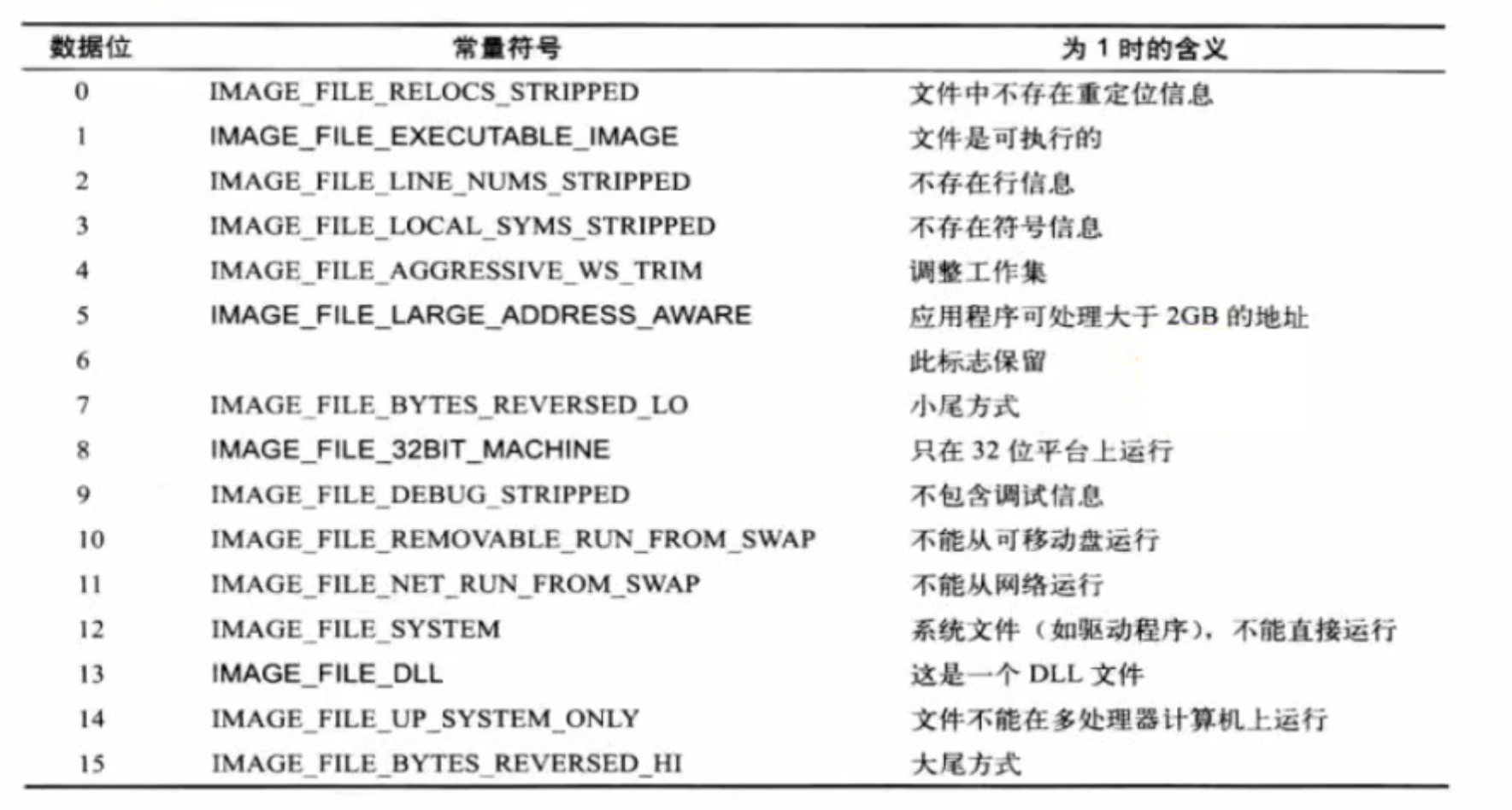
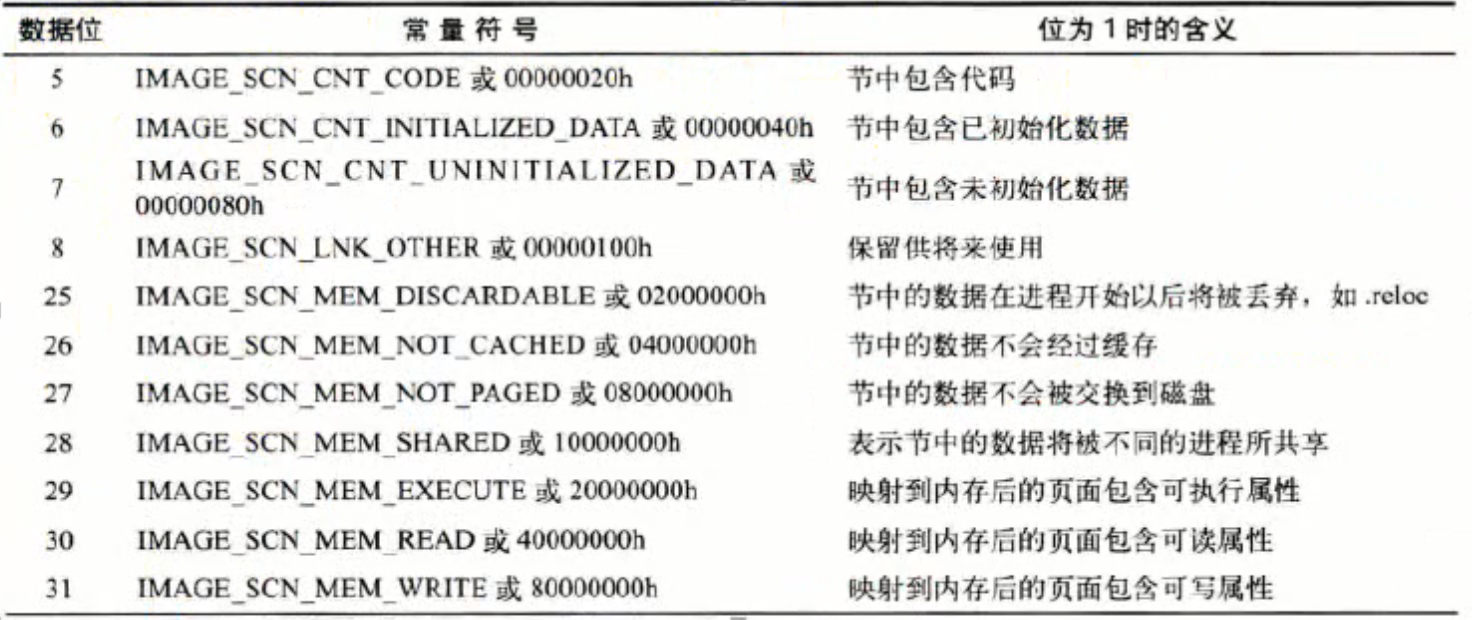
其中的文件特性:拆分为二进制后对应的位:
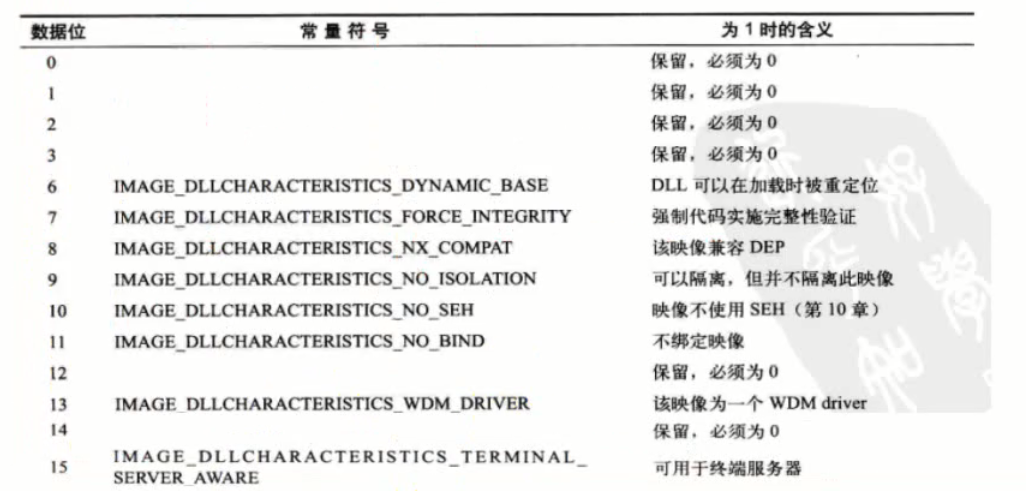
AddressOfEntryPoint表示当前程序入口地址,这个成员与ImageBase相加才能得到真正的入口地址,成员ImageBase用来表示内存镜像基址,也就是PE文件在内存中按内存对齐展开后的首地址。
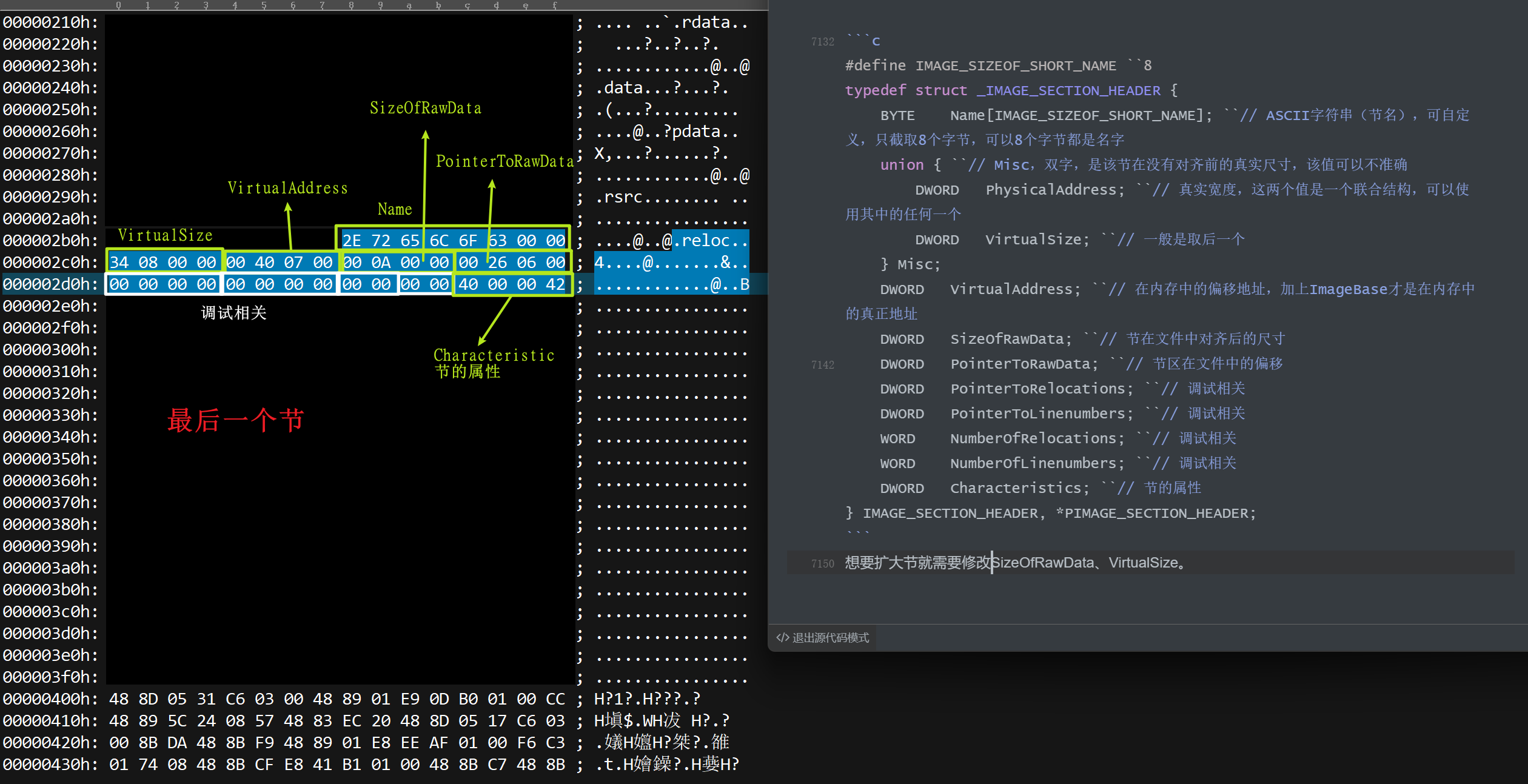
节表
节表数据结构说明
节表是一个结构体数组,每一个结构体描述一个节的信息。

1 |
|
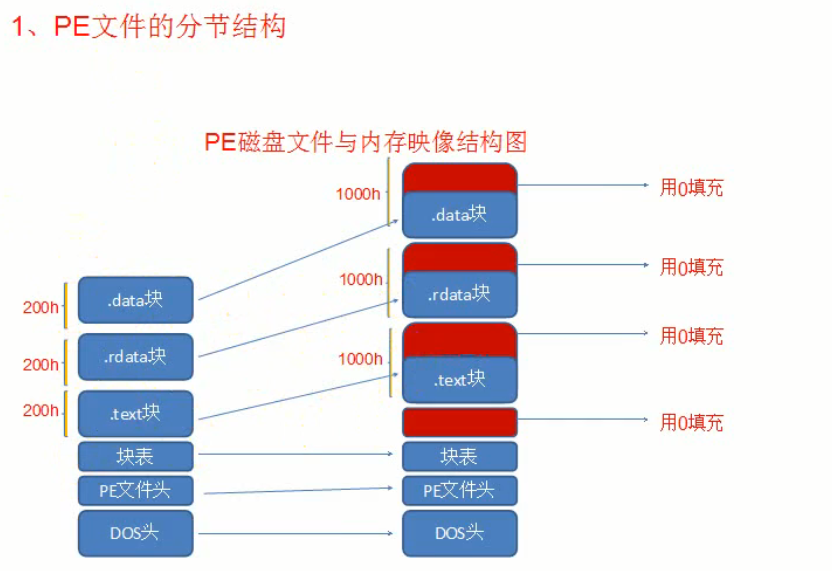
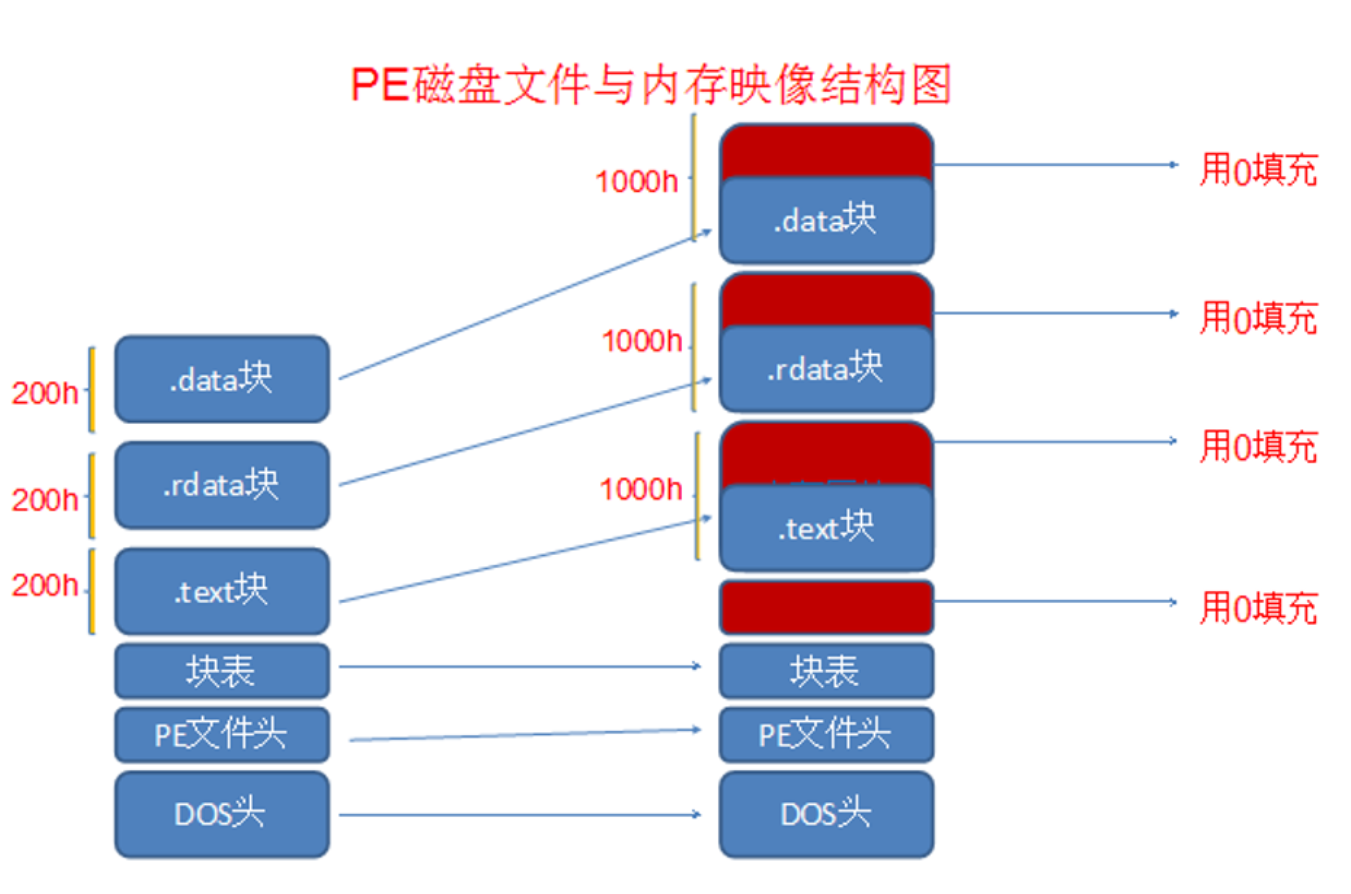
代码中的注释可以大致了解到每个成员的作用,其中有2个成员来描述节的大小,分别是没有对齐前的真实尺寸和对齐后的宽度,这时候会出现一种情况就是对齐前的真实尺寸大于对齐后的宽度,这就是存在全局变量没有赋予初始值导致的,在文件存储中全局变量没有赋予初始值也就不占空间,但是在内存中是必须要赋予初始值的,这时候宽度就大了一些,所以在内存中节是谁大就按照谁去展开。
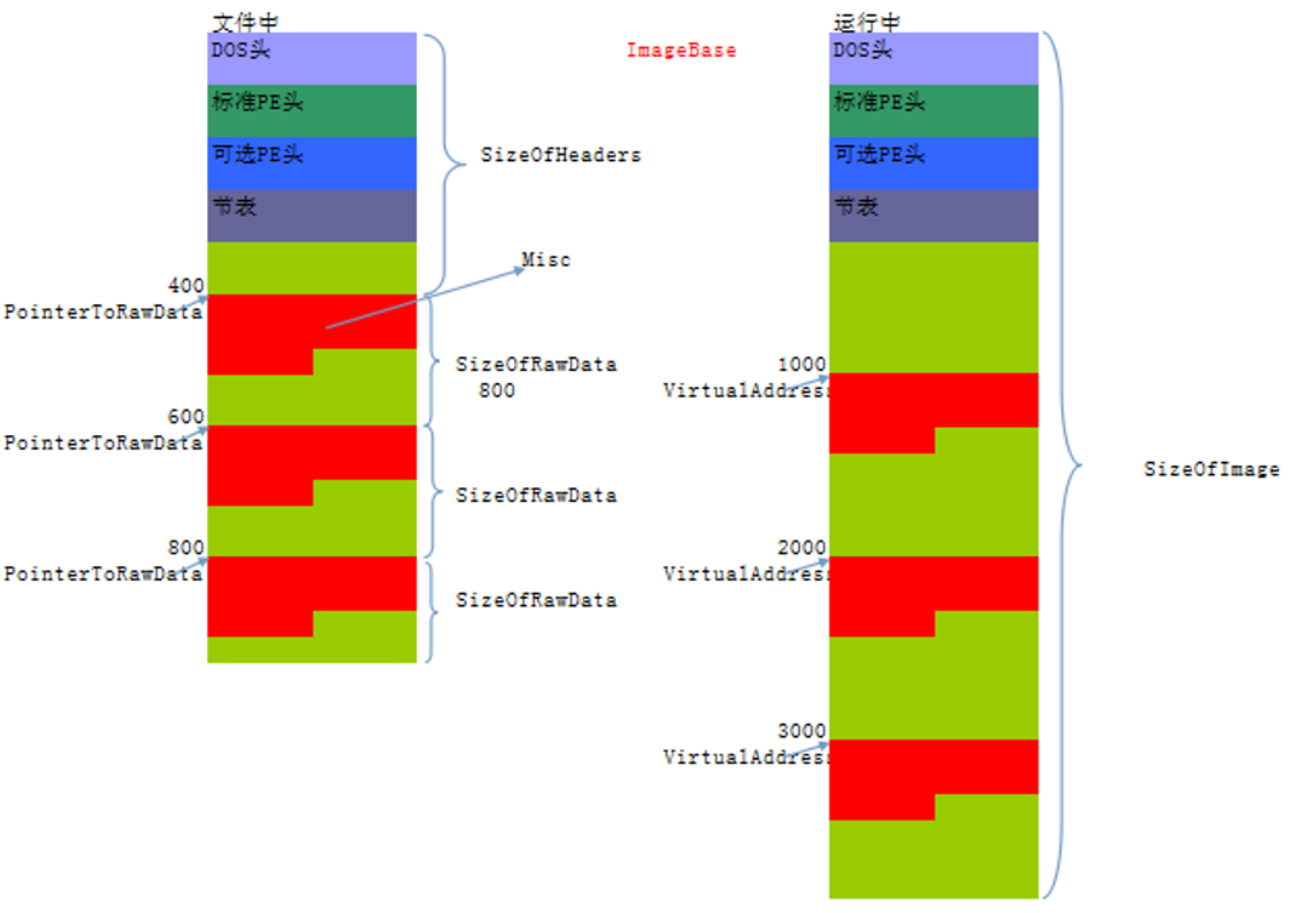
节的属性:将四个位全部展开后对应下表
RVA与FOA的转换
问题:如果想改变一个全局变量的初始值,该怎么做?
有初始值的全局变量和没有初始值的全局变量在PE文件中是不一样的。没有初始值的全局变量在PE文件中根本没有他的位置,只有在运行时内存展开后才会给他分配一个0;有初始值的全局变量的值是已经在PE文件中。
这个地址是在内存展开后的地址,直接在PE文件中找这个地址肯定不行,因为PE文件静态和动态的地址肯定不一样。
所以要把动态时的地址转换成PE文件静态地址。
这两种状态的地址相互转换,可以称为RVA与FOA的转换,RVA就是相对虚拟地址(Relative Virtual Address)(动态),FOA就是文件偏移地址(File Offset Address)(静态),FOA和内存无关,它是某个位置距离文件头的偏移。
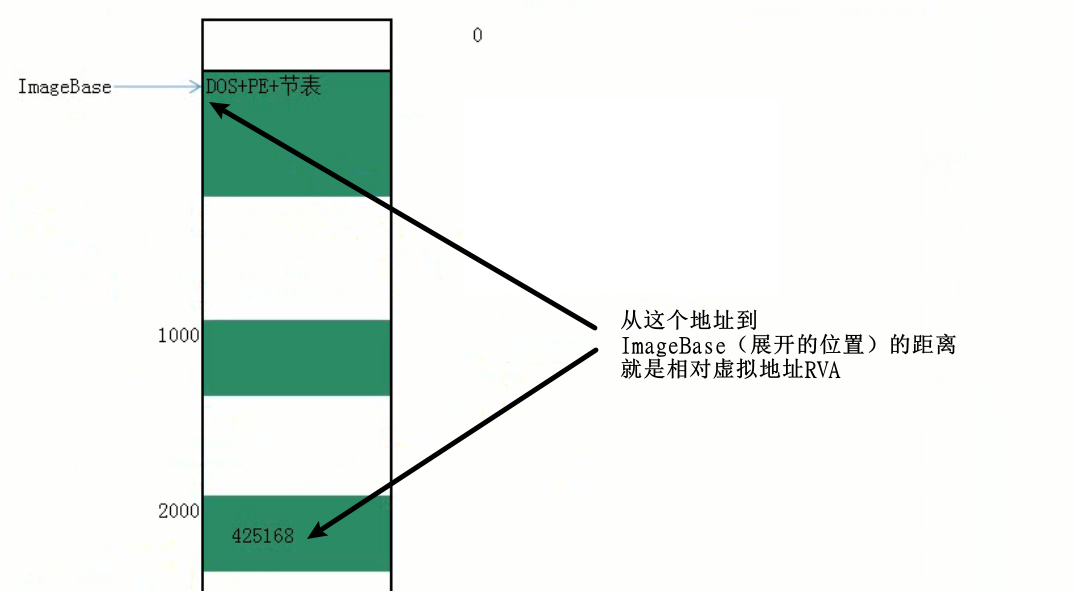
- RVA地址由内存地址减去ImageBase地址(PE文件在内存中的开始位置是由扩展PE头中的ImageBase决定);
- 判断RVA地址是否位于PE头中:
- 如果是,那么RVA等于FOA;
- 如果不是,判断RVA位于哪个节:
- 当满足RVA地址大于等于节.VirtualAddress和RVA地址小雨等于节.VirtualAddress加上当前节内存对齐后的大小时,就表示RVA地址在该节中。
- RVA地址减去节.VirtualAddress等于差值,FOA地址就是根据节.PointerToRawData加上差值。
在一些较老的编译器中,编译出来的文件会区分文件对齐、内存对齐,但是在现在的编译器编译出来的程序,文件对齐与内存对齐时完全一样的,所以我们不用费这么大的周折,我们只需要算出RVA的值就可以得出FOA的值。
空白区添加代码
目标:打开程序时首先弹出一个窗口。
<1>构造要写入的代码
<2>在PE的空白区构造一段代码
<3>修改入口地址为新增代码位置
<4>新增代码执行后,跳回入口地址
构造要写入的代码,比如调用一个MessageBoxA。在VS中查看反汇编可以发现调用MessageBoxA的时候先有4个push 0,然后是一个调用。在编译器中看到的调用是间接调用,如果要写到PE文件中需要使用直接调用。
首先打开一个exe程序,查看一下MessageBoxA在内存中的地址。因为user32.dll中的地址是不会变的,所以直接拿过来就可以使用(同一台电脑一样,但是每台电脑不一样)。
使用call时,硬编码为E8,后面跟的地址应该是地址偏移。计算公式为目标地址 - E8所在地址 - 5 = E8后面应该写的值。
通过查询得MessageBoxA的地址为751DA0E0。
如果将E8写在0x3A8处,那么E8后面应该加的值为751DA0E0 - 4003A8 - 5 = 74 DD 9D 33。
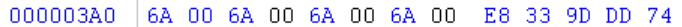
执行完这段代码之后,还要跳转回原先的程序入口。
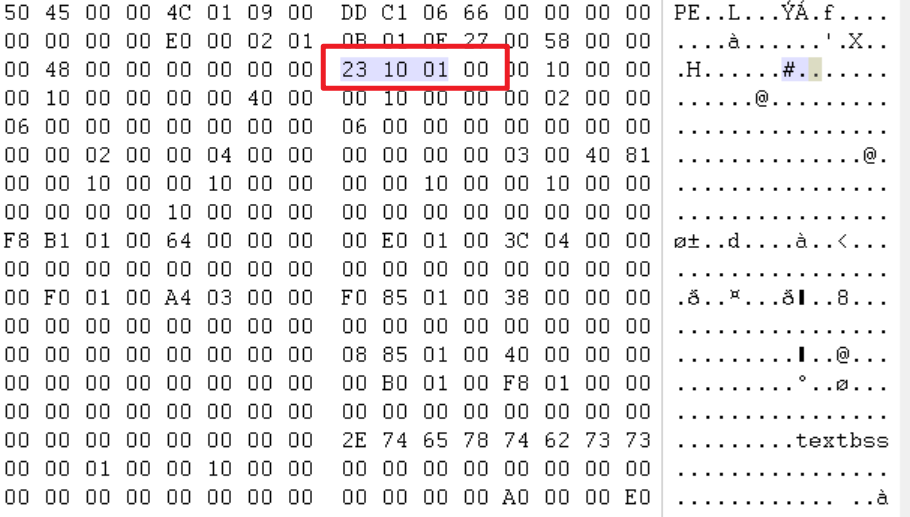
在扩展PE头中查到这个地址是0x11023。所以还要计算E9后面跟的值。
0x411023 - 0x4003AD - 5 = 10C71
所以:
这时添加的代码就完成了,最后还需要把文件开始执行的地址改成E8前面开始push的地址,也就是0x3A0。

扩大节
当我们需要插入的代码比较多时,如果只在节表后面的空白区域添加是不够的,所以可以在某一个节中添加,因此扩大一个节。
扩大节时,最好是扩大最后一个节,因为如果要扩大前面的节的话,后面每一个节的属性都需要修改。所以扩大最后一个节。
首先在文件的最后,插入需要的大小,比如扩大最后一个节0x1000(DEC:4096)
一个节表的定义如下
1 |
|
想要扩大节就需要修改SizeOfRawData、VirtualSize。
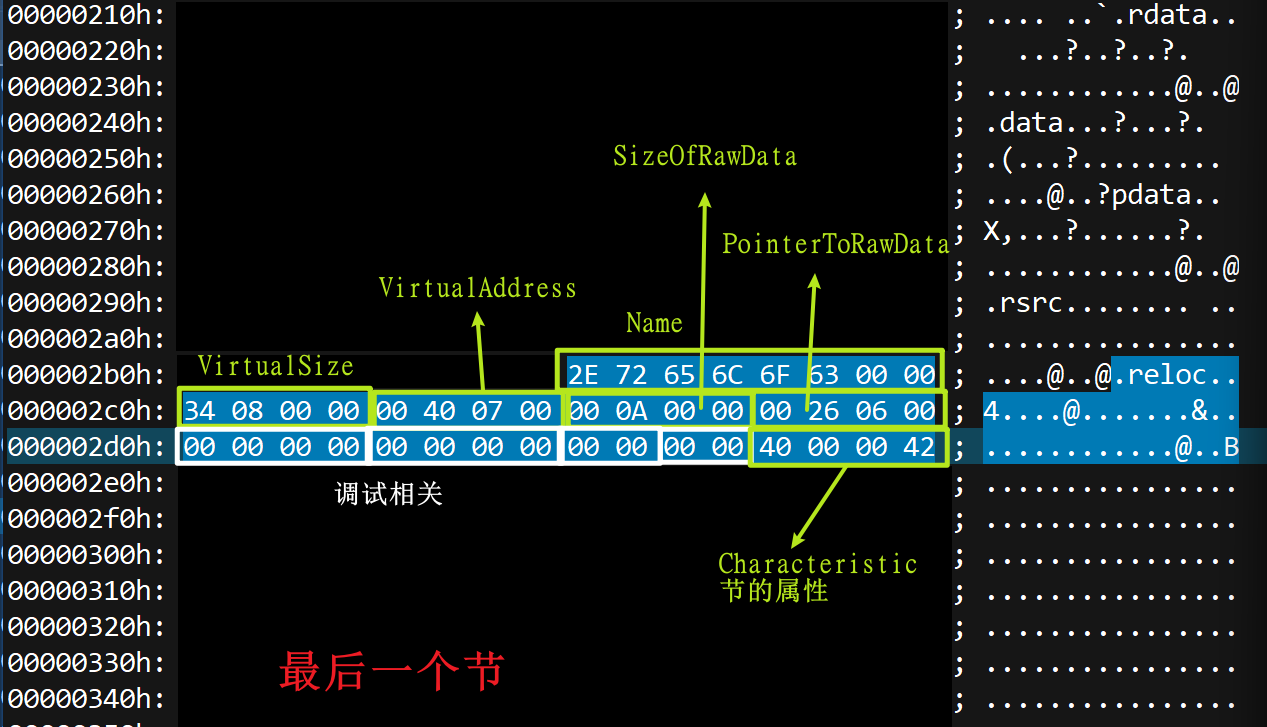
扩大节的步骤
<1> 分配一块新的空间,大小为S
<2> 将最后一个节的SizeOfRawData和VirtualSize改成N
N = (SizeOfRawData或者VirtualSize内存对齐后的值) + S SizeOPfImageData和VirtualSize谁大选谁
<3> 修改SizeOfImage大小
新增节
扩大节时可能会影响扩大的最后一个节,因为修改了该节的属性,可能从只读变成可读可写,影响代码的执行。
新增节的步骤
1 | <1> 判断是否有足够的空间,可以增加一个新节表 |
新增节
有空间新增一个节表

复制一份节表
可以复制一份.text节表,这个节表用来存储执行代码,不需要修改节的属性
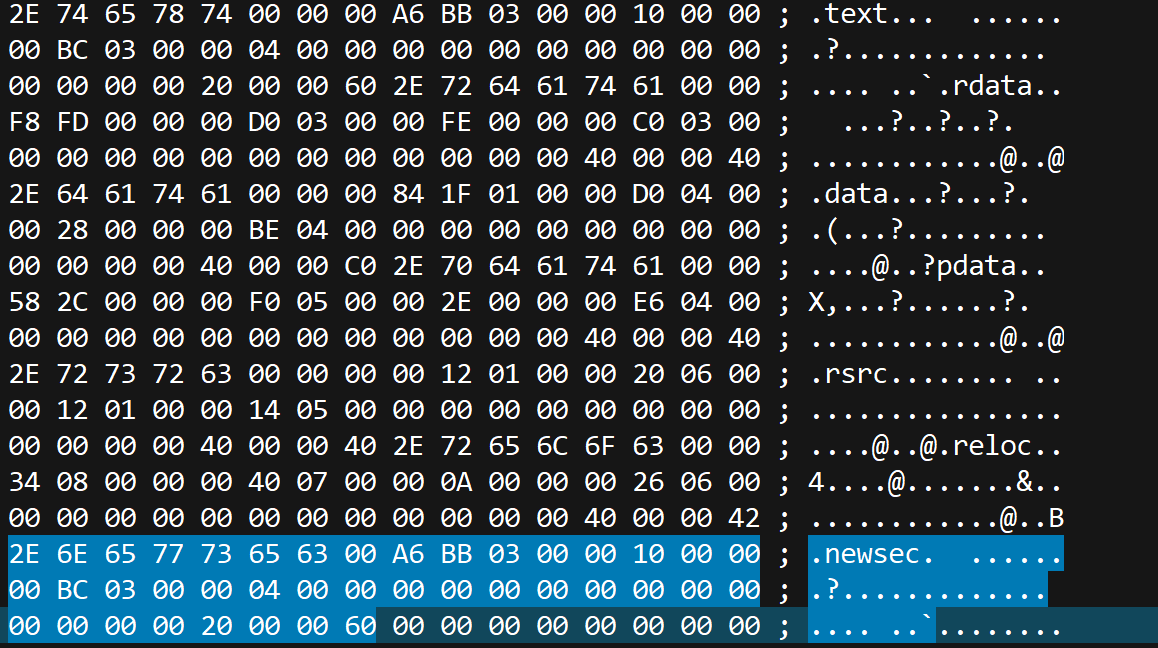
加到后面,改一个名字
在标准PE头中,第二个成员是节的数量,本来有6个节,现在加一个节,改成7

为了方便添加节,还需要修改一下最后一个节表成员的属性,将其真实大小(VirtualSize)修改成文件对齐之后的大小(SizeOfRawData):
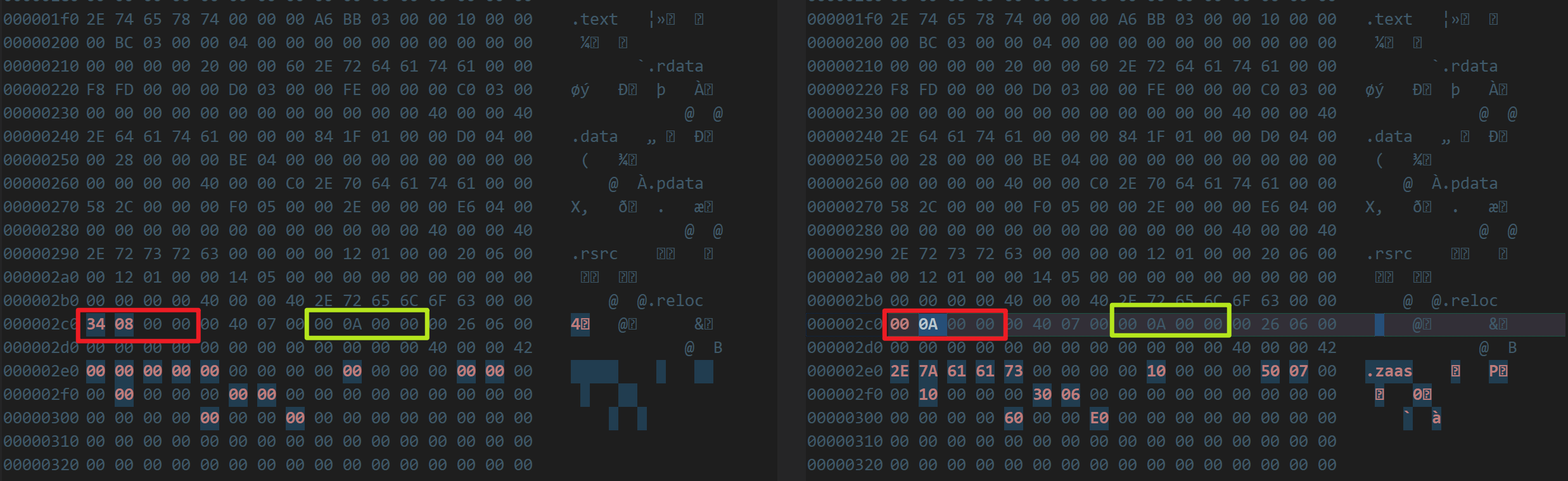
接着修改添加的节表成员的属性:名字、真实大小(0x1000)、文件对齐之后的大小(0x1000)、内存中的偏移(第4个节的偏移地址0x74000+其数据大小0x4000)、文件中的偏移:

SizeOfImage + 0x1000

然后再文件最后插入0x1000的数据即可(4096字节)
这样新增节就完成了,然后可以在新增的节中增加要执行的代码
合并节
上一章中了解到新增节需要在节表之后至少有40个字节的空白区给我们去新增,但并不是所有的程序都可以满足这个条件,如下图所示的程序在节表之后的数据是编译器填充的,这些数据并不能覆盖:
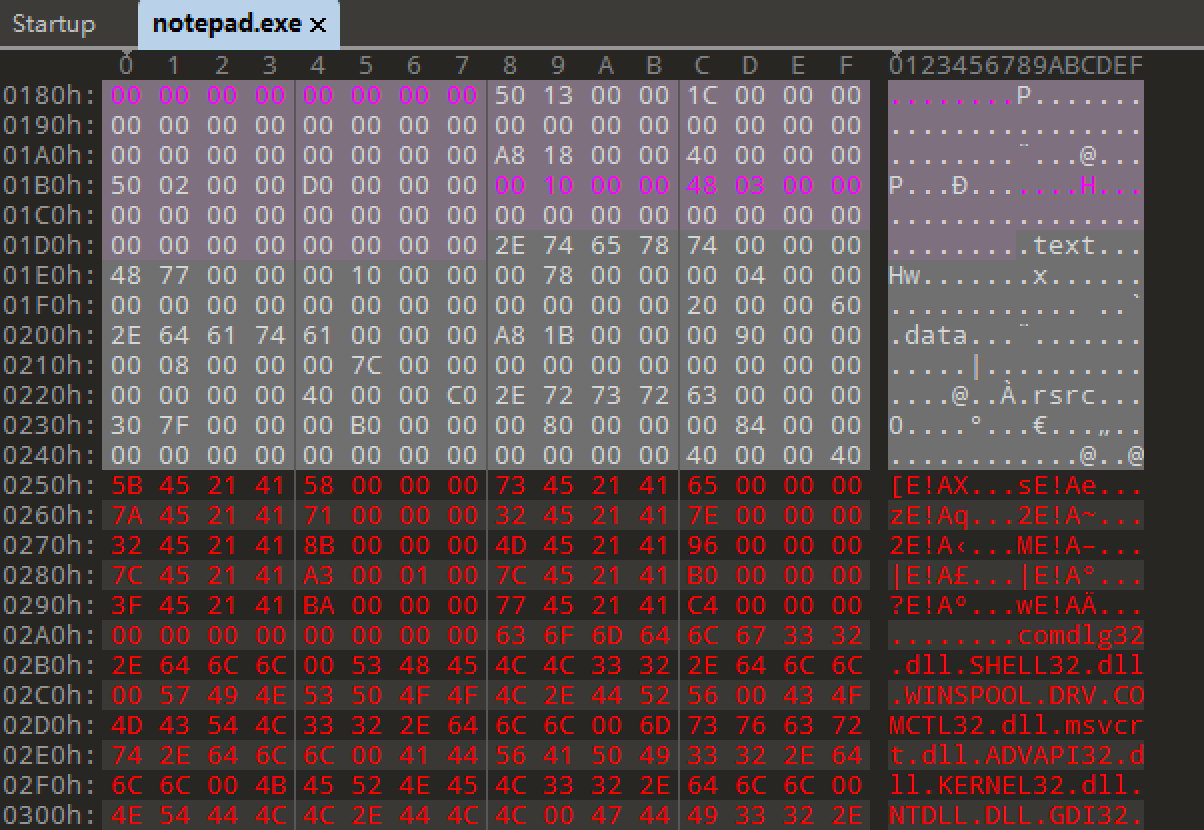
(视频看不了,见在线笔记)
导出表
一个可执行程序是由多个PE文件组成的,一个exe运行的时候,不仅有exe文件,还有一堆dll文件
exe中的导入表存储了这个程序需要用哪些dll
导出表中存储了这个PE文件中的哪些函数需要提供给别人使用。
通常情况下,exe不提供函数给别人用,也就是一般没有导出表吗,但是不代表exe不能有导出表。
dll文件通常会调用其他函数,其他的exe或dll也会调用其中的函数,所以dll一般既有导出表,也有导入表。
定位导出表
找到PE头最后一个成员结构体数组,
然后找到该结构体数组的第一个结构体,里面包含了导出表的相对虚拟地址和导出表所占大小。
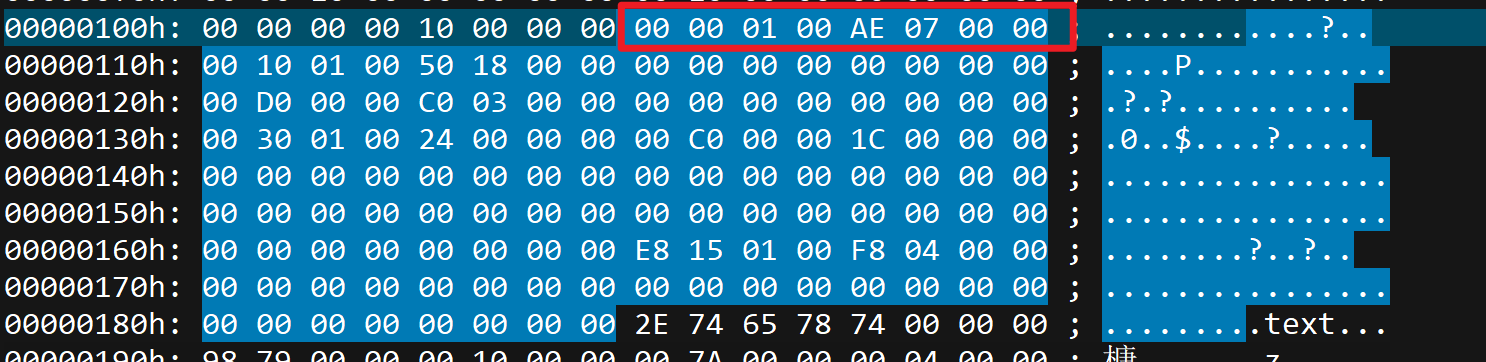
1 | VirtualAddress:0x10000 |
根据SectionAlign和FileAlign计算出导出表所在的位置
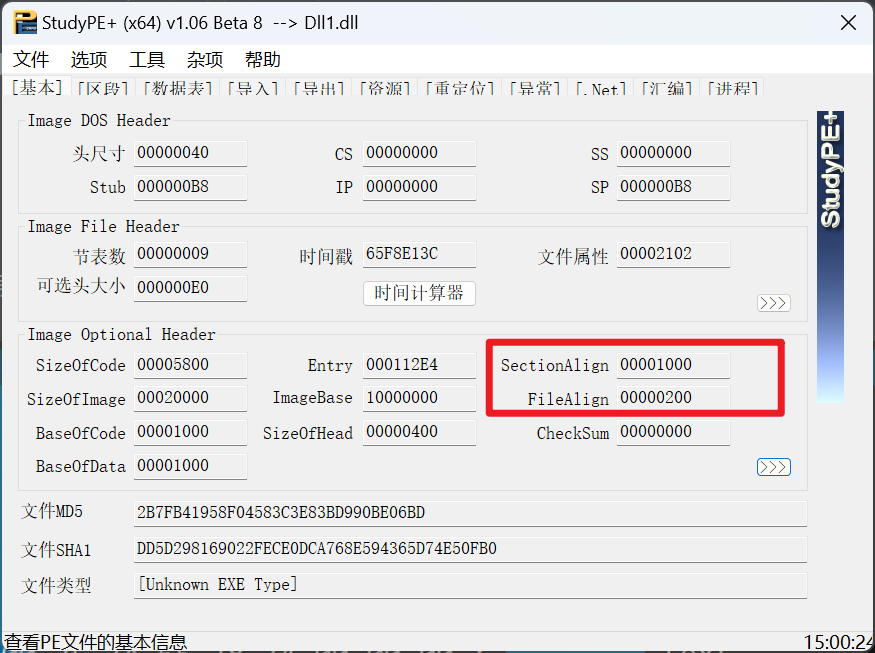
然后就能找到导出表
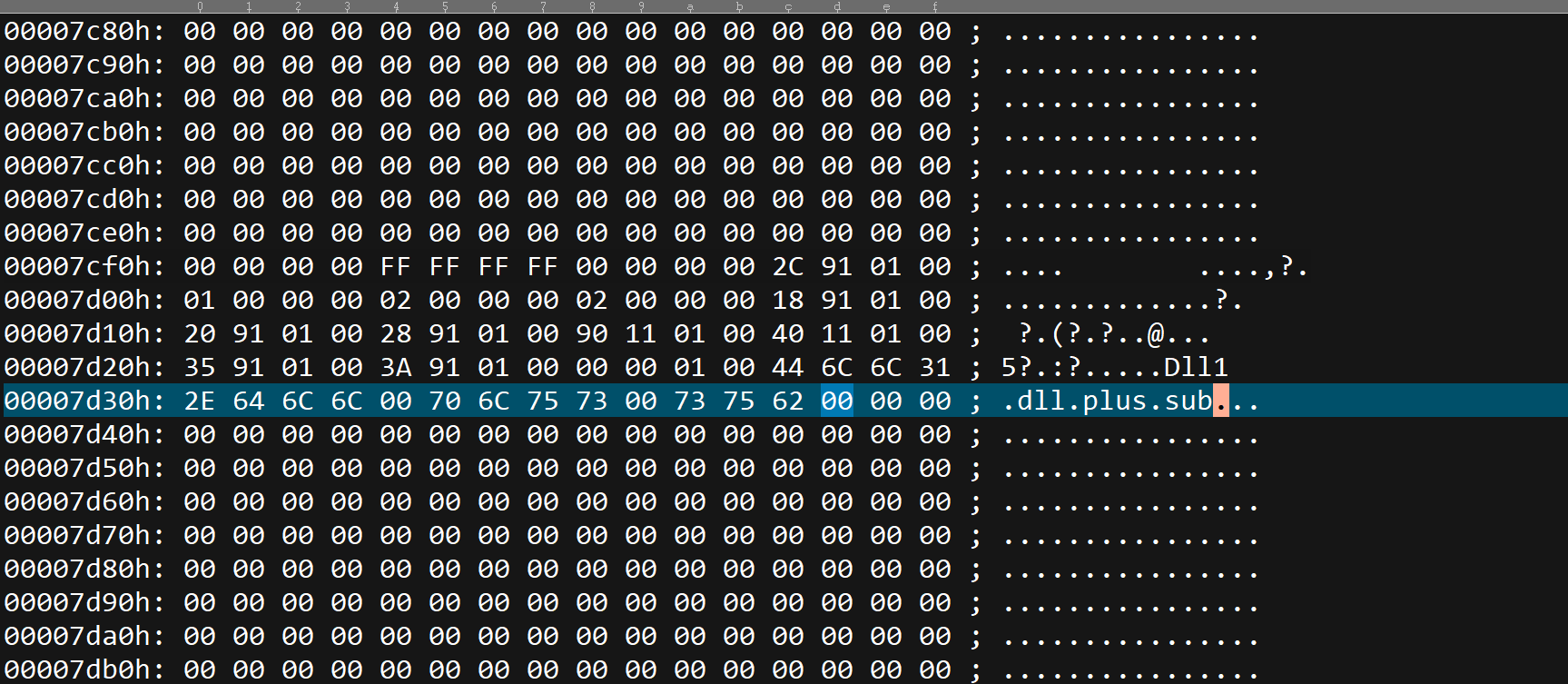
导入表
导入表——确定依赖模块
和导出表一样,找到节表上面的结构体数组,找到第二个结构体成员。
因为打开的是一个exe,所以导出表是00 00 00 00(一般)

这里存储导入表RVA和Size:RVA->0x4BB74,Size->0x64
这个exe的SectionAlign和FileAlign不相同,所以先将RVA转换成FOA
1 | SectionAlign:0x1000 |
RVA:0x4BB74 -> FOA:0x4AB74,VA:0x14004BB74

这个exe总共有4个依赖模块,最后由20个0结束。
1 | B8 C0 04 00 00 00 00 00 00 00 00 00 0A C2 04 00 E0 D4 03 00 |
以下是导入表的结构,倒数第二个成员是一个字符串,存储的是依赖模块的地址,从这个RVA地址一直找到00结束
1 | typedef struct _IMAGE_IMPORT_DESCRIPTOR { |

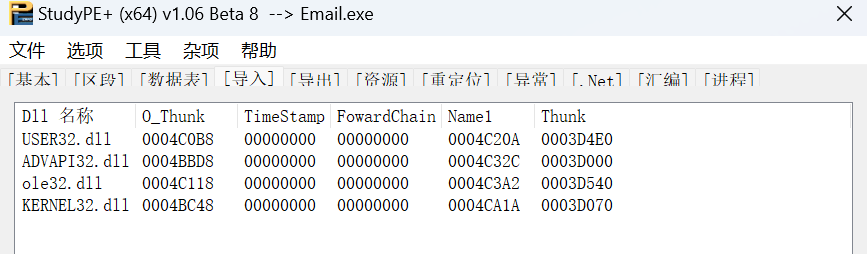
所以,第一个依赖的模块就是USER32.dll

第二个模块是ADVAPI32.dll

第三个模块是ale32.dll

第四个模块是KERNEL32.dll
导入表——确定依赖函数
在确定这个PE文件依赖那些导入表之外,还要确定这个PE文件依赖哪些函数。
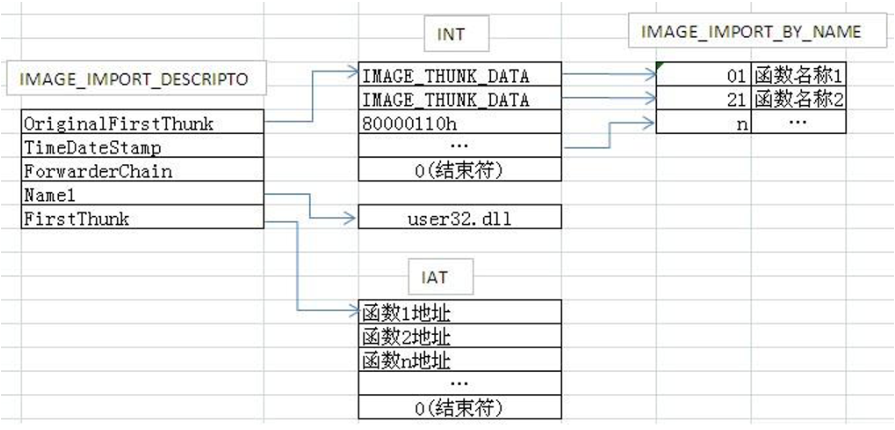
在导入表结构体中,OriginalFirstThunk指向一个INT(Import Name Table)导入名称表,FirstThunk指向一个IAT(Import Address Table)导入地址表。
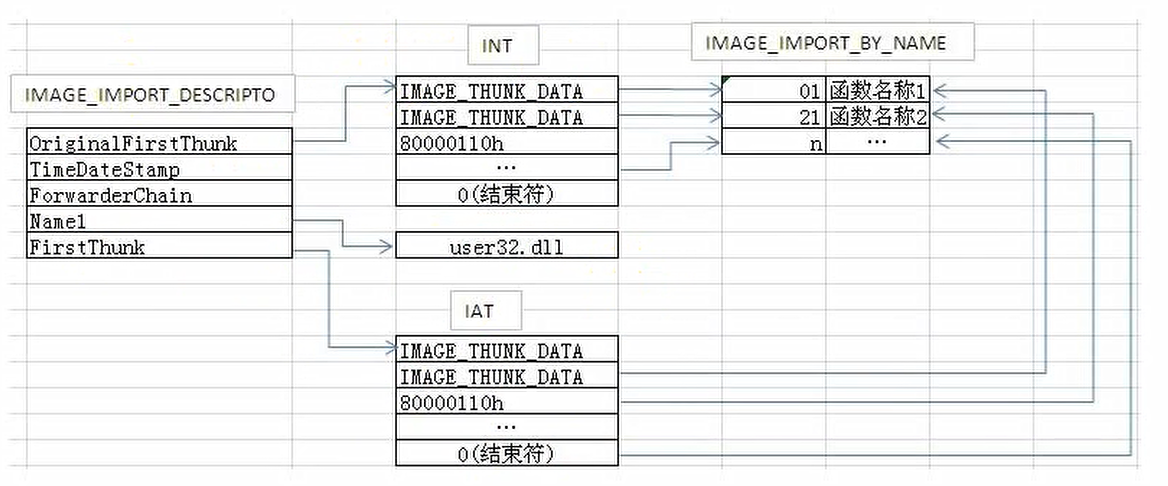
观察这两张表,这两张表指向不同的(地址不同)两张表,但是两者的内容一样。因此通过两个成员都能够找到当前所依赖模块中的函数。因此任选择一个成员去找依赖函数即可。
第一个成员指向的就是一个INT,结构体如下表,这个结构体中只有一个联合体,它的宽度就是四字节:
1 | typedef struct _IMAGE_THUNK_DATA32 { |
INT中有很多个这种结构体,他与导入表一样,当遇到与这个结构体宽度相同的一段0x00时,就代表这个表结束了。同时在这里面发现的结构体的数量就代表依赖模块的函数数量。
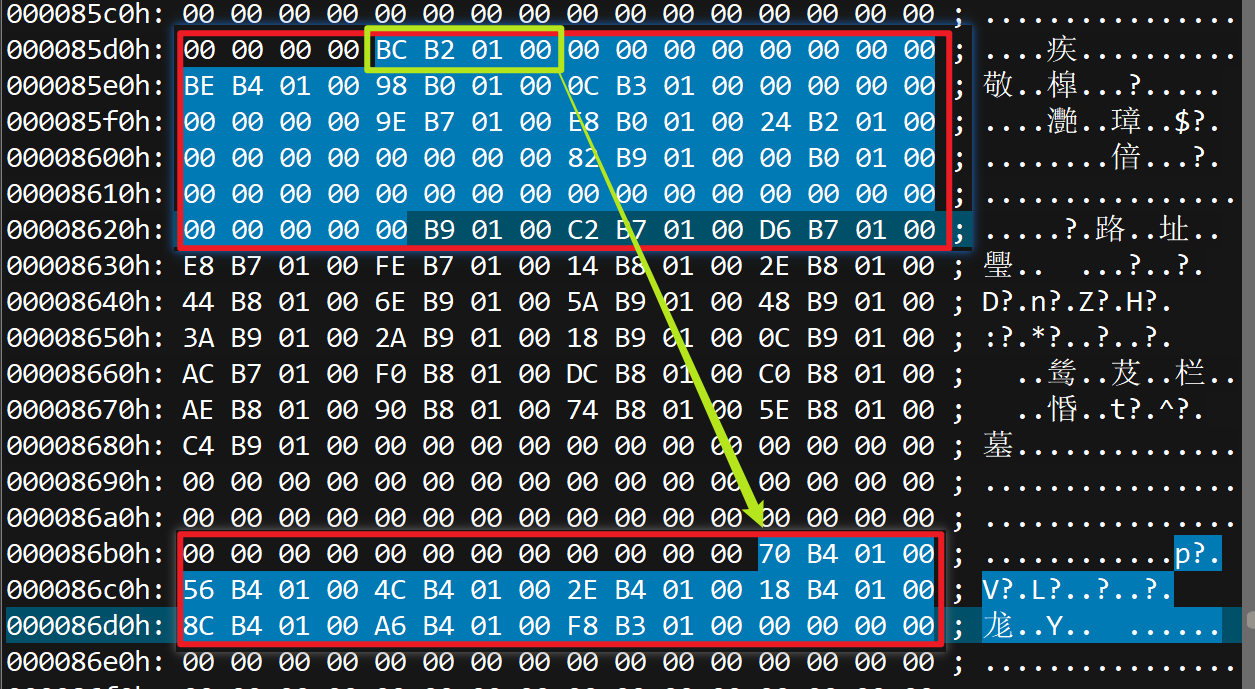
导入表——确定依赖地址
在静态PE文件中,INT和IAT两张表的结构内容是一样的:
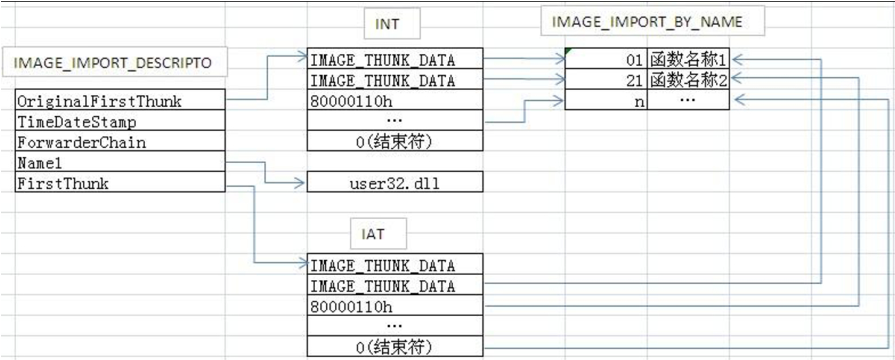
但是,当PE文件加载之后,IAT就发生了变化,它里面直接储存了函数的地址:
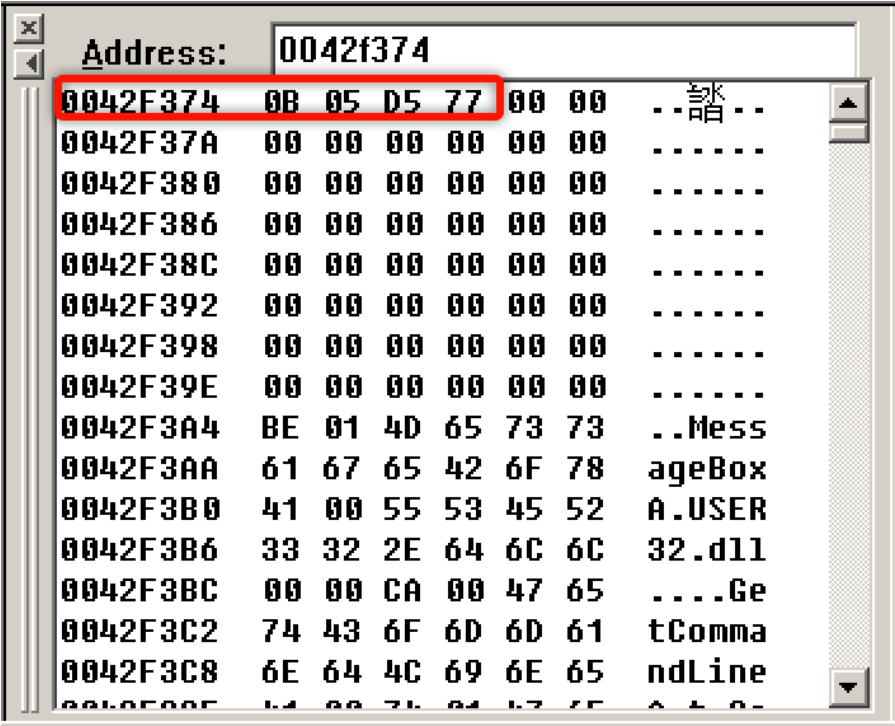
当程序在使用依赖模块的函数时,实际上是间接调用,比如调用MessageBoxA函数时,汇编指令不是直接call地址,而是从内存中找到这个地址再call:

而这一块内存就是IAT中存储的函数地址:
为什么不只留一张表:因为IAT的函数地址很有可能被修改掉,导致地址不正确,如果只有一张表的话,就没有一个正确的参照物了。
重定位表
PE文件中最重要的三张表:导出表、导入表、重定位表
假设某个PE文件使用了一些模块,这些模块都有自己的ImageBase(内存中开始的地址),但实际上在内存中模块的ImageBase被别人占用了,这时候模块就需要偏移,换一个新的内存地址去展开,假设在这个模块中有很多已经写好了的地址硬编码(但凡涉及直接寻址的指令都需要进行重定位处理),当换了地址之后就找不到了,甚至会出现安全隐患,所以硬编码的地址是需要随着偏移而去修改的,这时候就需要一张表去记录需要修正的位置,便于去根据对应偏移修正,这张表就称为重定位表;一般来说,exe文件是没有重定位表的,因为他一般不会提供函数给别人用(导出表),所以运行时它理应是第一个载入内存中的,而DLL之类的PE文件则一定是需要重定位表的,因为它并不一定会加载在ImageBase上。
当一个进程的内存空间中放进了一个A模块,占用了0x100000-0x1FFFFF的地址,但是本来B模块应该被放在这里,而这里已经被A模块占用,所以B模块只能放到A的后面,从0x200000开始。恰好B进程中有一个
x = 0x11:

这里的B模块一旦没有占住它原来的这一段内存,这里的硬编码就会失效,导致程序没法正确的给x赋值。
因此这就需要用重定位表来修正。
重定位表中要记录的就是这些需要修正的地方的地址。
所以有了重定位表,就不用担心这段程序如果没占住他的ImageBase会不会出问题
重定位表的位置信息与导入表、导出表一样,在扩展PE头最后一个成员中的第6个结构体,结构体的成员与导入表、导出表一样,分别表示重定位表的RVA和Size
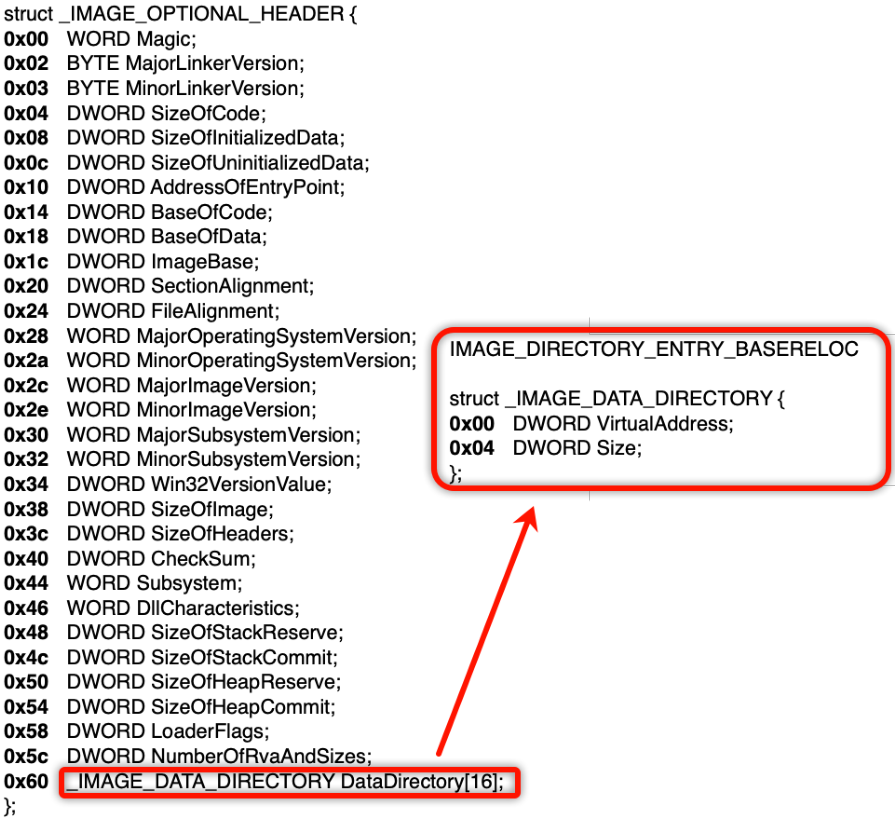
重定位表中有一个结构体,它一共有8字节:
1 | typedef struct _IMAGE_BASE_RELOCATION { |
但是完整的重定位表还包含了很多重定位项,所以整体大小是没有一个统一标准的,需要根据实际情况。该结构体的第一个成员VirtualAddress表示基地址,第二个成员SizeOfBlock也就是减去当前结构体的大小之后其他的所有重定位项加起来的大小。
这也就表示每一个重定位表是IMAGE_BASE_RELOCATION结构体开始,跟着的就是重定位项。
从理论上来说,重定位表中存储的项应该都是4字节大小的地址,但是这样一旦需要修改的地址多了,就会占用大量的空间,所以重定位表就做了一些优化,假设你现在有这几个地址需要修正:
1 | 0x800123 |
那么优化之后,IMAGE_BASE_RELOCATION结构体的第一个成员存储的就是0x800000,而这个结构体之后的每2字节存储就包含0x123、0x456、0x789,这样就大大的节省了空间。同时,这也就说明重定位表的实际大小为IMAGE_BASE_RELOCATION结构体(8字节)+N*2字节。
重定位表是按照一个物理页(4KB)进行存储的,也就表示一个4KB内存有需要修正的位置,就会有一个重定位块,一个重定位表只管自己当前的物理页的重定位。
但需要注意的是由于内存对齐的缘故,在重定位表中还是有很多的无用项的,所以需要判断当前重定位项(2字节)的高四位是否为3,如果是那么低12位就是偏移量,最后的地址也就是VirtualAddress+低12位,如果不是就表示这是无所谓的值。
PE实践
注入ShellCode
什么事ShellCode?不依赖环境,放到任何地方都可以执行的机器码。如果机器码具备这个特征,就可以称之为ShellCode。
ShellCode编写原则
<1> 不能有全局变量
<2> 不能使用常量字符串
如果ShellCode中写的是
1 | char Injstr[] = "ShellCode"; |
这样的代码在反汇编中程序会先把吧ShellCode放到常量区,然后用的时候再将这个字符串的地址复制出来。但是ShellCode不能依赖常量区,所以应该换一种方式直接将这个字符串放到堆栈中。
1 | char Injstr[] = {'S','h','e','l','l','C','o','d','e','\0'} |
这样写出来的代码在汇编中就会直接放到堆栈中,而不是放在常量区。
<3> 不能使用系统调用
解决方案:
FS:[0] -> TEB
FS:[0x30] -> PEB
找到PEB后
在找到其中的+0xc的位置,找到右边这个结构体,找到右侧这三个链表。

这样就可以通过DLL的名字找到自己想要的DLL(Unicode)
比如要找LoadLibrary或者GetProcAddress这两个函数,这两个函数时kernel32,dll里面的函数,所以要找到LoadLibrary要先找到kernel32这个dll
然后可以遍历上面这个结构体,遍历+0x24这个地方如果是kernel32.dll的话,就把+0x18这里的DllBase拿过来,就找到了kernel32.dll模块的基地址
比如LoadLibrary(“user32.dll”)得到一个句柄,这个返回的句柄就是这个模块的基地址。
所以现找TEB,再找PEB,然后找到三个链表,再遍历链表,找到kernel32.dll,找到kernel32.dll了之后还不能直接使用,还要找到这个函数在什么地方
因为PE文件有一张导出表,并且已经找到了kenel32.dll的首地址,所以通过找内存能找到kernel32的导出表,然后通过查询导出表,就能找到需要用的函数。然后只要有了LoadLibrary和GetProcAddress这两个函数,想找到其他的函数就都行了。这样就能做到在自己的函数中不依赖导入表,想用谁就用谁
<4> 不能嵌套调用其他函数
第二个和第三个其实是可以解决掉的
HOOK
什么是HOOK,HOOK是用来获取、更改程序执行时的某些数据,或者是用于更改程序执行流程的一种技术。
HOOK的两种主要形式:
1.该函数代码 -> INLINE HOOK
2.改函数地址
IAT HOOK
SSDT HOOK
IDT HOOK
EAT HOOK
IRP HOOK
……
IAT HOOK
IAT(Import Address Table)导入地址表HOOK。
比如在一个程序中有一个MessageBox,现在使用HOOK将MessageBox中的值改调,或者让这个程序在执行MessageBox的时候执行自己的一个函数,这时候就用IAT HOOK。
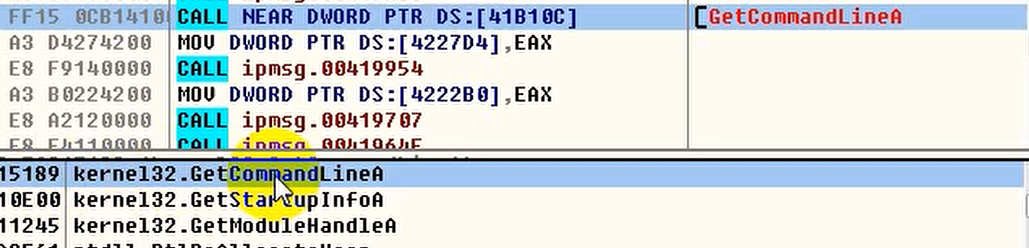
比如这样一个间接调用,call后面跟的是一个ptr,一块内存。此时可以HOOK将这个内存地址中存储的函数地址改成自己函数的地址。
IAT HOOK步骤:
1 | 1、在Dll里构造Detour函数(也就是我们自己的函数) |
INLINE HOOK
IAT Hook缺点:
<1> 容易被检测到
<2> 只能Hook IAT表里面的函数 -> 有50个WindowsAPI的函数,还有50个自己写的函数,这些自己写的函数就没法Hook,因为自己写的函数在IAT表中是没有的。
INLINE HOOK就是直接修改exe的硬编码。
比如现在有一个程序:
1 |
|
通过Hook修改plus()函数执行时,堆栈中的值。使2+3= 5。
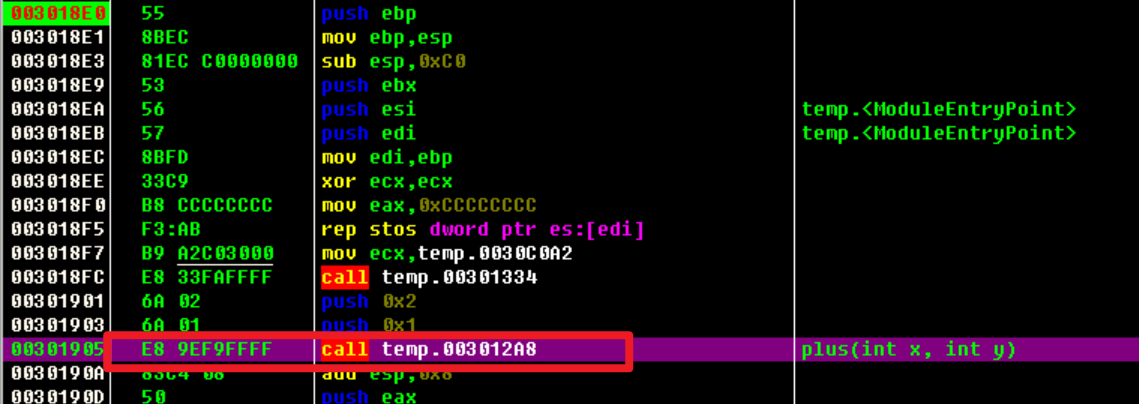
从这个call开始修改,让这里先jmp到0x30194A这里,执行自己的代码
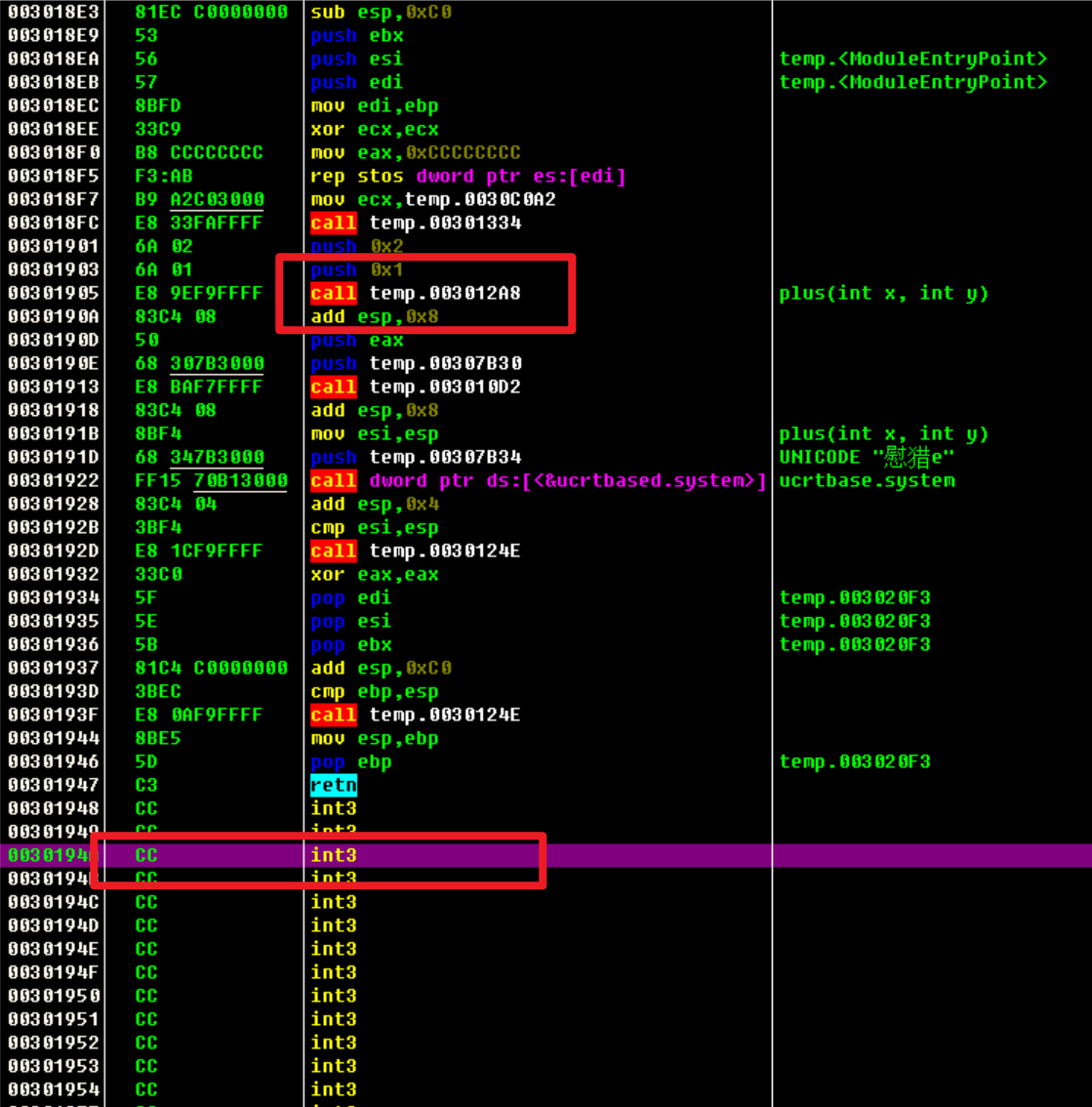
有三个字节没有被占用,所以用nop填充
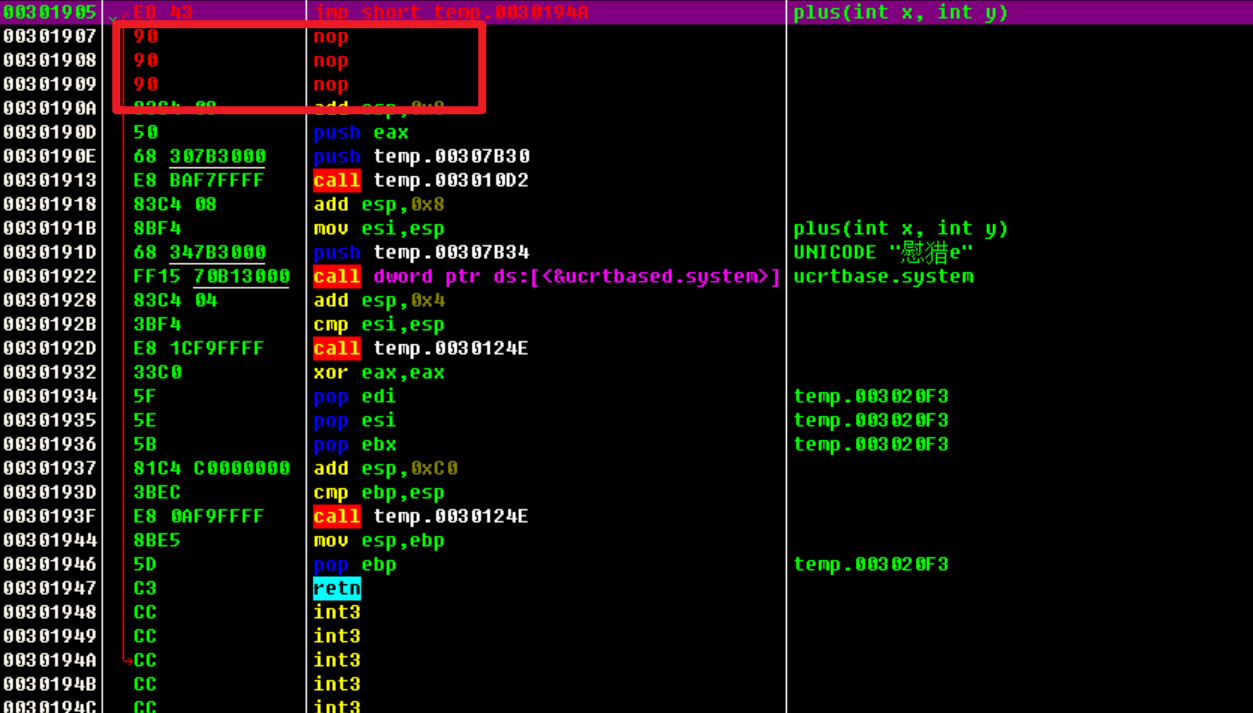
因为jmp跳转之后不会改变esp的值,所以跳完之后直接esp和esp+0x4直接找到两个push进来的值,直接对这两个值进行修改。
修改两个值:
因为本来覆盖了一句汇编call 0xxxxxxx所以在这里要把它先填回来。
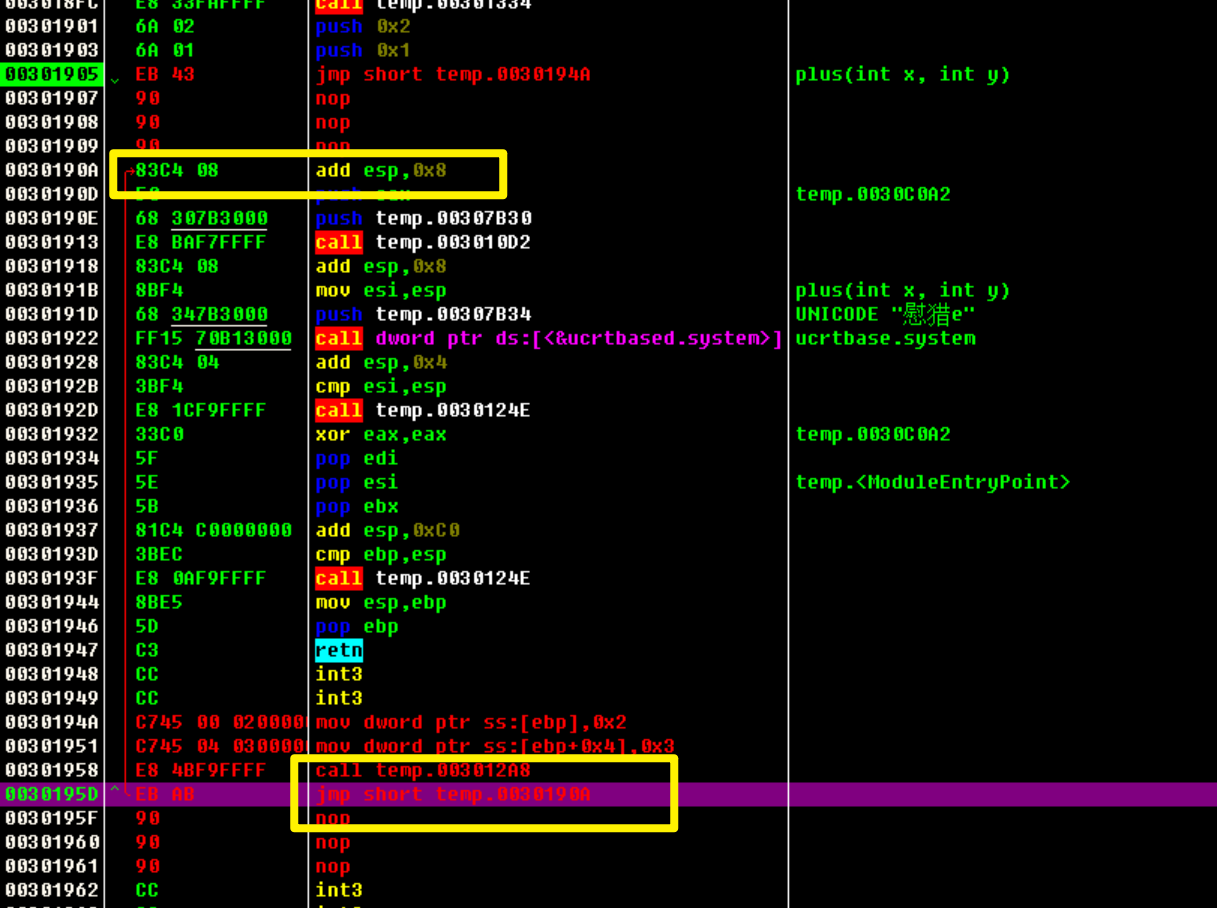
修改完之后再jmp执行回来。
最终改完就是这样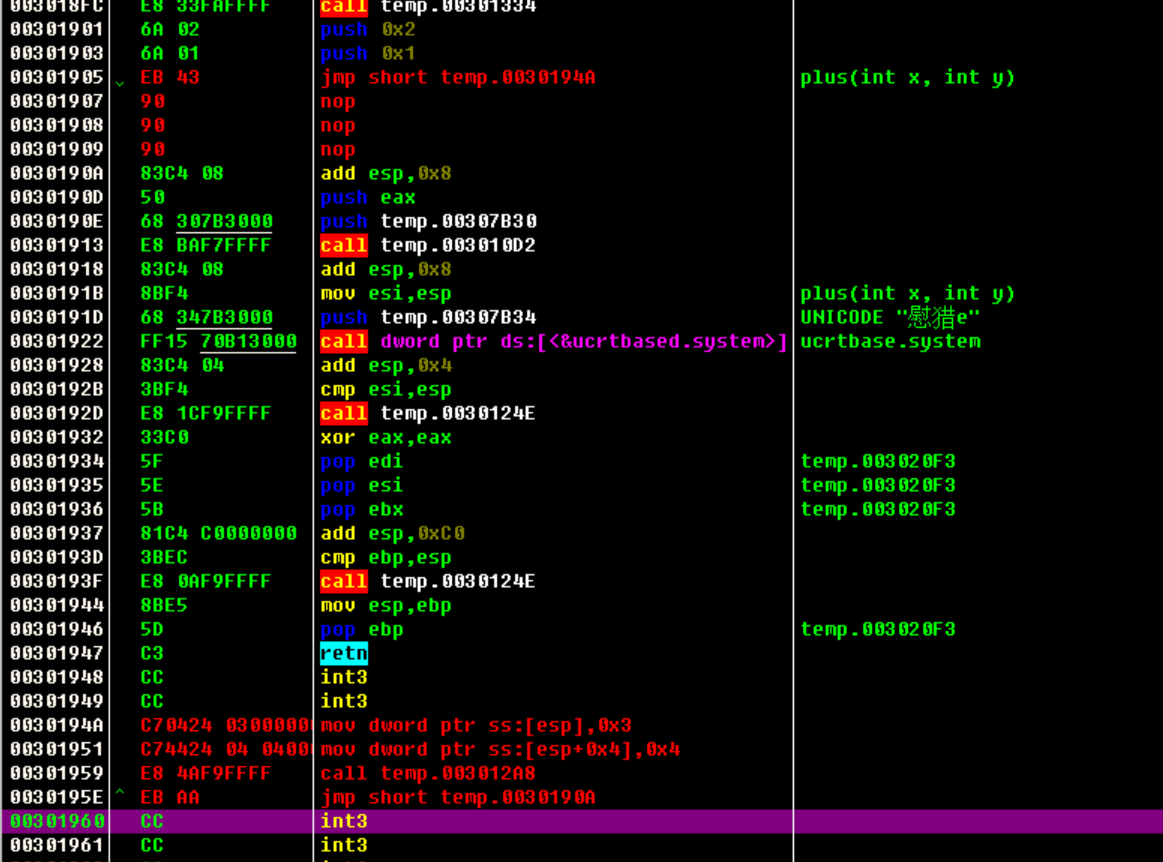
执行完后,堆栈中变成了0x3和0x4
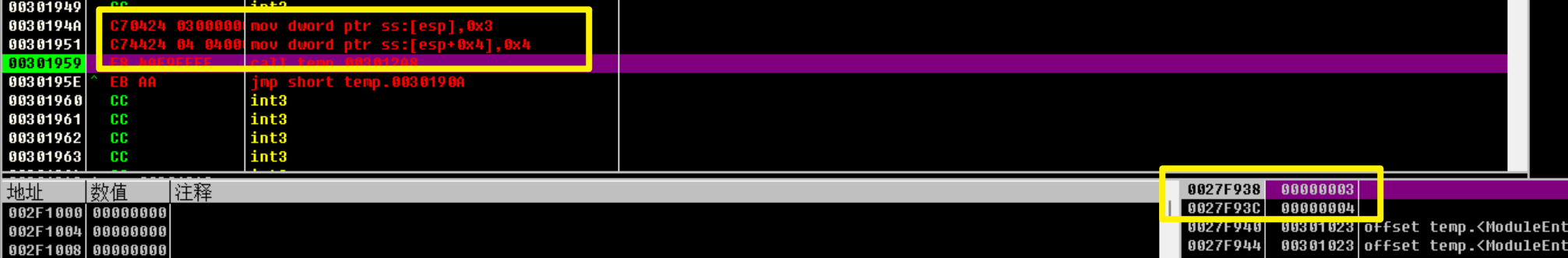
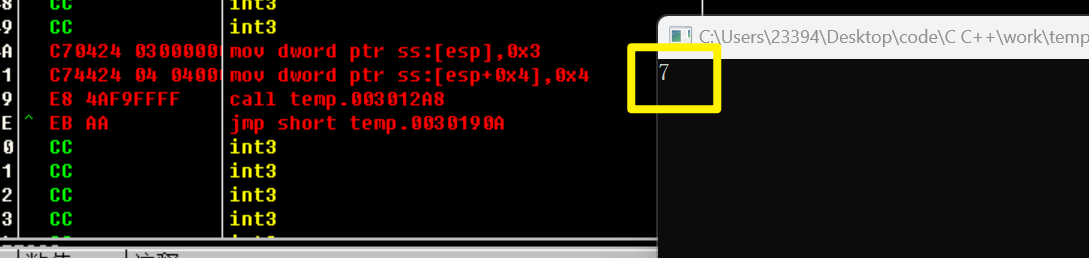
执行后就是0x7
原理是这样,需要用代码来实现。
还是以MessageBoxA来举例。这里HookMessageBoxA这个函数
代码如下:
1 |
|
再比如hook修改MessageBoxA的标题:
MessageBoxA在设置窗口标题时会使用SetWindowTextA这个API函数,可以通过Hook这个函数,并修改这个函数调用时的值,从而实现指定窗口的标题,
代码实现:
1 |
|
C/C++ Inline Hook 钩子编写技巧 - lyshark - 博客园 (cnblogs.com)
INLINE HOOK 改进版
当自己需要写的函数非常复杂的时候,比如想要打印一个字符串,这时候用纯汇编自己编写就非常复杂。所以采用调用函数的方法。
1 | void MyMessageBox(HWND hwnd, LPCSTR lpText, LPCSTR lpCaption, UINT uType) |
INLINE HOOK检测
过E9检测,因为在INLINE Hook中一般使用jmp跳转到某个指定的地方来执行自己的指令,而jmp的机器码就是E9,所以可以改为使用CALL + RET的方法避免E9的检测,不过这也只是最简单的一种检测的攻防。
HOOK攻防
HOOK攻防常用手段
阶段一:
(防)检测JMP(E9)、检测跳转范围
(破)绕
阶段二:
(防)写一个进程,对自己的代码进行全代码校验、CRC校验
(破)修改监测代码、挂起检测函数
阶段三:进程A检测进程B,进程B检测进程C,进程C检测进程D,进程D进行全代码校验。
(防)先对相关API全代码校验,多个线程互相检测,并检测线程是否在活动中
(破)使用瞬时钩子/硬件钩子