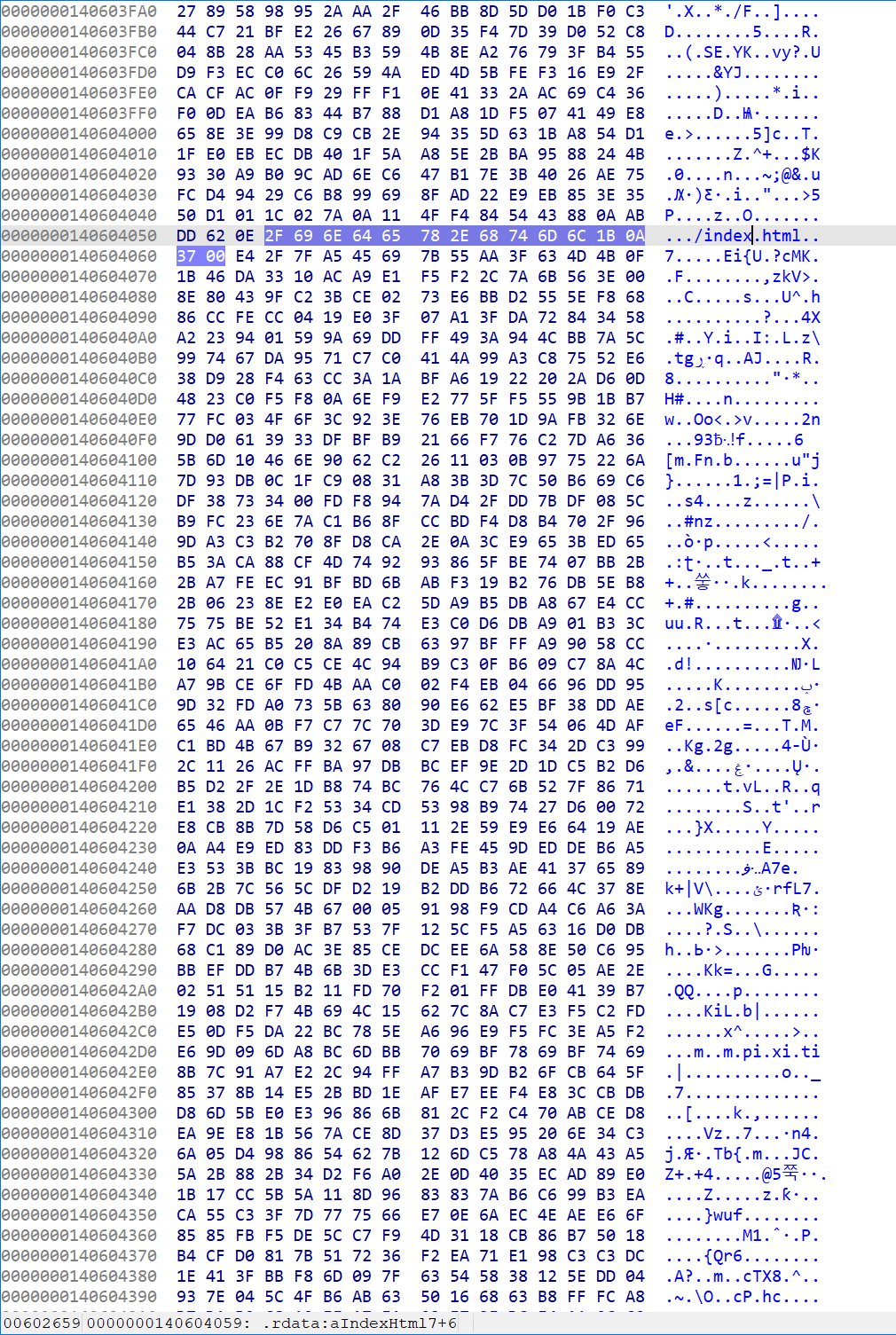
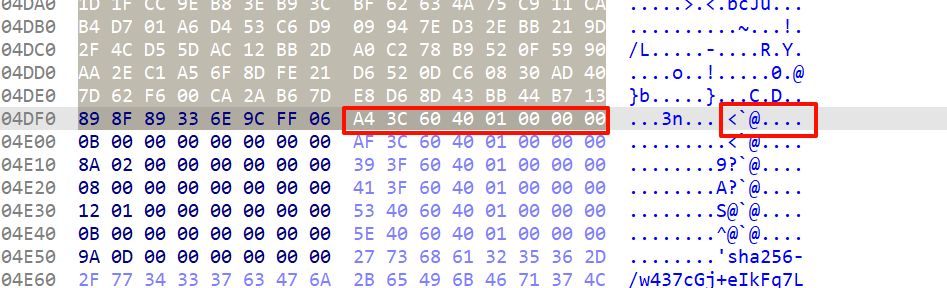
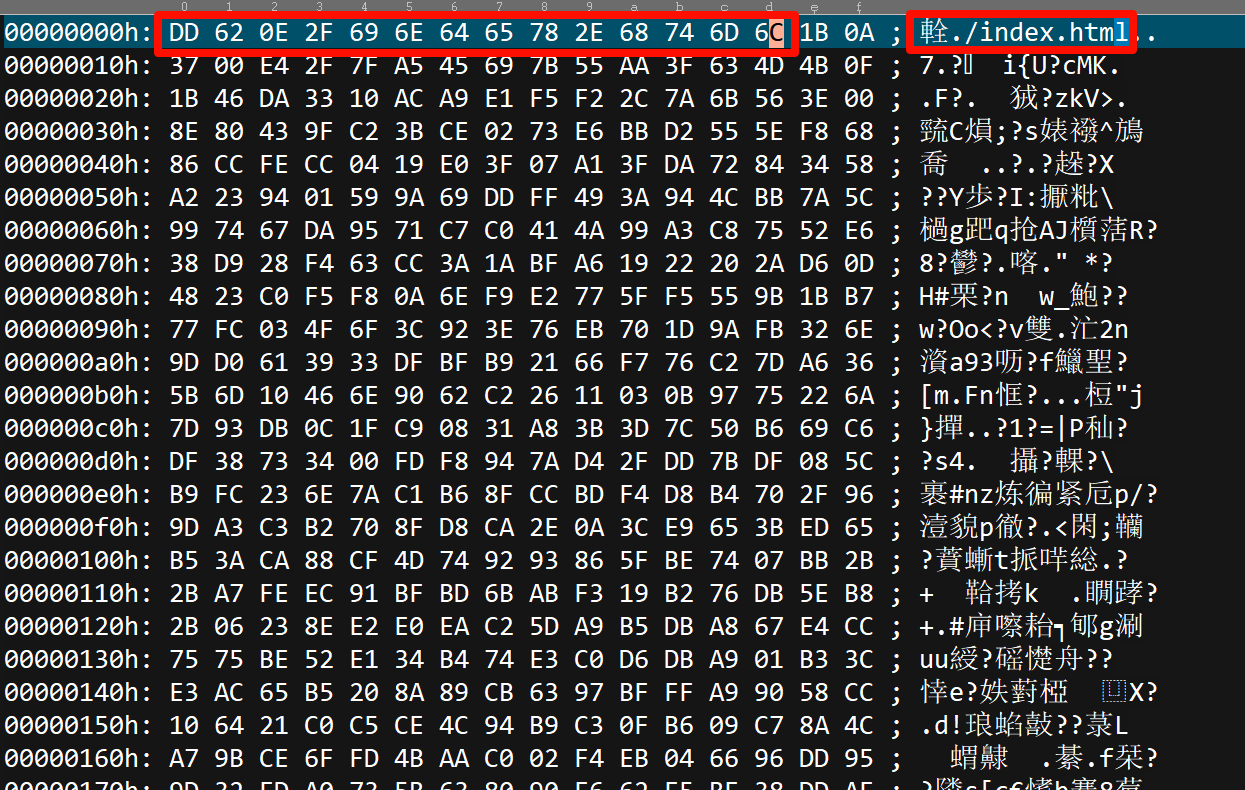
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
|
import brotli
import sys
import argparse
import os
import struct
from typing import List, Tuple, Optional
class PEParser:
"""简单的PE文件解析器,用于提取.rdata段"""
def __init__(self, file_path: str):
self.file_path = file_path
self.sections = []
def parse(self) -> bool:
"""解析PE文件结构"""
try:
with open(self.file_path, 'rb') as f:
dos_header = f.read(64)
if dos_header[:2] != b'MZ':
print("错误: 不是有效的PE文件 (缺少MZ签名)")
return False
pe_offset = struct.unpack('<I', dos_header[60:64])[0]
f.seek(pe_offset)
pe_signature = f.read(4)
if pe_signature != b'PE\x00\x00':
print("错误: 不是有效的PE文件 (缺少PE签名)")
return False
coff_header = f.read(20)
machine, num_sections, timestamp, ptr_to_sym, num_symbols, opt_header_size, characteristics = struct.unpack('<HHIIIHH', coff_header)
f.seek(pe_offset + 24 + opt_header_size)
for i in range(num_sections):
section_header = f.read(40)
if len(section_header) < 40:
break
name = section_header[:8].rstrip(b'\x00').decode('ascii', errors='ignore')
virtual_size, virtual_address, size_of_raw_data, ptr_to_raw_data = struct.unpack('<IIII', section_header[8:24])
self.sections.append({
'name': name,
'virtual_size': virtual_size,
'virtual_address': virtual_address,
'size_of_raw_data': size_of_raw_data,
'ptr_to_raw_data': ptr_to_raw_data
})
print(f"成功解析PE文件,找到 {len(self.sections)} 个节:")
for section in self.sections:
print(f" {section['name']:10} - 大小: {section['size_of_raw_data']:8} 字节, 偏移: 0x{section['ptr_to_raw_data']:08x}")
return True
except Exception as e:
print(f"解析PE文件时出错: {e}")
return False
def get_rdata_section(self) -> Optional[Tuple[int, int]]:
"""获取.rdata段的偏移和大小"""
for section in self.sections:
if section['name'].lower() == '.rdata':
return section['ptr_to_raw_data'], section['size_of_raw_data']
return None
def extract_rdata(self) -> Optional[bytes]:
"""提取.rdata段的数据"""
rdata_info = self.get_rdata_section()
if rdata_info is None:
print("错误: 未找到.rdata段")
return None
offset, size = rdata_info
try:
with open(self.file_path, 'rb') as f:
f.seek(offset)
rdata = f.read(size)
print(f"成功提取.rdata段: 偏移 0x{offset:08x}, 大小 {size} 字节")
return rdata
except Exception as e:
print(f"提取.rdata段时出错: {e}")
return None
def find_all_brotli_segments(data: bytes, min_size: int = 10, max_scan: int = 10000,
data_offset: int = 0) -> List[Tuple[bytes, int, int]]:
"""
在二进制数据中查找所有可能的brotli压缩段
Args:
data: 原始字节数据
min_size: brotli段的最小大小
max_scan: 最大扫描长度(避免过长搜索)
data_offset: 数据在原文件中的偏移量(用于显示正确的文件位置)
Returns:
list: [(解压后的数据, 开始位置, 结束位置), ...]
"""
found_segments = []
data_len = len(data)
print(f"开始扫描 {data_len} 字节的数据...")
print(f"最小段大小: {min_size}, 最大扫描长度: {max_scan}")
if data_offset > 0:
print(f"数据偏移: 0x{data_offset:08x}")
for start_pos in range(data_len - min_size):
if start_pos % 1000 == 0:
print(f"扫描进度: {start_pos}/{data_len} ({start_pos/data_len*100:.1f}%)", end='\r')
max_end = min(start_pos + max_scan, data_len)
for end_pos in range(start_pos + min_size, max_end + 1):
try:
candidate = data[start_pos:end_pos]
decompressed = brotli.decompress(candidate)
is_overlapping = False
for _, existing_start, existing_end in found_segments:
if not (end_pos <= existing_start or start_pos >= existing_end):
is_overlapping = True
break
if not is_overlapping:
abs_start = data_offset + start_pos
abs_end = data_offset + end_pos
found_segments.append((decompressed, abs_start, abs_end))
print(f"\n找到brotli段 #{len(found_segments)}: 位置 0x{abs_start:08x}-0x{abs_end:08x} (长度:{abs_end-abs_start}), 解压后:{len(decompressed)}字节")
start_pos = end_pos - 1
break
except Exception:
continue
print(f"\n扫描完成! 总共找到 {len(found_segments)} 个brotli段")
return found_segments
def extract_multiple_brotli(file_path: str, output_dir: str = None, min_size: int = 10,
max_scan: int = 10000, save_raw: bool = False,
scan_rdata: bool = False) -> bool:
"""
从文件中提取所有brotli段
Args:
file_path: 输入文件路径
output_dir: 输出目录
min_size: 最小brotli段大小
max_scan: 最大扫描长度
save_raw: 是否保存原始压缩数据
scan_rdata: 是否只扫描PE文件的.rdata段
Returns:
bool: 是否成功
"""
try:
print(f"读取文件: {file_path}")
data_offset = 0
if scan_rdata:
print("模式: 扫描PE文件的.rdata段")
parser = PEParser(file_path)
if not parser.parse():
return False
data = parser.extract_rdata()
if data is None:
return False
rdata_info = parser.get_rdata_section()
if rdata_info:
data_offset = rdata_info[0]
else:
print("模式: 扫描整个二进制文件")
with open(file_path, 'rb') as f:
data = f.read()
print(f"数据大小: {len(data)} 字节")
if output_dir is None:
base_name = os.path.splitext(os.path.basename(file_path))[0]
suffix = "_rdata_extracted" if scan_rdata else "_extracted"
output_dir = f"{base_name}{suffix}"
os.makedirs(output_dir, exist_ok=True)
print(f"输出目录: {output_dir}")
segments = find_all_brotli_segments(data, min_size, max_scan, data_offset)
if not segments:
print("未找到任何brotli压缩段")
return False
for i, (decompressed_data, start_pos, end_pos) in enumerate(segments, 1):
decompressed_file = os.path.join(output_dir, f"segment_{i:03d}_decompressed.dat")
with open(decompressed_file, 'wb') as f:
f.write(decompressed_data)
print(f"段 {i}: 位置 0x{start_pos:08x}-0x{end_pos:08x}, 原始:{end_pos-start_pos:6d}字节, 解压:{len(decompressed_data):6d}字节")
print(f" 解压数据保存到: {decompressed_file}")
if save_raw:
raw_file = os.path.join(output_dir, f"segment_{i:03d}_raw.br")
with open(file_path, 'rb') as f:
f.seek(start_pos)
raw_data = f.read(end_pos - start_pos)
with open(raw_file, 'wb') as f:
f.write(raw_data)
print(f" 原始数据保存到: {raw_file}")
try:
if len(decompressed_data) > 0:
try:
preview = decompressed_data.decode('utf-8')[:100]
print(f" 内容预览: {repr(preview)}{'...' if len(decompressed_data) > 100 else ''}")
except UnicodeDecodeError:
hex_preview = decompressed_data[:20].hex()
print(f" 十六进制预览: {hex_preview}{'...' if len(decompressed_data) > 20 else ''}")
except Exception:
pass
print()
summary_file = os.path.join(output_dir, "extraction_summary.txt")
with open(summary_file, 'w', encoding='utf-8') as f:
f.write(f"Brotli提取摘要\n")
f.write(f"================\n")
f.write(f"源文件: {file_path}\n")
f.write(f"扫描模式: {'PE .rdata段' if scan_rdata else '整个文件'}\n")
f.write(f"数据大小: {len(data)} 字节\n")
if scan_rdata and data_offset > 0:
f.write(f".rdata段偏移: 0x{data_offset:08x}\n")
f.write(f"找到段数: {len(segments)}\n")
f.write(f"扫描参数: 最小大小={min_size}, 最大扫描长度={max_scan}\n\n")
for i, (decompressed_data, start_pos, end_pos) in enumerate(segments, 1):
f.write(f"段 {i}:\n")
f.write(f" 位置: 0x{start_pos:08x} - 0x{end_pos:08x}\n")
f.write(f" 原始大小: {end_pos - start_pos} 字节\n")
f.write(f" 解压大小: {len(decompressed_data)} 字节\n")
f.write(f" 压缩比: {len(decompressed_data)/(end_pos-start_pos):.2f}x\n")
f.write(f" 解压文件: segment_{i:03d}_decompressed.dat\n")
if save_raw:
f.write(f" 原始文件: segment_{i:03d}_raw.br\n")
f.write("\n")
print(f"提取摘要保存到: {summary_file}")
print(f"\n总计提取了 {len(segments)} 个brotli段")
return True
except FileNotFoundError:
print(f"错误: 文件 '{file_path}' 不存在")
return False
except Exception as e:
print(f"错误: {e}")
return False
def main():
parser = argparse.ArgumentParser(
description='从二进制文件中提取所有brotli压缩段',
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog='''
使用示例:
# 扫描整个文件
python multi_brotli_extractor.py file.bin
# 只扫描PE文件的.rdata段
python multi_brotli_extractor.py program.exe --scan-rdata
# 自定义参数
python multi_brotli_extractor.py file.bin --output-dir extracted --save-raw --min-size 50
'''
)
parser.add_argument('input_file', help='输入的二进制文件路径')
parser.add_argument('--output-dir', '-o', type=str,
help='输出目录路径 (默认: {filename}_extracted)')
parser.add_argument('--min-size', '-m', type=int, default=10,
help='brotli段的最小大小 (默认: 10)')
parser.add_argument('--max-scan', '-s', type=int, default=10000,
help='单个段的最大扫描长度 (默认: 10000)')
parser.add_argument('--save-raw', '-r', action='store_true',
help='同时保存原始压缩数据')
parser.add_argument('--scan-rdata', action='store_true',
help='只扫描PE文件的.rdata段')
parser.add_argument('--quiet', '-q', action='store_true',
help='减少输出信息')
args = parser.parse_args()
if args.quiet:
import os
sys.stdout = open(os.devnull, 'w')
success = extract_multiple_brotli(
args.input_file,
args.output_dir,
args.min_size,
args.max_scan,
args.save_raw,
args.scan_rdata
)
if args.quiet:
sys.stdout = sys.__stdout__
sys.exit(0 if success else 1)
if __name__ == '__main__':
main()
|